Introduction

Neo4j 3.0 introduced the concept of user defined procedures. Those are custom implementations of certain functionality, that can’t be (easily) expressed in Cypher itself. Those procedures are implemented in Java and can be easily deployed into your Neo4j instance, and then be called from Cypher directly.
The APOC library consists of many (about 300) procedures to help with many different tasks in areas like data integration, graph algorithms or data conversion.
License
Apache License 2.0
"APOC" Name history
Apoc was the technician and driver on board of the Nebuchadnezzar in the Matrix movie. He was killed by Cypher.
APOC was also the first bundled A Package Of Components for Neo4j in 2009.
APOC also stands for "Awesome Procedures On Cypher"
Installation
Download latest release
Go to http://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/3.1.3.9
to find the latest release and download the binary jar to place into your $NEO4J_HOME/plugins folder.
|
Note
|
For Neo4j Desktop the plugins directory is in a different place, put the jar-file into these (make sure to replace all at upgrade).
See the Neo4j Manual for more detail about the install locations.
|
-
OSX:
/Applications/Neo4j\ Community\ Edition\ <version>.app/Contents/Resources/app/pluginsAND/Users/<user>/Documents/Neo4j/default.graphdb/plugins -
Windows:
C:\Program Files\Neo4j CE <version>\plugins
Version Compatibility Matrix
Since APOC relies in some places on Neo4j’s internal APIs you need to use the right APOC version for your Neo4j installaton.
Any version to be released after 1.1.0 will use a different, consistent versioning scheme: <neo4j-version>.<apoc> version. The trailing <apoc> part of the version number will be incremented with every apoc release.
apoc version |
neo4j version |
3.2.2 (3.2.x) |
|
3.2.0 |
|
3.1.5 (3.1.x) |
|
3.1.4 |
|
3.1.2 |
|
3.1.0-3.1.1 |
|
3.0.5-3.0.9 (3.0.x) |
|
3.0.4.3 |
3.0.4 |
1.1.0 |
3.0.0 - 3.0.3 |
1.0.0 |
3.0.0 - 3.0.3 |
using APOC with Neo4j Docker image
The Neo4j Docker image allows to supply a volume for the /plugins folder. Download the APOC release fitting your Neo4j version to local folder plugins and provide it as a data volume:
mkdir plugins
pushd plugins
wget https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/3.1.3.9/apoc-3.1.3.9-all.jar
popd
docker run --rm -e NEO4J_AUTH=none -p 7474:7474 -v $PWD/plugins:/plugins -p 7687:7687 neo4j:3.1.6Build & install the current development branch from source
git clone http://github.com/neo4j-contrib/neo4j-apoc-procedures ./gradlew shadow cp build/libs/apoc-<version>-SNAPSHOT-all.jar $NEO4J_HOME/plugins/ $NEO4J_HOME/bin/neo4j restart
A full build including running the tests can be run by ./gradlew build.
Calling Procedures & Functions within Cypher
User defined Functions can be used in any expression or predicate, just like built-in functions.
Procedures can be called stand-alone with CALL procedure.name();
But you can also integrate them into your Cypher statements which makes them so much more powerful.
WITH 'https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/person.json' AS url
CALL apoc.load.json(url) YIELD value as person
MERGE (p:Person {name:person.name})
ON CREATE SET p.age = person.age, p.children = size(person.children)Procedure & Function Signatures
To call procedures correctly, you need to know their parameter names, types and positions. And for YIELDing their results, you have to know the output column names and types.
INFO: The signatures are shown in error messages, if you use a procedure incorrectly.
You can see the procedures signature in the output of CALL apoc.help("name") (which itself uses CALL dbms.procedures() and CALL dbms.functions())
CALL apoc.help("dijkstra")The signature is always name : : TYPE, so in this case:
apoc.algo.dijkstra (startNode :: NODE?, endNode :: NODE?, relationshipTypesAndDirections :: STRING?, weightPropertyName :: STRING?) :: (path :: PATH?, weight :: FLOAT?)
| Name | Type |
|---|---|
Procedure Parameters |
|
|
|
|
|
|
|
|
|
Output Return Columns |
|
|
|
|
|
Help and Usage
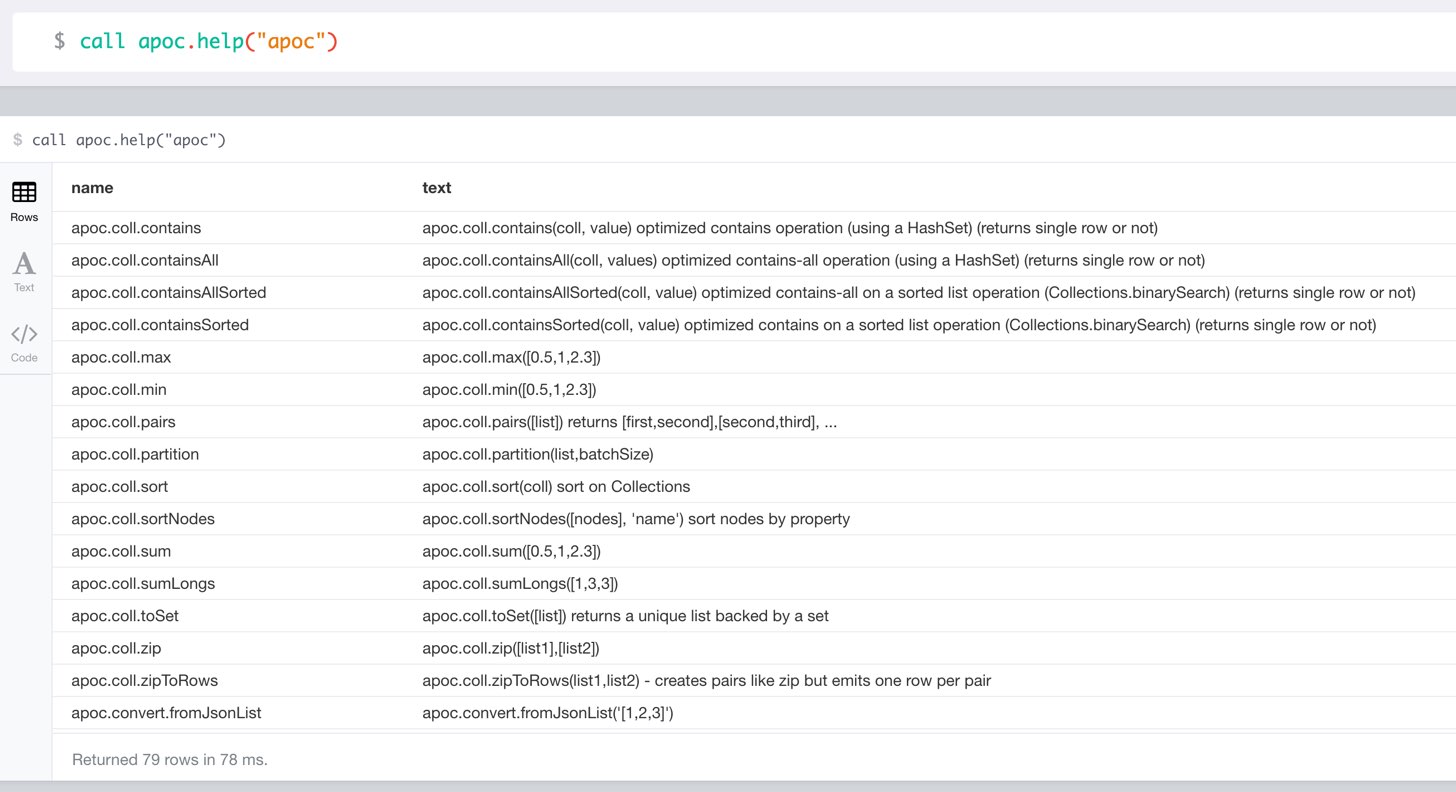
|
lists name, description-text and if the procedure performs writes, search string is checked against beginning (package) or end (name) of procedure |
CALL apoc.help("apoc") YIELD name, text
WITH * WHERE text IS null
RETURN name AS undocumentedTo generate the help output, apoc utilizes the built in dbms.procedures() and dbms.functions() utilities.
Overview of APOC Procedures & Functions
User Defined Functions
Introduced in Neo4j 3.1.0-M10
Neo4j 3.1 brings some really neat improvements in Cypher alongside other cool features
If you used or wrote procedures in the past, you most probably came across instances where it felt quite unwieldy to call a procedure just to compute something, convert a value or provide a boolean decision.
For example:
CREATE (v:Value {id:{id}, data:{data}})
WITH v
CALL apoc.date.format(timestamp(), "ms") YIELD value as created
SET v.created = createdYou’d rather write it as a function:
CREATE (v:Value {id:{id}, data:{data}, created: apoc.date.format(timestamp()) })Now in 3.1 that’s possible, and you can also leave off the "ms" and use a single function name, because the unit and format parameters have a default value.
Functions are more limited than procedures: they can’t execute writes or schema operations and are expected to return a single value, not a stream of values. But this makes it also easier to write and use them.
By having information about their types, the Cypher Compiler can also check for applicability.
The signature of the procedure above changed from:
@Procedure("apoc.date.format")
public Stream<StringResult> formatDefault(@Name("time") long time, @Name("unit") String unit) {
return Stream.of(format(time, unit, DEFAULT_FORMAT));
}to the much simpler function signature (ignoring the parameter name and value annotations):
@UserFunction("apoc.date.format")
public String format(@Name("time") long time,
@Name(value="unit", defaultValue="ms") String unit,
@Name(value="format", defaultValue=DEFAULT_FORMAT) String format) {
return getFormatter().format(time, unit, format);
}This can then be called in the manner outlined above.
In our APOC procedure library we already converted about 50 procedures into functions from the following areas:
| package | # of functions | example function |
|---|---|---|
date & time conversion |
3 |
|
number conversion |
3 |
|
general type conversion |
8 |
|
type information and checking |
4 |
|
collection and map functions |
25 |
|
JSON conversion |
4 |
|
string functions |
7 |
|
hash functions |
2 |
|
You can list user defined functions with call dbms.functions()
Text and Lookup Indexes
Index Queries
Procedures to add to and query manual indexes
|
Note
|
Please note that there are (case-sensitive) automatic schema indexes, for equality, non-equality, existence, range queries, starts with, ends-with and contains! |
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.index.addAllNodes('name',{label1:['prop1',…],…}, {options}) YIELD type, name, config - create a free text search index |
procedure |
|
apoc.index.addAllNodesExtended('name',{label1:['prop1',…],…}, {options}) YIELD type, name, config - create a free text search index with special options |
procedure |
|
apoc.index.search('name', 'query', [maxNumberOfResults]) YIELD node, weight - search for nodes in the free text index matching the given query |
procedure |
|
apoc.index.relatedNodes([nodes],label,key,'<TYPE'/'TYPE>'/'TYPE',limit) yield node - schema range scan which keeps index order and adds limit and checks opposite node of relationship against the given set of nodes |
procedure |
|
apoc.index.orderedRange(label,key,min,max,sort-relevance,limit) yield node - schema range scan which keeps index order and adds limit, values can be null, boundaries are inclusive |
procedure |
|
apoc.index.orderedByText(label,key,operator,value,sort-relevance,limit) yield node - schema string search which keeps index order and adds limit, operator is 'STARTS WITH' or 'CONTAINS' |
procedure |
|
apoc.schema.properties.distinct(label, key) - quickly returns all distinct values for a given key |
procedure |
|
apoc.schema.properties.distinctCount([label], [key]) YIELD label, key, value, count - quickly returns all distinct values and counts for a given key |
procedure |
|
apoc.index.nodes('Label','prop:value*') YIELD node - lucene query on node index with the given label name |
procedure |
|
apoc.index.forNodes('name',{config}) YIELD type,name,config - gets or creates node index |
procedure |
|
apoc.index.forRelationships('name',{config}) YIELD type,name,config - gets or creates relationship index |
procedure |
|
apoc.index.remove('name') YIELD type,name,config - removes an manual index |
procedure |
|
apoc.index.list() - YIELD type,name,config - lists all manual indexes |
procedure |
|
apoc.index.relationships('TYPE','prop:value*') YIELD rel - lucene query on relationship index with the given type name |
procedure |
|
apoc.index.between(node1,'TYPE',node2,'prop:value*') YIELD rel - lucene query on relationship index with the given type name bound by either or both sides (each node parameter can be null) |
procedure |
|
out(node,'TYPE','prop:value*') YIELD node - lucene query on relationship index with the given type name for outgoing relationship of the given node, returns end-nodes |
procedure |
|
apoc.index.in(node,'TYPE','prop:value*') YIELD node lucene query on relationship index with the given type name for incoming relationship of the given node, returns start-nodes |
procedure |
|
apoc.index.addNode(node,['prop1',…]) add node to an index for each label it has |
procedure |
|
apoc.index.addNodeByLabel(node,'Label',['prop1',…]) add node to an index for the given label |
procedure |
|
apoc.index.addNodeByName('name',node,['prop1',…]) add node to an index for the given name |
procedure |
|
apoc.index.addRelationship(rel,['prop1',…]) add relationship to an index for its type |
procedure |
|
apoc.index.addRelationshipByName('name',rel,['prop1',…]) add relationship to an index for the given name |
procedure |
|
apoc.index.removeNodeByName('name',node) remove node from an index for the given name |
procedure |
|
apoc.index.removeRelationshipByName('name',rel) remove relationship from an index for the given name |
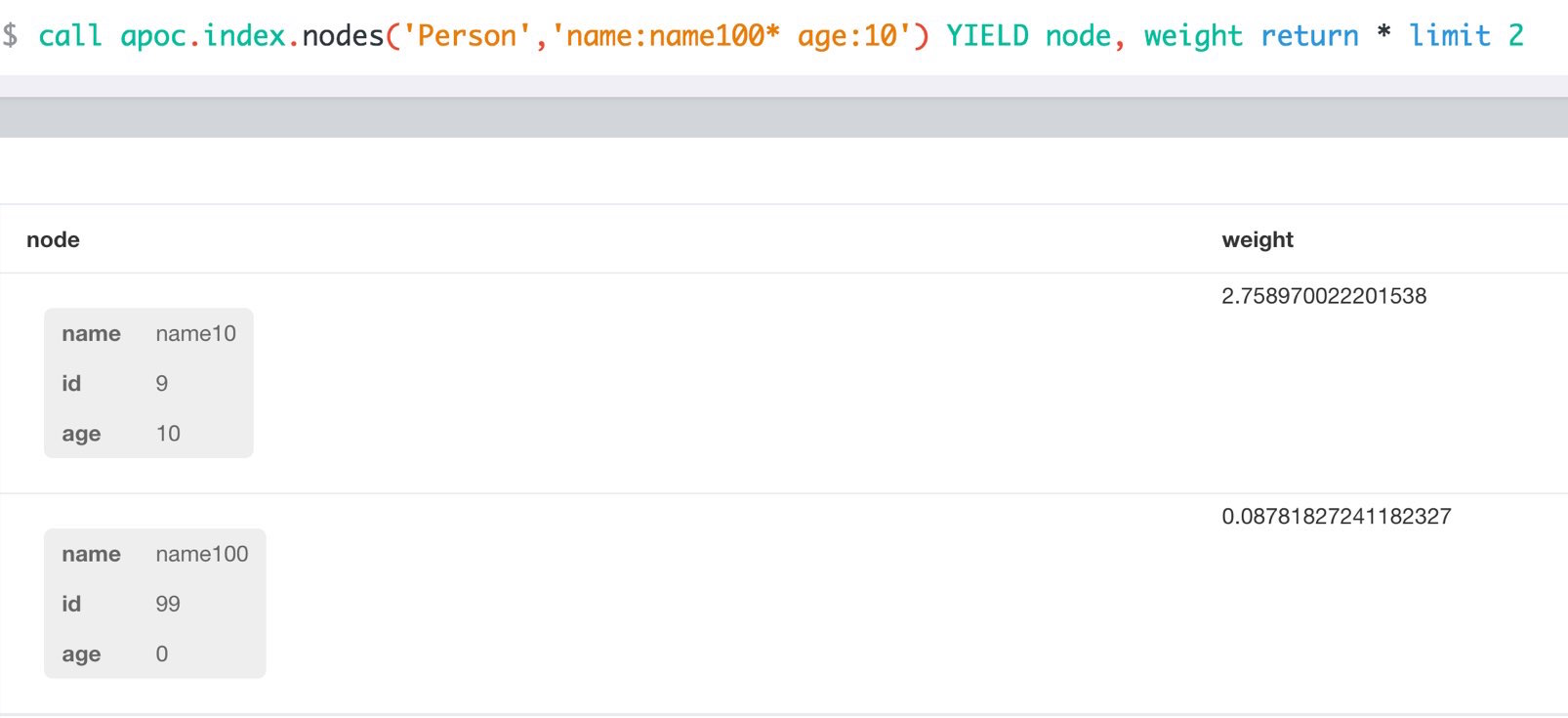
Index Management
match (p:Person) call apoc.index.addNode(p,["name","age"]) RETURN count(*);
// 129s for 1M People
call apoc.index.nodes('Person','name:name100*') YIELD node, weight return * limit 2Manual Indexes
Data Used
The below examples use flight data.
Here is a sample subset of the data that can be load to try the procedures:
CREATE (slc:Airport {abbr:'SLC', id:14869, name:'SALT LAKE CITY INTERNATIONAL'})
CREATE (oak:Airport {abbr:'OAK', id:13796, name:'METROPOLITAN OAKLAND INTERNATIONAL'})
CREATE (bur:Airport {abbr:'BUR', id:10800, name:'BOB HOPE'})
CREATE (f2:Flight {flight_num:6147, day:2, month:1, weekday:6, year:2016})
CREATE (f9:Flight {flight_num:6147, day:9, month:1, weekday:6, year:2016})
CREATE (f16:Flight {flight_num:6147, day:16, month:1, weekday:6, year:2016})
CREATE (f23:Flight {flight_num:6147, day:23, month:1, weekday:6, year:2016})
CREATE (f30:Flight {flight_num:6147, day:30, month:1, weekday:6, year:2016})
CREATE (f2)-[:DESTINATION {arr_delay:-13, taxi_time:9}]->(oak)
CREATE (f9)-[:DESTINATION {arr_delay:-8, taxi_time:4}]->(bur)
CREATE (f16)-[:DESTINATION {arr_delay:-30, taxi_time:4}]->(slc)
CREATE (f23)-[:DESTINATION {arr_delay:-21, taxi_time:3}]->(slc)
CREATE (f30)-[:DESTINATION]->(slc)Using Manual Index on Node Properties
In order to create manual index on a node property, you call apoc.index.addNode with the node, providing the properties to be indexed.
MATCH (a:Airport)
CALL apoc.index.addNode(a,['name'])
RETURN count(*)The statement will create the node index with the same name as the Label name(s) of the node in this case Airport and add the node by their properties to the index.
Once this has been added check if the node index exists using apoc.index.list.
CALL apoc.index.list()Usually apoc.index.addNode would be used as part of node-creation, e.g. during LOAD CSV.
There is also apoc.index.addNodes for adding a list of multiple nodes at once.
Once the node index is created we can start using it.
Here are some examples:
The apoc.index.nodes finds nodes in a manual index using the given lucene query.
|
Note
|
That makes only sense if you combine multiple properties in one lookup or use case insensitive or fuzzy matching full-text queries. In all other cases the built in schema indexes should be used. |
CALL apoc.index.nodes('Airport','name:inter*') YIELD node AS airport, weight
RETURN airport.name, weight
LIMIT 10|
Note
|
Apoc index queries not only return nodes and relationships but also a weight, which is the score returned from the underlying Lucene index. The results are also sorted by that score. That’s especially helpful for partial and fuzzy text searches. |
To remove the node index Airport created, use:
CALL apoc.index.remove('Airport')Using Manual Index on Relationship Properties
The procedure apoc.index.addRelationship is used to create a manual index on relationship properties.
As there are no schema indexes for relationships, these manual indexes can be quite useful.
MATCH (:Flight)-[r:DESTINATION]->(:Airport)
CALL apoc.index.addRelationship(r,['taxi_time'])
RETURN count(*)The statement will create the relationship index with the same name as relationship-type, in this case DESTINATION and add the relationship by its properties to the index.
Using apoc.index.relationships, we can find the relationship of type DESTINATION with the property taxi_time of 11 minutes.
We can chose to also return the start and end-node.
CALL apoc.index.relationships('DESTINATION','taxi_time:11') YIELD rel, start AS flight, end AS airport
RETURN flight_num.flight_num, airport.name;|
Note
|
Manual relationship indexed do not only store the relationship by its properties but also the start- and end-node. |
That’s why we can use that information to subselect relationships not only by property but also by those nodes, which is quite powerful.
With apoc.index.in we can pin the node with incoming relationships (end-node) to get the start nodes for all the DESTINATION relationships.
For instance to find all flights arriving in 'SALT LAKE CITY INTERNATIONAL' with a taxi_time of 7 minutes we’d use:
MATCH (a:Airport {name:'SALT LAKE CITY INTERNATIONAL'})
CALL apoc.index.in(a,'DESTINATION','taxi_time:7') YIELD node AS flight
RETURN flightThe opposite is apoc.index.out, which takes and binds end-nodes and returns start-nodes of relationships.
Really useful to quickly find a subset of relationships between nodes with many relationships (tens of thousands to millions) is apoc.index.between.
Here you bind both the start and end-node and provide (or not) properties of the relationships.
MATCH (f:Flight {flight_num:6147})
MATCH (a:Airport {name:'SALT LAKE CITY INTERNATIONAL'})
CALL apoc.index.between(f,'DESTINATION',a,'taxi_time:7') YIELD rel, weight
RETURN *To remove the relationship index DESTINATION that was created, use.
CALL apoc.index.remove('DESTINATION')Full Text Search
Indexes are used for finding nodes in the graph that further operations can then continue from. Just like in a book where you look at the index to find a section that interest you, and then start reading from there. A full text index allows you to find occurrences of individual words or phrases across all attributes.
In order to use the full text search feature, we have to first index our data by specifying all the attributes we want to index.
Here we create a full text index called “locations” (we will use this name when searching in the index) with our data.
|
Note
|
by default these fulltext indexes do not automatically track changes you perform in your graph. See …. for how to enabled automatic index tracking. |
CALL apoc.index.addAllNodes('locations',{
Company: ["name", "description"],
Person: ["name","address"],
Address: ["address"]})Creating the index will take a little while since the procedure has to read through the entire database to create the index.
We can now use this index to search for nodes in the database. The most simple case would be to search across all data for a particular word.
It does not matter which property that word exists in, any node that has that word in any of its indexed properties will be found.
If you use a name in the call, all occurrences will be found (but limited to 100 results).
CALL apoc.index.search("locations", 'name')Advanced Search
We can further restrict our search to only searching in a particular attribute.
In order to search for a Person with an address in France, we use the following.
CALL apoc.index.search("locations", "Person.address:France")Now we can search for nodes with a specific property value, and then explore their neighbourhoods visually.
But integrating it with an graph query is so much more powerful.
Fulltext and Graph Search
We could for instance search for addresses in the database that contain the word "Paris", and then find all companies registered at those addresses:
CALL apoc.index.search("locations", "Address.address:Paris~") YIELD node AS addr
MATCH (addr)<-[:HAS_ADDRESS]-(company:Company)
RETURN company LIMIT 50The tilde (~) instructs the index search procedure to do a fuzzy match, allowing us to find "Paris" even if the spelling is slightly off.
We might notice that there are addresses that contain the word “Paris” that are not in Paris, France. For example there might be a Paris Street somewhere.
We can further specify that we want the text to contain both the word Paris, and the word France:
CALL apoc.index.search("locations", "+Address.address:Paris~ +France~")
YIELD node AS addr
MATCH (addr)<-[:HAS_ADDRESS]-(company:Company)
RETURN company LIMIT 50Complex Searches
Things start to get interesting when we look at how the different entities in Paris are connected to one another. We can do that by finding all the entities with addresses in Paris, then creating all pairs of such entities and finding the shortest path between each such pair:
CALL apoc.index.search("locations", "+Address.address:Paris~ +France~") YIELD node AS addr
MATCH (addr)<-[:HAS_ADDRESS]-(company:Company)
WITH collect(company) AS companies
// create unique pairs
UNWIND companies AS x UNWIND companies AS y
WITH x, y WHERE ID(x) < ID(y)
MATCH path = shortestPath((x)-[*..10]-(y))
RETURN pathFor more details on the query syntax used in the second parameter of the search procedure,
please see this Lucene query tutorial
Index Configuration
apoc.index.addAllNodes(<name>, <labelPropsMap>, <option>) allows to fine tune your indexes using the options parameter defaulting to an empty map.
All standard options for Neo4j manual indexes are allowed plus apoc specific options:
| name | value | description |
|---|---|---|
|
|
type of the index |
|
|
if terms should be converted to lower case before indexing |
|
|
classname of lucene analyzer to be used for this index |
|
|
classname for lucene similarity to be used for this index |
|
|
if this index should be tracked for graph updates |
|
Note
|
An index configuration cannot be changed once the index is created.
However subsequent invocations of apoc.index.addAllNodes will delete the index if existing and create it afterwards.
|
Automatic Index Tracking for Manual Indexes
As mentioned above, apoc.index.addAllNodes() populates an fulltext index.
But it does not track changes being made to the graph and reflect these changes to the index.
You would have to rebuild that index regularly yourself.
Or alternatively use the automatic index tracking, that keeps the index in sync with your graph changes. To enable this feature a two step configuration approach is required.
|
Note
|
Please note that there is a performance impact if you enable automatic index tracking. |
neo4j.conf setapoc.autoIndex.enabled=trueThis global setting will initialize a transaction event handler to take care of reflecting changes of any added nodes, deleted nodes, changed properties to the indexes.
In addition to enable index tracking globally using apoc.autoIndex.enabled each individual index must be configured as "trackable" by setting autoUpdate:true in the options when initially creating an index:
CALL apoc.index.addAllNodes('locations',{
Company: ["name", "description"],
Person: ["name","address"],
Address: ["address"]}, {autoUpdate:true})By default index tracking is done synchronously. That means updates to fulltext indexes are part of same transaction as the originating change (e.g. changing a node property). While this guarantees instant consistency it has an impact on performance.
Alternatively, you can decide to perform index updates asynchronously in a separate thread by setting this flag in neo4j.conf
apoc.autoIndex.async=trueWith this setting enabled, index updates are fed to a buffer queue that is consumed asynchronously using transaction batches. The batching can be further configured using
apoc.autoIndex.queue_capacity=100000
apoc.autoIndex.async_rollover_opscount=50000
apoc.autoIndex.async_rollover_millis=5000
apoc.autoIndex.tx_handler_stopwatch=falseThe values above are the default setting. In this example the index updates are consumed in transactions of maximum 50000 operations or 5000 milliseconds - whichever triggers first will cause the index update transaction to be committed and rolled over.
If apoc.autoIndex.tx_handler_stopwatch is enabled, the time spent in beforeCommit and afterCommit is traced to debug.log.
Use this setting only for diagnosis.
A Worked Example on Fulltext Index Tracking
This section provides a small but still usable example to understand automatic index updates.
Make sure apoc.autoIndex.enabled=true is set.
First we create some nodes - note there’s no index yet.
UNWIND ["Johnny Walker", "Jim Beam", "Jack Daniels"] as name CREATE (:Person{name:name})Now we index them:
CALL apoc.index.addAllNodes('people', { Person:["name"]}, {autoUpdate:true})Check if we can find "Johnny" - we expect one result.
CALL apoc.index.search("people", "Johnny") YIELD node, weight
RETURN node.name, weightAdding some more people - note, we have another "Johnny":
UNWIND ["Johnny Rotten", "Axel Rose"] as name CREATE (:Person{name:name})Again we’re search for "Johnny", expecting now two of them:
CALL apoc.index.search("people", "Johnny") YIELD node, weight
RETURN node.name, weightUtility Functions
Phonetic Text Procedures
The phonetic text (soundex) procedures allow you to compute the soundex encoding of a given string. There is also a procedure to compare how similar two strings sound under the soundex algorithm. All soundex procedures by default assume the used language is US English.
CALL apoc.text.phonetic('Hello, dear User!') YIELD value
RETURN value // will return 'H436'CALL apoc.text.phoneticDelta('Hello Mr Rabbit', 'Hello Mr Ribbit') // will return '4' (very similar)Extract Domain
The User Function apoc.data.domain will take a url or email address and try to determine the domain name.
This can be useful to make easier correlations and equality tests between differently formatted email addresses, and between urls to the same domains but specifying different locations.
WITH 'foo@bar.com' AS email
RETURN apoc.data.domain(email) // will return 'bar.com'WITH 'http://www.example.com/all-the-things' AS url
RETURN apoc.data.domain(url) // will return 'www.example.com'TimeToLive (TTL) - Expire Nodes
Enable cleanup of expired nodes in neo4j.conf with apoc.ttl.enabled=true
30s after startup an index is created:
CREATE INDEX ON :TTL(ttl)At startup a statement is scheduled to run every 60s (or configure in neo4j.conf - apoc.ttl.schedule=120)
MATCH (t:TTL) where t.ttl < timestamp() WITH t LIMIT 1000 DETACH DELETE tThe ttl property holds the time when the node is expired in milliseconds since epoch.
You can expire your nodes by setting the :TTL label and the ttl property:
MATCH (n:Foo) WHERE n.bar SET n:TTL, n.ttl = timestamp() + 10000;There is also a procedure that does the same:
CALL apoc.date.expire(node,time,'time-unit');
CALL apoc.date.expire(n,100,'s');Date and Time Conversions
(thanks @tkroman)
Conversion between formatted dates and timestamps
-
apoc.date.parse('2015/03/25 03-15-59',['s'],['yyyy/MM/dd HH/mm/ss'])same as previous, but accepts custom datetime format -
apoc.date.format(12345,['s'], ['yyyy/MM/dd HH/mm/ss'])the same as previous, but accepts custom datetime format -
possible unit values:
ms,s,m,h,dand their long forms. -
possible time zone values: Either an abbreviation such as
PST, a full name such asAmerica/Los_Angeles, or a custom ID such asGMT-8:00. Full names are recommended.
Conversion of timestamps between different time units
-
apoc.date.convert(12345, 'ms', 'd')convert a timestamp in one time unit into one of a different time unit -
possible unit values:
ms,s,m,h,dand their long forms.
Adding/subtracting time unit values to timestamps
-
apoc.date.add(12345, 'ms', -365, 'd')given a timestamp in one time unit, adds a value of the specified time unit -
possible unit values:
ms,s,m,h,dand their long forms.
Current timestamp
apoc.date.currentTimestamp() provides the System.currentTimeMillis which is current throughout transaction execution compared to Cypher’s timestamp() function which does not update within a transaction
Reading separate datetime fields:
Splits date (optionally, using given custom format) into fields returning a map from field name to its value.
RETURN apoc.date.fields('2015-03-25 03:15:59')Following fields are supported:
| Result field | Represents |
|---|---|
'years' |
year |
'months' |
month of year |
'days' |
day of month |
'hours' |
hour of day |
'minutes' |
minute of hour |
'seconds' |
second of minute |
'zone' |
Examples
RETURN apoc.date.fields('2015-01-02 03:04:05 EET', 'yyyy-MM-dd HH:mm:ss zzz') {
'weekdays': 5,
'years': 2015,
'seconds': 5,
'zoneid': 'EET',
'minutes': 4,
'hours': 3,
'months': 1,
'days': 2
}
RETURN apoc.date.fields('2015/01/02_EET', 'yyyy/MM/dd_z') {
'weekdays': 5,
'years': 2015,
'zoneid': 'EET',
'months': 1,
'days': 2
}
Notes on formats:
-
the default format is
yyyy-MM-dd HH:mm:ss -
if the format pattern doesn’t specify timezone, formatter considers dates to belong to the UTC timezone
-
if the timezone pattern is specified, the timezone is extracted from the date string, otherwise an error will be reported
-
the
to/fromSecondstimestamp values are in POSIX (Unix time) system, i.e. timestamps represent the number of seconds elapsed since 00:00:00 UTC, Thursday, 1 January 1970 -
the full list of supported formats is described in SimpleDateFormat JavaDoc
Number Format Conversions
Conversion between formatted decimals
-
apoc.number.format(number)format a long or double using the default system pattern and language to produce a string -
apoc.number.format(number, pattern)format a long or double using a pattern and the default system language to produce a string -
apoc.number.format(number, lang)format a long or double using the default system pattern pattern and a language to produce a string -
apoc.number.format(number, pattern, lang)format a long or double using a pattern and a language to produce a string -
apoc.number.parseInt(text)parse a text using the default system pattern and language to produce a long -
apoc.number.parseInt(text, pattern)parse a text using a pattern and the default system language to produce a long -
apoc.number.parseInt(text, '', lang)parse a text using the default system pattern and a language to produce a long -
apoc.number.parseInt(text, pattern, lang)parse a text using a pattern and a language to produce a long -
apoc.number.parseFloat(text)parse a text using the default system pattern and language to produce a double -
apoc.number.parseFloat(text, pattern)parse a text using a pattern and the default system language to produce a double -
apoc.number.parseFloat(text,'',lang)parse a text using the default system pattern and a language to produce a double -
apoc.number.parseFloat(text, pattern, lang)parse a text using a pattern and a language to produce a double -
The full list of supported values for
patternandlangparams is described in DecimalFormat JavaDoc
Examples
return apoc.number.format(12345.67) as value ╒═════════╕ │value │ ╞═════════╡ │12,345.67│ └─────────┘
return apoc.number.format(12345, '#,##0.00;(#,##0.00)', 'it') as value ╒═════════╕ │value │ ╞═════════╡ │12.345,00│ └─────────
return apoc.number.format(12345.67, '#,##0.00;(#,##0.00)', 'it') as value ╒═════════╕ │value │ ╞═════════╡ │12.345,67│ └─────────┘
return apoc.number.parseInt('12.345', '#,##0.00;(#,##0.00)', 'it') as value
╒═════╕
│value│
╞═════╡
│12345│
└─────┘
return apoc.number.parseFloat('12.345,67', '#,##0.00;(#,##0.00)', 'it') as value
╒════════╕
│value │
╞════════╡
│12345.67│
└────────┘
return apoc.number.format('aaa') as value
null beacuse 'aaa' isn't a number
RETURN apoc.number.parseInt('aaa')
Return null because 'aaa' is unparsable.
Exact
Handle BigInteger And BigDecimal
| Statement | Description | Return type |
|---|---|---|
RETURN apoc.number.exact.add(stringA,stringB) |
return the sum’s result of two large numbers |
string |
RETURN apoc.number.exact.sub(stringA,stringB) |
return the substraction’s of two large numbers |
string |
RETURN apoc.number.exact.mul(stringA,stringB,[prec],[roundingModel] |
return the multiplication’s result of two large numbers |
string |
RETURN apoc.number.exact.div(stringA,stringB,[prec],[roundingModel]) |
return the division’s result of two large numbers |
string |
RETURN apoc.number.exact.toInteger(string,[prec],[roundingMode]) |
return the Integer value of a large number |
Integer |
RETURN apoc.number.exact.toFloat(string,[prec],[roundingMode]) |
return the Float value of a large number |
Float |
RETURN apoc.number.exact.toExact(number) |
return the exact value |
Integer |
-
Possible 'roundingModel' options are
UP,DOWN,CEILING,FLOOR,HALF_UP,HALF_DOWN,HALF_EVEN,UNNECESSARY
The prec parameter let us to set the precision of the operation result.
The default value is 0 (unlimited precision arithmetic) while for 'roundingModel' the default value is HALF_UP. For other information abouth prec and roundingModel see the documentation of MathContext
For example if we set as prec 2:
return apoc.number.exact.div('5555.5555','5', 2, 'HALF_DOWN') as value
╒═════════╕
│value │
╞═════════╡
│ 1100 │
└─────────┘
As a result we have only the first two digits precise. If we set 8 we have all the result precise
return apoc.number.exact.div('5555.5555','5', 8, 'HALF_DOWN') as value
╒═════════╕
│value │
╞═════════╡
│1111.1111│
└─────────┘
All the functions accept as input the scientific notation as 1E6, for example:
return apoc.number.exact.add('1E6','1E6') as value
╒═════════╕
│value │
╞═════════╡
│ 2000000 │
└─────────┘
For other information see the documentation about BigDecimal and BigInteger
Graph Algorithms
Algorithm Procedures
Community Detection via Label Propagation
APOC includes a simple procedure for label propagation. It may be used to detect communities or solve other graph partitioning problems. The following example shows how it may be used.
The example call with scan all nodes 25 times. During a scan the procedure will look at all outgoing relationships of type :X for each node n. For each of these relationships, it will compute a weight and use that as a vote for the other node’s 'partition' property value. Finally, n.partition is set to the property value that acquired the most votes.
Weights are computed by multiplying the relationship weight with the weight of the other nodes. Both weights are taken from the 'weight' property; if no such property is found, the weight is assumed to be 1.0. Similarly, if no 'weight' property key was specified, all weights are assumed to be 1.0.
CALL apoc.algo.community(25,null,'partition','X','OUTGOING','weight',10000)The second argument is a list of label names and may be used to restrict which nodes are scanned.
Expand paths
Expand from start node following the given relationships from min to max-level adhering to the label filters. Several variations exist:
apoc.path.expand() expands paths using Cypher’s default expansion modes (bfs and 'RELATIONSHIP_PATH' uniqueness)
apoc.path.expandConfig() allows more flexible configuration of parameters and expansion modes
apoc.path.subgraphNodes() expands to nodes of a subgraph
apoc.path.subgraphAll() expands to nodes of a subgraph and also returns all relationships in the subgraph
apoc.path.spanningTree() expands to paths collectively forming a spanning tree
Expand
CALL apoc.path.expand(startNode <id>|Node, relationshipFilter, labelFilter, minLevel, maxLevel )
CALL apoc.path.expand(startNode <id>|Node|list, 'TYPE|TYPE_OUT>|<TYPE_IN', '+YesLabel|-NoLabel|/TerminationLabel|>EndNodeLabel', minLevel, maxLevel ) yield pathRelationship Filter
Syntax: [<]RELATIONSHIP_TYPE1[>]|[<]RELATIONSHIP_TYPE2[>]|…
| input | type | direction |
|---|---|---|
|
|
OUTGOING |
|
|
INCOMING |
|
|
BOTH |
Label Filter
Syntax: [+-/>]LABEL1|LABEL2|…
As of APOC 3.1.3.x multiple label filter operations are allowed.
In prior versions, only one type of operation is allowed in the label filter (+ or - or / or >, never more than one).
With APOC 3.2.x.x, label filters will no longer apply to starting nodes of the expansion by default.
| input | label | result |
|---|---|---|
|
|
blacklist filter - No node in the path will have a label in the blacklist. |
|
|
whitelist filter - All nodes in the path must have a label in the whitelist (exempting termination and end nodes, if using those filters). If no whitelist operator is present, all labels are considered whitelisted. |
|
|
termination filter - Only return paths up to a node of the given labels, and stop further expansion beyond it. Termination nodes do not have to respect the whitelist. Termination filtering takes precedence over end node filtering. |
|
|
end node filter - Only return paths up to a node of the given labels, but continue expansion to match on end nodes beyond it. End nodes do not have to respect the whitelist to be returned, but expansion beyond them is only allowed if the node has a label in the whitelist. |
call apoc.path.expand(1,"ACTED_IN>|PRODUCED<|FOLLOWS<","+Movie|Person",0,3)
call apoc.path.expand(1,"ACTED_IN>|PRODUCED<|FOLLOWS<","-BigBrother",0,3)
call apoc.path.expand(1,"ACTED_IN>|PRODUCED<|FOLLOWS<","",0,3)
// combined with cypher:
match (tom:Person {name :"Tom Hanks"})
call apoc.path.expand(tom,"ACTED_IN>|PRODUCED<|FOLLOWS<","+Movie|Person",0,3) yield path as pp
return pp;
// or
match (p:Person) with p limit 3
call apoc.path.expand(p,"ACTED_IN>|PRODUCED<|FOLLOWS<","+Movie|Person",1,2) yield path as pp
return p, ppWe will first set a :Western label on some nodes.
match (p:Person)
where p.name in ['Clint Eastwood', 'Gene Hackman']
set p:WesternNow expand from 'Keanu Reeves' to all :Western nodes with a termination filter:
match (k:Person {name:'Keanu Reeves'})
call apoc.path.expandConfig(k, {relationshipFilter:'ACTED_IN|PRODUCED|DIRECTED', labelFilter:'/Western', uniqueness: 'NODE_GLOBAL'}) yield path
return pathThe one returned path only matches up to 'Gene Hackman'. While there is a path from 'Keanu Reeves' to 'Clint Eastwood' through 'Gene Hackman', no further expansion is permitted through a node in the termination filter.
If you didn’t want to stop expansion on reaching 'Gene Hackman', and wanted 'Clint Eastwood' returned as well, use the end node filter instead (>).
As of APOC 3.1.3.x, multiple label filter operators are allowed at the same time.
When processing the labelFilter string, once a filter operator is introduced, it remains the active filter until another filter supplants it.
In the following example, :Person and :Movie labels are whitelisted, :SciFi is blacklisted, with :Western acting as an end node label, and :Romance acting as a termination label.
… labelFilter:'+Person|Movie|-SciFi|>Western|/Romance' …
The precedence of operator evaluation isn’t dependent upon their location in the labelFilter but is fixed:
Blacklist filter -, termination filter /, end node filter >, whitelist filter +.
The consequences are as follows:
-
No blacklisted label
-will ever be present in the nodes of paths returned, no matter if the same label (or another label of a node with a blacklisted label) is included in another filter list. -
If the termination filter
/or end node filter>is used, then only paths up to nodes with those labels will be returned as results. These end nodes are exempt from the whitelist filter. -
If a node is a termination node
/, no further expansion beyond the node will occur. -
If a node is an end node
>, expansion beyond that node will only occur if the end node has a label in the whitelist. This is to prevent returning paths to nodes where a node on that path violates the whitelist. -
The whitelist only applies to nodes up to but not including end nodes from the termination or end node filters. If no end node or termination node operators are present, then the whitelist applies to all nodes of the path.
-
If no whitelist operators are present in the labelFilter, this is treated as if all labels are whitelisted.
-
If
filterStartNodeis false (which will be default in APOC 3.2.x.x), then the start node is exempt from the label filter.
Expand with Config
apoc.path.expandConfig(startNode <id>Node/list, {config}) yield path expands from start nodes using the given configuration and yields the resulting paths
Takes an additional map parameter, config, to provide configuration options:
{minLevel: -1|number,
maxLevel: -1|number,
relationshipFilter: '[<]RELATIONSHIP_TYPE1[>]|[<]RELATIONSHIP_TYPE2[>]|...',
labelFilter: '[+-/>]LABEL1|LABEL2|...',
uniqueness: RELATIONSHIP_PATH|NONE|NODE_GLOBAL|NODE_LEVEL|NODE_PATH|NODE_RECENT|
RELATIONSHIP_GLOBAL|RELATIONSHIP_LEVEL|RELATIONSHIP_RECENT,
bfs: true|false,
filterStartNode: true|false,
limit: -1|number,
optional: true|false}
The config parameter filterStartNode defines whether or not the labelFilter applies to the start node of the expansion.
Use filterStartNode = false when you want your label filter to only apply to all other nodes in the path, ignoring the start node.
filterStartNode defaults for all path expander procedures:
| version | default |
|---|---|
>= APOC 3.2.x.x |
filterStartNode = false |
< APOC 3.2.x.x |
filterStartNode = true |
Only when using the termination label filter / or end node filter >, you can use the limit config parameter to limit the number of paths returned.
When using bfs:true (which is the default for all expand procedures), this has the effect of returning paths to the n nearest nodes with labels in the termination or end node filter, where n is the limit given.
The default limit value, -1, means no limit.
If you want to make sure multiple paths should never match to the same node, use expandConfig() with 'NODE_GLOBAL' uniqueness, or any expand procedure which already uses this uniqueness
(subgraphNodes(), subgraphAll(), and spanningTree()).
When optional is set to true, the path expansion is optional, much like an OPTIONAL MATCH, so a null value is yielded whenever the expansion would normally eliminate rows due to no results.
By default optional is false for all expansion procedures taking a config parameter.
Uniqueness of nodes and relationships guides the expansion and the results returned.
Uniqueness is only configurable using expandConfig().
subgraphNodes(), subgraphAll(), and spanningTree() all use 'NODE_GLOBAL' uniqueness.
| value | description |
|---|---|
|
For each returned node there’s a (relationship wise) unique path from the start node to it. This is Cypher’s default expansion mode. |
|
A node cannot be traversed more than once. This is what the legacy traversal framework does. |
|
Entities on the same level are guaranteed to be unique. |
|
For each returned node there’s a unique path from the start node to it. |
|
This is like NODE_GLOBAL, but only guarantees uniqueness among the most recent visited nodes, with a configurable count. Traversing a huge graph is quite memory intensive in that it keeps track of all the nodes it has visited. For huge graphs a traverser can hog all the memory in the JVM, causing OutOfMemoryError. Together with this Uniqueness you can supply a count, which is the number of most recent visited nodes. This can cause a node to be visited more than once, but scales infinitely. |
|
A relationship cannot be traversed more than once, whereas nodes can. |
|
Entities on the same level are guaranteed to be unique. |
|
Same as for NODE_RECENT, but for relationships. |
|
No restriction (the user will have to manage it) |
You can turn this cypher query:
MATCH (user:User) WHERE user.id = 460
MATCH (user)-[:RATED]->(movie)<-[:RATED]-(collab)-[:RATED]->(reco)
RETURN count(*);into this procedure call, with changed semantics for uniqueness and bfs (which is Cypher’s expand mode)
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.expandConfig(user,{relationshipFilter:"RATED",minLevel:3,maxLevel:3,bfs:false,uniqueness:"NONE"}) YIELD path
RETURN count(*);Expand to nodes in a subgraph
apoc.path.subgraphNodes(startNode <id>Node/list, {maxLevel, relationshipFilter, labelFilter, bfs:true, filterStartNode:true, limit:-1, optional:false}) yield node
Expand to subgraph nodes reachable from the start node following relationships to max-level adhering to the label filters.
Accepts the same config values as in expandConfig(), though uniqueness and minLevel are not configurable.
Expand to all nodes of a connected subgraph:
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.subgraphNodes(user, {}) YIELD node
RETURN node;Expand to all nodes reachable by :FRIEND relationships:
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.subgraphNodes(user, {relationshipFilter:'FRIEND'}) YIELD node
RETURN node;Expand to a subgraph and return all nodes and relationships within the subgraph
apoc.path.subgraphAll(startNode <id>Node/list, {maxLevel, relationshipFilter, labelFilter, bfs:true, filterStartNode:true, limit:-1}) yield nodes, relationships
Expand to subgraph nodes reachable from the start node following relationships to max-level adhering to the label filters. Returns the collection of nodes in the subgraph, and the collection of relationships between all subgraph nodes.
Accepts the same config values as in expandConfig(), though uniqueness and minLevel are not configurable.
The optional config value isn’t needed, as empty lists are yielded if there are no results, so rows are never eliminated.
Expand to local subgraph (and all its relationships) within 4 traversals:
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.subgraphAll(user, {maxLevel:4}) YIELD nodes, relationships
RETURN nodes, relationships;Expand a spanning tree
apoc.path.spanningTree(startNode <id>Node/list, {maxLevel, relationshipFilter, labelFilter, bfs:true, filterStartNode:true, limit:-1, optional:false}) yield path
Expand a spanning tree reachable from start node following relationships to max-level adhering to the label filters. The paths returned collectively form a spanning tree.
Accepts the same config values as in expandConfig(), though uniqueness and minLevel are not configurable.
Expand a spanning tree of all contiguous :User nodes:
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.spanningTree(user, {labelFilter:'+User'}) YIELD path
RETURN path;Centrality Algorithms
Setup
Let’s create some test data to run the Centrality algorithms on.
// create 100 nodes
FOREACH (id IN range(0,1000) | CREATE (:Node {id:id}))
// over the cross product (1M) create 100.000 relationships
MATCH (n1:Node),(n2:Node) WITH n1,n2 LIMIT 1000000 WHERE rand() < 0.1
CREATE (n1)-[:TYPE]->(n2)Closeness Centrality Procedure
Centrality is an indicator of a node’s influence in a graph. In graphs there is a natural distance metric between pairs of nodes, defined by the length of their shortest paths. For both algorithms below we can measure based upon the direction of the relationship, whereby the 3rd argument represents the direction and can be of value BOTH, INCOMING, OUTGOING.
Closeness Centrality defines the farness of a node as the sum of its distances from all other nodes, and its closeness as the reciprocal of farness.
The more central a node is the lower its total distance from all other nodes.
Complexity: This procedure uses a BFS shortest path algorithm. With BFS the complexes becomes O(n * m)
Caution: Due to the complexity of this algorithm it is recommended to run it on only the nodes you are interested in.
MATCH (node:Node)
WHERE node.id %2 = 0
WITH collect(node) AS nodes
CALL apoc.algo.closeness(['TYPE'],nodes,'INCOMING') YIELD node, score
RETURN node, score
ORDER BY score DESCBetweenness Centrality Procedure
The procedure will compute betweenness centrality as defined by Linton C. Freeman (1977) using the algorithm by Ulrik Brandes (2001). Centrality is an indicator of a node’s influence in a graph.
Betweenness Centrality is equal to the number of shortest paths from all nodes to all others that pass through that node.
High centrality suggests a large influence on the transfer of items through the graph.
Centrality is applicable to numerous domains, including: social networks, biology, transport and scientific cooperation.
Complexity: This procedure uses a BFS shortest path algorithm. With BFS the complexes becomes O(n * m) Caution: Due to the complexity of this algorithm it is recommended to run it on only the nodes you are interested in.
MATCH (node:Node)
WHERE node.id %2 = 0
WITH collect(node) AS nodes
CALL apoc.algo.betweenness(['TYPE'],nodes,'BOTH') YIELD node, score
RETURN node, score
ORDER BY score DESCPageRank Algorithm
Setup
Let’s create some test data to run the PageRank algorithm on.
// create 100 nodes
FOREACH (id IN range(0,1000) | CREATE (:Node {id:id}))
// over the cross product (1M) create 100.000 relationships
MATCH (n1:Node),(n2:Node) WITH n1,n2 LIMIT 1000000 WHERE rand() < 0.1
CREATE (n1)-[:TYPE_1]->(n2)PageRank Procedure
PageRank is an algorithm used by Google Search to rank websites in their search engine results.
It is a way of measuring the importance of nodes in a graph.
PageRank counts the number and quality of relationships to a node to approximate the importance of that node.
PageRank assumes that more important nodes likely have more relationships.
Caution: nodes specifies the nodes for which a PageRank score will be projected, but the procedure will always compute the PageRank algorithm on the entire graph. At present, there is no way to filter/reduce the number of elements that PageRank computes over.
A future version of this procedure will provide the option of computing PageRank on a subset of the graph.
MATCH (node:Node)
WHERE node.id %2 = 0
WITH collect(node) AS nodes
// compute over relationships of all types
CALL apoc.algo.pageRank(nodes) YIELD node, score
RETURN node, score
ORDER BY score DESCMATCH (node:Node)
WHERE node.id %2 = 0
WITH collect(node) AS nodes
// only compute over relationships of types TYPE_1 or TYPE_2
CALL apoc.algo.pageRankWithConfig(nodes,{types:'TYPE_1|TYPE_2'}) YIELD node, score
RETURN node, score
ORDER BY score DESCMATCH (node:Node)
WHERE node.id %2 = 0
WITH collect(node) AS nodes
// peroform 10 page rank iterations, computing only over relationships of type TYPE_1
CALL apoc.algo.pageRankWithConfig(nodes,{iterations:10,types:'TYPE_1'}) YIELD node, score
RETURN node, score
ORDER BY score DESCSpatial
Spatial Functions
The spatial procedures are intended to enable geographic capabilities on your data.
geocode
The first procedure geocode which will convert a textual address into a location containing latitude, longitude and description. Despite being only a single function, together with the built-in functions point and distance we can achieve quite powerful results.
First, how can we use the procedure:
CALL apoc.spatial.geocodeOnce('21 rue Paul Bellamy 44000 NANTES FRANCE') YIELD location
RETURN location.latitude, location.longitude // will return 47.2221667, -1.5566624There are two forms of the procedure:
-
geocodeOnce(address) returns zero or one result
-
geocode(address,maxResults) returns zero, one or more up to maxResults
This is because the backing geocoding service (OSM, Google, OpenCage or other) might return multiple results for the same query. GeocodeOnce() is designed to return the first, or highest ranking result.
Configuring Geocode
There are a few options that can be set in the neo4j.conf file to control the service:
-
apoc.spatial.geocode.provider=osm (osm, google, opencage, etc.)
-
apoc.spatial.geocode.osm.throttle=5000 (ms to delay between queries to not overload OSM servers)
-
apoc.spatial.geocode.google.throttle=1 (ms to delay between queries to not overload Google servers)
-
apoc.spatial.geocode.google.key=xxxx (API key for google geocode access)
-
apoc.spatial.geocode.google.client=xxxx (client code for google geocode access)
-
apoc.spatial.geocode.google.signature=xxxx (client signature for google geocode access)
For google, you should use either a key or a combination of client and signature. Read more about this on the google page for geocode access at https://developers.google.com/maps/documentation/geocoding/get-api-key#key
Configuring Custom Geocode Provider
For any provider that is not 'osm' or 'google' you get a configurable supplier that requires two additional settings, 'url' and 'key'. The 'url' must contain the two words 'PLACE' and 'KEY'. The 'KEY' will be replaced with the key you get from the provider when you register for the service. The 'PLACE' will be replaced with the address to geocode when the procedure is called.
For example, to get the service working with OpenCage, perform the following steps:
-
Register your own application key at https://geocoder.opencagedata.com/
-
Once you have a key, add the following three lines to neo4j.conf
apoc.spatial.geocode.provider=opencage apoc.spatial.geocode.opencage.key=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX apoc.spatial.geocode.opencage.url=http://api.opencagedata.com/geocode/v1/json?q=PLACE&key=KEY
-
make sure that the 'XXXXXXX' part above is replaced with your actual key
-
Restart the Neo4j server and then test the geocode procedures to see that they work
-
If you are unsure if the provider is correctly configured try verify with:
CALL apoc.spatial.showConfig()Using Geocode within a bigger Cypher query
A more complex, or useful, example which geocodes addresses found in properties of nodes:
MATCH (a:Place)
WHERE exists(a.address)
CALL apoc.spatial.geocodeOnce(a.address) YIELD location
RETURN location.latitude AS latitude, location.longitude AS longitude, location.description AS descriptionCalculating distance between locations
If we wish to calculate the distance between addresses, we need to use the point() function to convert latitude and longitude to Cyper Point types, and then use the distance() function to calculate the distance:
WITH point({latitude: 48.8582532, longitude: 2.294287}) AS eiffel
MATCH (a:Place)
WHERE exists(a.address)
CALL apoc.spatial.geocodeOnce(a.address) YIELD location
WITH location, distance(point(location), eiffel) AS distance
WHERE distance < 5000
RETURN location.description AS description, distance
ORDER BY distance
LIMIT 100sortPathsByDistance
The second procedure enables you to sort a given collection of paths by the sum of their distance based on lat/long properties on the nodes.
Sample data :
CREATE (bruges:City {name:"bruges", latitude: 51.2605829, longitude: 3.0817189})
CREATE (brussels:City {name:"brussels", latitude: 50.854954, longitude: 4.3051786})
CREATE (paris:City {name:"paris", latitude: 48.8588376, longitude: 2.2773455})
CREATE (dresden:City {name:"dresden", latitude: 51.0767496, longitude: 13.6321595})
MERGE (bruges)-[:NEXT]->(brussels)
MERGE (brussels)-[:NEXT]->(dresden)
MERGE (brussels)-[:NEXT]->(paris)
MERGE (bruges)-[:NEXT]->(paris)
MERGE (paris)-[:NEXT]->(dresden)Finding paths and sort them by distance
MATCH (a:City {name:'bruges'}), (b:City {name:'dresden'})
MATCH p=(a)-[*]->(b)
WITH collect(p) as paths
CALL apoc.spatial.sortPathsByDistance(paths) YIELD path, distance
RETURN path, distanceGraph Refactoring
In order not to have to repeatedly geocode the same thing in multiple queries, especially if the database will be used by many people, it might be a good idea to persist the results in the database so that subsequent calls can use the saved results.
Geocode and persist the result
MATCH (a:Place)
WHERE exists(a.address) AND NOT exists(a.latitude)
WITH a LIMIT 1000
CALL apoc.spatial.geocodeOnce(a.address) YIELD location
SET a.latitude = location.latitude
SET a.longitude = location.longitudeNote that the above command only geocodes the first 1000 ‘Place’ nodes that have not already been geocoded. This query can be run multiple times until all places are geocoded. Why would we want to do this? Two good reasons:
-
The geocoding service is a public service that can throttle or blacklist sites that hit the service too heavily, so controlling how much we do is useful.
-
The transaction is updating the database, and it is wise not to update the database with too many things in the same transaction, to avoid using up too much memory. This trick will keep the memory usage very low.
Now make use of the results in distance queries
WITH point({latitude: 48.8582532, longitude: 2.294287}) AS eiffel
MATCH (a:Place)
WHERE exists(a.latitude) AND exists(a.longitude)
WITH a, distance(point(a), eiffel) AS distance
WHERE distance < 5000
RETURN a.name, distance
ORDER BY distance
LIMIT 100Combined Space and Time search
Combining spatial and date-time functions can allow for more complex queries:
WITH point({latitude: 48.8582532, longitude: 2.294287}) AS eiffel
MATCH (e:Event)
WHERE exists(e.address) AND exists(e.datetime)
CALL apoc.spatial.geocodeOnce(e.address) YIELD location
WITH e, location,
distance(point(location), eiffel) AS distance,
(apoc.date.parse('2016-06-01 00:00:00','h') - apoc.date.parse(e.datetime,'h'))/24.0 AS days_before_due
WHERE distance < 5000 AND days_before_due < 14 AND apoc.date.parse(e.datetime,'h') < apoc.date.parse('2016-06-01 00:00:00','h')
RETURN e.name AS event, e.datetime AS date,
location.description AS description, distance
ORDER BY distanceData Integration
Load JSON
Load JSON
Web APIs are a huge opportunity to access and integrate data from any sources with your graph. Most of them provide the data as JSON.
With apoc.load.json you can retrieve data from URLs and turn it into map value(s) for Cypher to consume.
Cypher is pretty good at deconstructing nested documents with dot syntax, slices, UNWIND etc. so it is easy to turn nested data into graphs.
Sources with multiple JSON objects in a stream are also supported, like the streaming Twitter format or the Yelp Kaggle dataset.
Json-Path
Most of the apoc.load.json and apoc.convert.*Json procedures and functions now accept a json-path as last argument.
The json-path uses the Java implementation by Jayway of Stefan Gössners JSON-Path
Here is some syntax, there are more examples at the links above.
$.store.book[0].title
| Operator | Description |
|---|---|
|
The root element to query. This starts all path expressions. |
|
The current node being processed by a filter predicate. |
|
Wildcard. Available anywhere a name or numeric are required. |
|
Deep scan. Available anywhere a name is required. |
|
Dot-notated child |
|
Bracket-notated child or children |
|
Array index or indexes |
|
Array slice operator |
|
Filter expression. Expression must evaluate to a boolean value. |
If used, this path is applied to the json and can be used to extract sub-documents and -values before handing the result to Cypher, resulting in shorter statements with complex nested JSON.
There is also a direct apoc.json.path(json,path) function.
Load JSON StackOverflow Example
There have been articles before about loading JSON from Web-APIs like StackOverflow.
With apoc.load.json it’s now very easy to load JSON data from any file or URL.
If the result is a JSON object is returned as a singular map. Otherwise if it was an array is turned into a stream of maps.
The URL for retrieving the last questions and answers of the neo4j tag is this:
Now it can be used from within Cypher directly, let’s first introspect the data that is returned.
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.items AS item
RETURN item.title, item.owner, item.creation_date, keys(item)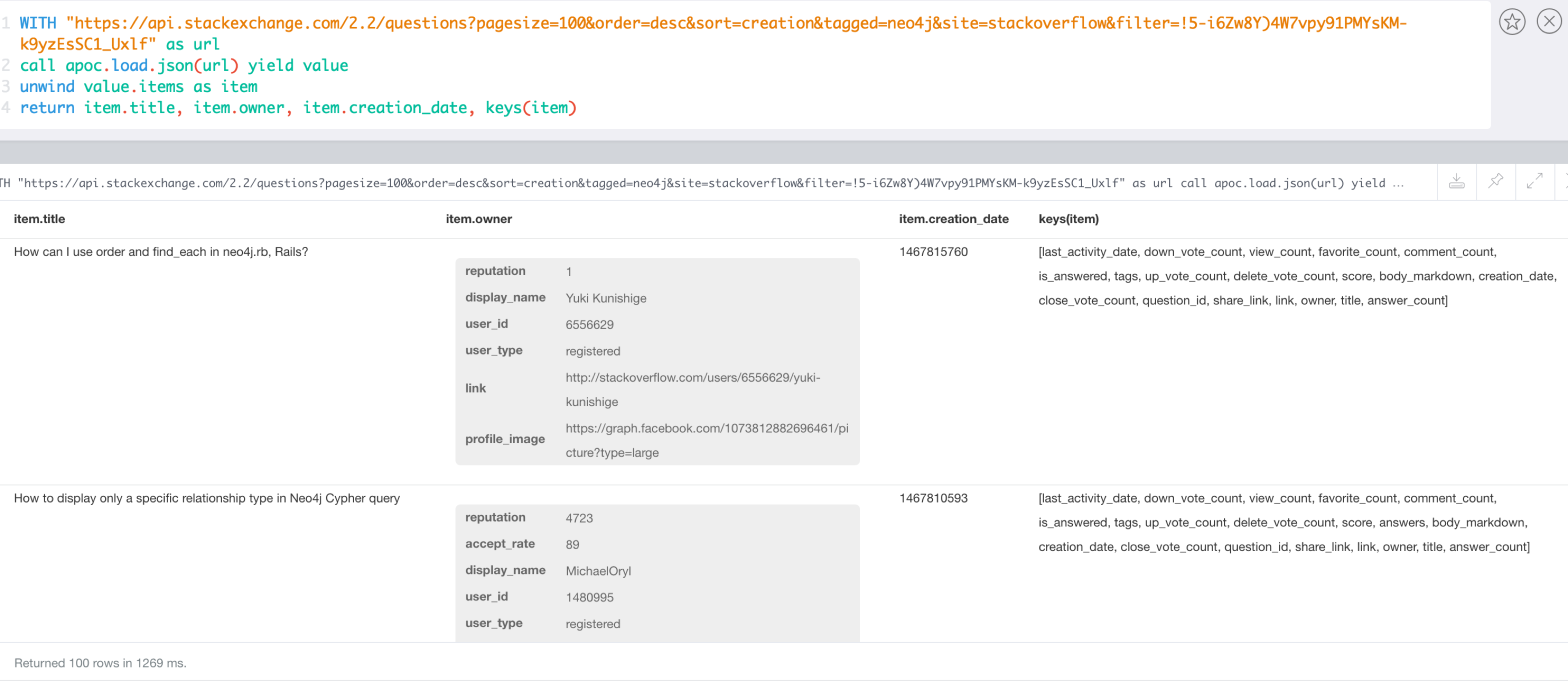
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url,'$.items.owner.name') YIELD value
RETURN name, count(*);Combined with the cypher query from the original blog post it’s easy to create the full Neo4j graph of those entities.
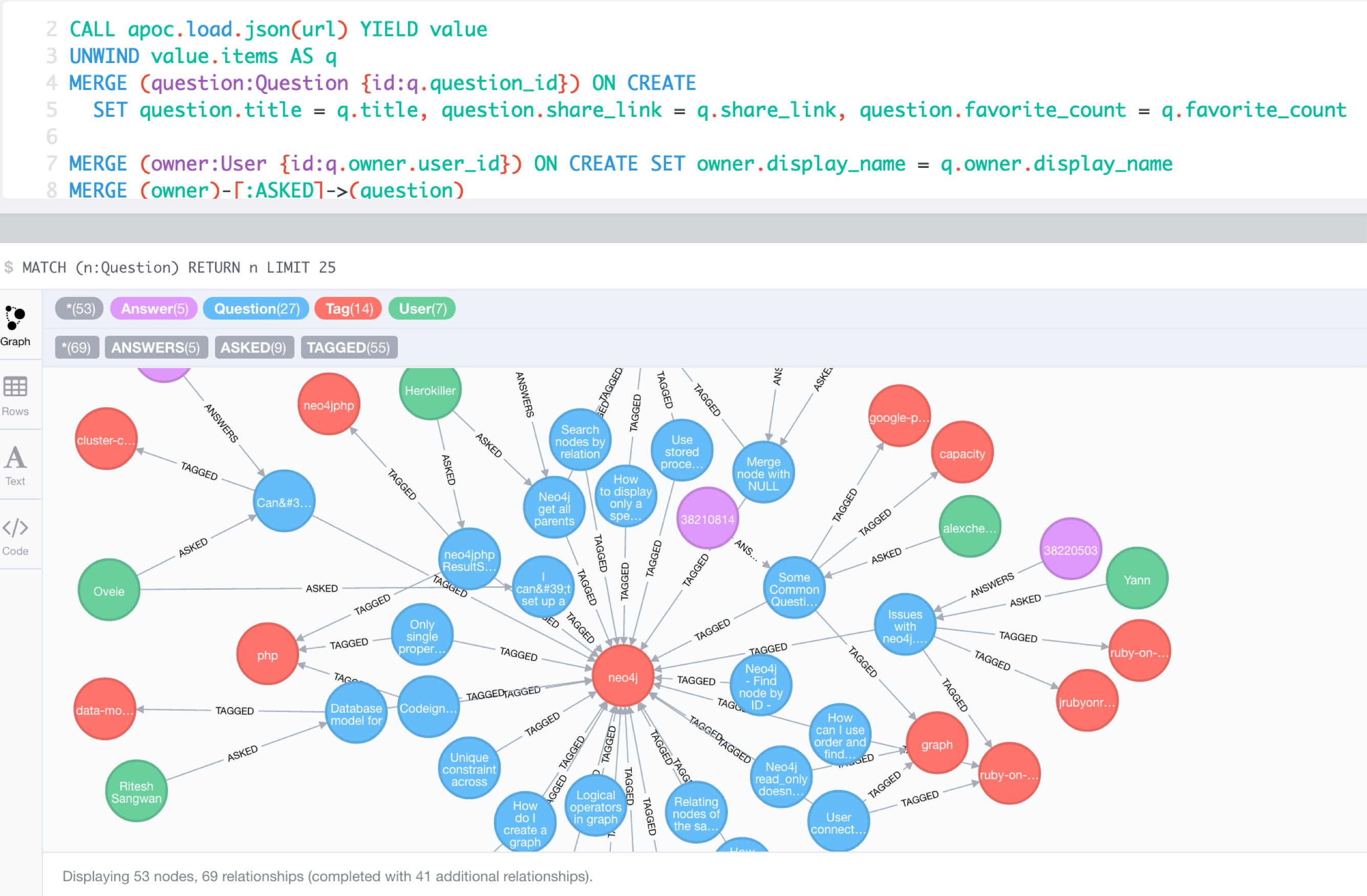
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.items AS q
MERGE (question:Question {id:q.question_id}) ON CREATE
SET question.title = q.title, question.share_link = q.share_link, question.favorite_count = q.favorite_count
MERGE (owner:User {id:q.owner.user_id}) ON CREATE SET owner.display_name = q.owner.display_name
MERGE (owner)-[:ASKED]->(question)
FOREACH (tagName IN q.tags | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag))
FOREACH (a IN q.answers |
MERGE (question)<-[:ANSWERS]-(answer:Answer {id:a.answer_id})
MERGE (answerer:User {id:a.owner.user_id}) ON CREATE SET answerer.display_name = a.owner.display_name
MERGE (answer)<-[:PROVIDED]-(answerer)
)
Load JSON from Twitter (with additional parameters)
With apoc.load.jsonParams you can send additional headers or payload with your JSON GET request, e.g. for the Twitter API:
Configure Bearer and Twitter Search Url token in neo4j.conf
apoc.static.twitter.bearer=XXXX apoc.static.twitter.url=https://api.twitter.com/1.1/search/tweets.json?count=100&result_type=recent&lang=en&q=
CALL apoc.static.getAll("twitter") yield value AS twitter
CALL apoc.load.jsonParams(twitter.url + "oscon+OR+neo4j+OR+%23oscon+OR+%40neo4j",{Authorization:"Bearer "+twitter.bearer},null) yield value
UNWIND value.statuses as status
WITH status, status.user as u, status.entities as e
RETURN status.id, status.text, u.screen_name, [t IN e.hashtags | t.text] as tags, e.symbols, [m IN e.user_mentions | m.screen_name] as mentions, [u IN e.urls | u.expanded_url] as urlsGeoCoding Example
Example for reverse geocoding and determining the route from one to another location.
WITH
"21 rue Paul Bellamy 44000 NANTES FRANCE" AS fromAddr,
"125 rue du docteur guichard 49000 ANGERS FRANCE" AS toAddr
call apoc.load.json("http://www.yournavigation.org/transport.php?url=http://nominatim.openstreetmap.org/search&format=json&q=" + replace(fromAddr, ' ', '%20')) YIELD value AS from
WITH from, toAddr LIMIT 1
call apoc.load.json("http://www.yournavigation.org/transport.php?url=http://nominatim.openstreetmap.org/search&format=json&q=" + replace(toAddr, ' ', '%20')) YIELD value AS to
CALL apoc.load.json("https://router.project-osrm.org/viaroute?instructions=true&alt=true&z=17&loc=" + from.lat + "," + from.lon + "&loc=" + to.lat + "," + to.lon ) YIELD value AS doc
UNWIND doc.route_instructions as instruction
RETURN instructionLoad JDBC
Overview: Database Integration
Data Integration is an important topic. Reading data from relational databases to create and augment data models is a very helpful exercise.
With apoc.load.jdbc you can access any database that provides a JDBC driver, and execute queries whose results are turned into streams of rows.
Those rows can then be used to update or create graph structures.
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.load.csv('url',{config}) YIELD lineNo, list, map - load CSV fom URL as stream of values, config contains any of: {skip:1,limit:5,header:false,sep:'TAB',ignore:['tmp'],arraySep:';',mapping:{years:{type:'int',arraySep:'-',array:false,name:'age',ignore:false}} |
procedure |
|
apoc.load.ldap("key" or {connectionMap},{searchMap}) Load entries from an ldap source (yield entry) |
To simplify the JDBC URL syntax and protect credentials, you can configure aliases in conf/neo4j.conf:
apoc.jdbc.myDB.url=jdbc:derby:derbyDB
CALL apoc.load.jdbc('jdbc:derby:derbyDB','PERSON')
becomes
CALL apoc.load.jdbc('myDB','PERSON')
The 3rd value in the apoc.jdbc.<alias>.url= effectively defines an alias to be used in apoc.load.jdbc('<alias>',….
MySQL Example
Northwind is a common example set for relational databases, which is also covered in our import guides, e.g. :play northwind graph in the Neo4j browser.
MySQL Northwind Data
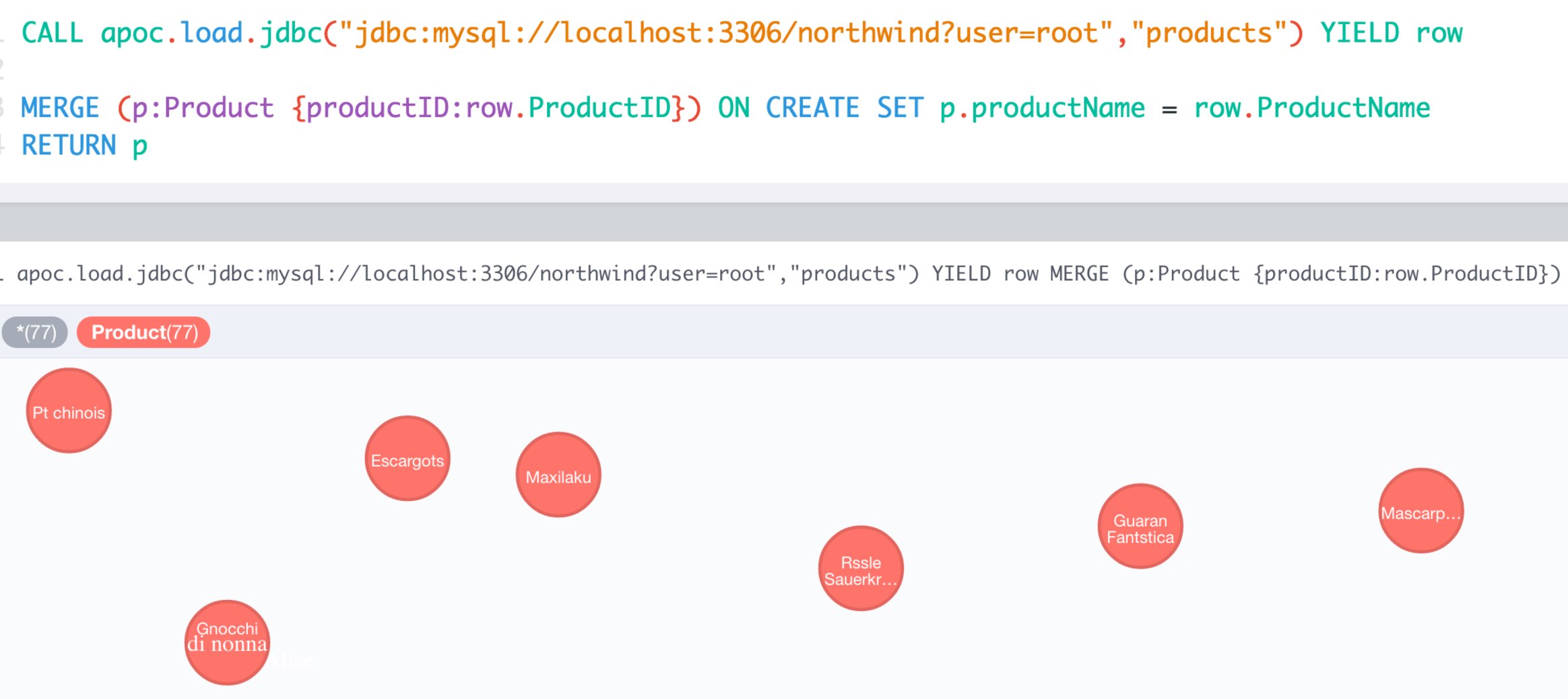
select count(*) from products; +----------+ | count(*) | +----------+ | 77 | +----------+ 1 row in set (0,00 sec)
describe products; +-----------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------------+---------------+------+-----+---------+----------------+ | ProductID | int(11) | NO | PRI | NULL | auto_increment | | ProductName | varchar(40) | NO | MUL | NULL | | | SupplierID | int(11) | YES | MUL | NULL | | | CategoryID | int(11) | YES | MUL | NULL | | | QuantityPerUnit | varchar(20) | YES | | NULL | | | UnitPrice | decimal(10,4) | YES | | 0.0000 | | | UnitsInStock | smallint(2) | YES | | 0 | | | UnitsOnOrder | smallint(2) | YES | | 0 | | | ReorderLevel | smallint(2) | YES | | 0 | | | Discontinued | bit(1) | NO | | b'0' | | +-----------------+---------------+------+-----+---------+----------------+ 10 rows in set (0,00 sec)
Load JDBC Examples
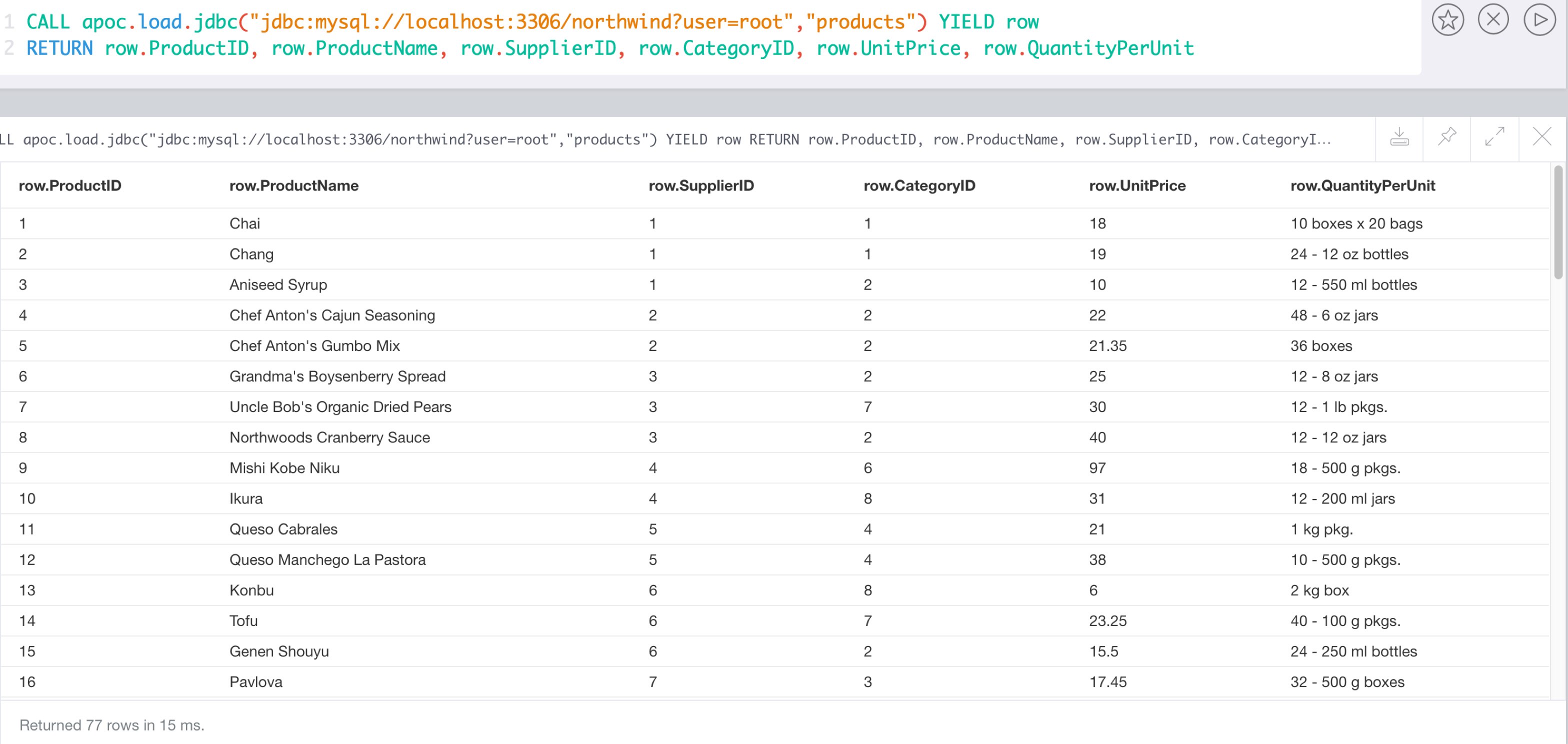
cypher CALL apoc.load.driver("com.mysql.jdbc.Driver");with "jdbc:mysql://localhost:3306/northwind?user=root" as url
cypher CALL apoc.load.jdbc(url,"products") YIELD row
RETURN count(*);+----------+ | count(*) | +----------+ | 77 | +----------+ 1 row 23 ms
with "jdbc:mysql://localhost:3306/northwind?user=root" as url
cypher CALL apoc.load.jdbc(url,"products") YIELD row
RETURN row limit 1;+--------------------------------------------------------------------------------+
| row |
+--------------------------------------------------------------------------------+
| {UnitPrice -> 18.0000, UnitsOnOrder -> 0, CategoryID -> 1, UnitsInStock -> 39} |
+--------------------------------------------------------------------------------+
1 row
10 ms
Load JDBC with params Examples
with "select firstname, lastname from employees where firstname like ? and lastname like ?" as sql
cypher call apoc.load.jdbcParams("northwind", sql, ['F%', '%w']) yield row
return row
JDBC pretends positional "?" for parameters, so the third apoc parameter has to be an array with values coherent with that positions. In case of 2 parameters, firstname and lastname ['firstname-position','lastname-position']
Load data in transactional batches
You can load data from jdbc and create/update the graph using the query results in batches (and in parallel).
CALL apoc.periodic.iterate('
call apoc.load.jdbc("jdbc:mysql://localhost:3306/northwind?user=root","company")',
'CREATE (p:Person) SET p += value', {batchSize:10000, parallel:true})
RETURN batches, totalCassandra Example
Setup Song database as initial dataset
curl -OL https://raw.githubusercontent.com/neo4j-contrib/neo4j-cassandra-connector/master/db_gen/playlist.cql curl -OL https://raw.githubusercontent.com/neo4j-contrib/neo4j-cassandra-connector/master/db_gen/artists.csv curl -OL https://raw.githubusercontent.com/neo4j-contrib/neo4j-cassandra-connector/master/db_gen/songs.csv $CASSANDRA_HOME/bin/cassandra $CASSANDRA_HOME/bin/cqlsh -f playlist.cql
Download the Cassandra JDBC Wrapper, and put it into your $NEO4J_HOME/plugins directory.
Add this config option to $NEO4J_HOME/conf/neo4j.conf to make it easier to interact with the cassandra instance.
apoc.jdbc.cassandra_songs.url=jdbc:cassandra://localhost:9042/playlist
Restart the server.
Now you can inspect the data in Cassandra with.
CALL apoc.load.jdbc('cassandra_songs','artists_by_first_letter') yield row
RETURN count(*);╒════════╕ │count(*)│ ╞════════╡ │3605 │ └────────┘
CALL apoc.load.jdbc('cassandra_songs','artists_by_first_letter') yield row
RETURN row LIMIT 5;CALL apoc.load.jdbc('cassandra_songs','artists_by_first_letter') yield row
RETURN row.first_letter, row.artist LIMIT 5;╒════════════════╤═══════════════════════════════╕ │row.first_letter│row.artist │ ╞════════════════╪═══════════════════════════════╡ │C │C.W. Stoneking │ ├────────────────┼───────────────────────────────┤ │C │CH2K │ ├────────────────┼───────────────────────────────┤ │C │CHARLIE HUNTER WITH LEON PARKER│ ├────────────────┼───────────────────────────────┤ │C │Calvin Harris │ ├────────────────┼───────────────────────────────┤ │C │Camané │ └────────────────┴───────────────────────────────┘
Let’s create some graph data, we have a look at the track_by_artist table, which contains about 60k records.
CALL apoc.load.jdbc('cassandra_songs','track_by_artist') yield row RETURN count(*);CALL apoc.load.jdbc('cassandra_songs','track_by_artist') yield row
RETURN row LIMIT 5;CALL apoc.load.jdbc('cassandra_songs','track_by_artist') yield row
RETURN row.track_id, row.track_length_in_seconds, row.track, row.music_file, row.genre, row.artist, row.starred LIMIT 2;╒════════════════════════════════════╤══════╤════════════════╤══════════════════╤═════════╤════════════════════════════╤═══════════╕ │row.track_id │length│row.track │row.music_file │row.genre│row.artist │row.starred│ ╞════════════════════════════════════╪══════╪════════════════╪══════════════════╪═════════╪════════════════════════════╪═══════════╡ │c0693b1e-0eaa-4e81-b23f-b083db303842│219 │1913 Massacre │TRYKHMD128F934154C│folk │Woody Guthrie & Jack Elliott│false │ ├────────────────────────────────────┼──────┼────────────────┼──────────────────┼─────────┼────────────────────────────┼───────────┤ │7d114937-0bc7-41c7-8e0c-94b5654ac77f│178 │Alabammy Bound │TRMQLPV128F934152B│folk │Woody Guthrie & Jack Elliott│false │ └────────────────────────────────────┴──────┴────────────────┴──────────────────┴─────────┴────────────────────────────┴───────────┘
Let’s create some indexes and constraints, note that other indexes and constraints will be dropped by this.
CALL apoc.schema.assert(
{Track:['title','length']},
{Artist:['name'],Track:['id'],Genre:['name']});╒════════════╤═══════╤══════╤═══════╕ │label │key │unique│action │ ╞════════════╪═══════╪══════╪═══════╡ │Track │title │false │CREATED│ ├────────────┼───────┼──────┼───────┤ │Track │length │false │CREATED│ ├────────────┼───────┼──────┼───────┤ │Artist │name │true │CREATED│ ├────────────┼───────┼──────┼───────┤ │Genre │name │true │CREATED│ ├────────────┼───────┼──────┼───────┤ │Track │id │true │CREATED│ └────────────┴───────┴──────┴───────┘
CALL apoc.load.jdbc('cassandra_songs','track_by_artist') yield row
MERGE (a:Artist {name:row.artist})
MERGE (g:Genre {name:row.genre})
CREATE (t:Track {id:toString(row.track_id), title:row.track, length:row.track_length_in_seconds})
CREATE (a)-[:PERFORMED]->(t)
CREATE (t)-[:GENRE]->(g);Added 63213 labels, created 63213 nodes, set 182413 properties, created 119200 relationships, statement executed in 40076 ms.
LOAD JDBC - Resources
To use other JDBC drivers use these download links and JDBC URL.
Put the JDBC driver into the $NEO4J_HOME/plugins directory and configure the JDBC-URL in $NEO4J_HOME/conf/neo4j.conf with apoc.jdbc.<alias>.url=<jdbc-url>
| Database | JDBC-URL | Driver Source |
|---|---|---|
MySQL |
|
|
Postgres |
|
|
Oracle |
|
|
MS SQLServer |
|
|
IBM DB2 |
|
|
Derby |
|
Included in JDK6-8 |
Cassandra |
|
There are a number of blog posts / examples that details usage of apoc.load.jdbc
Streaming Data to Gephi
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.gephi.add(url-or-key, workspace, data, weightproperty) | streams passed in data to Gephi |
Notes
Gephi has a streaming plugin, that can provide and accept JSON-graph-data in a streaming fashion.
Make sure to install the plugin firsrt and activate it for your workspace (there is a new "Streaming"-tab besides "Layout"), right-click "Master"→"start" to start the server.
You can provide your workspace name (you might want to rename it before you start thes streaming), otherwise it defaults to workspace0
The default Gephi-URL is http://localhost:8080, resulting in http://localhost:8080/workspace0?operation=updateGraph
You can also configure it in conf/neo4j.conf via apoc.gephi.url=url or apoc.gephi.<key>.url=url
Example
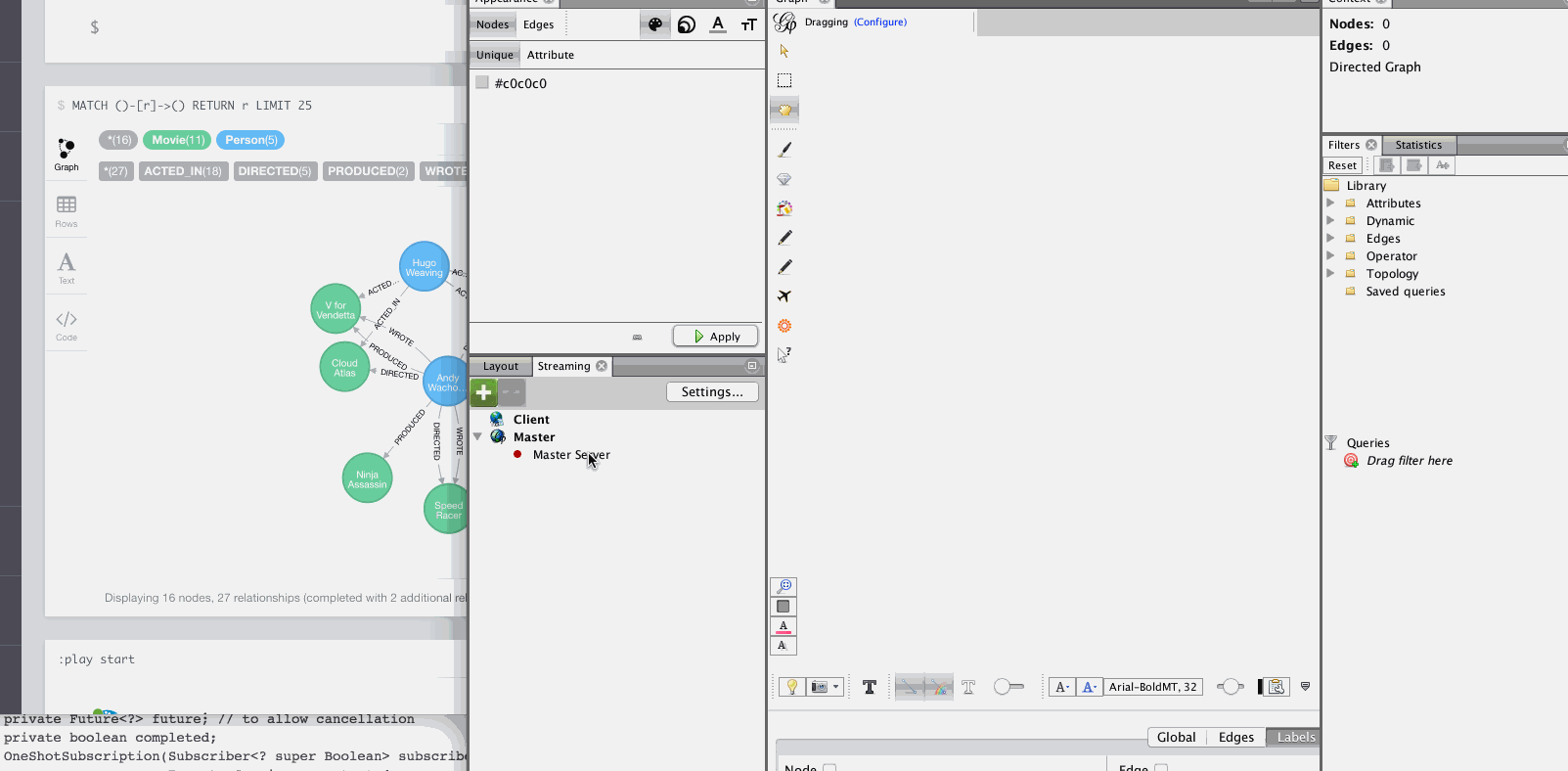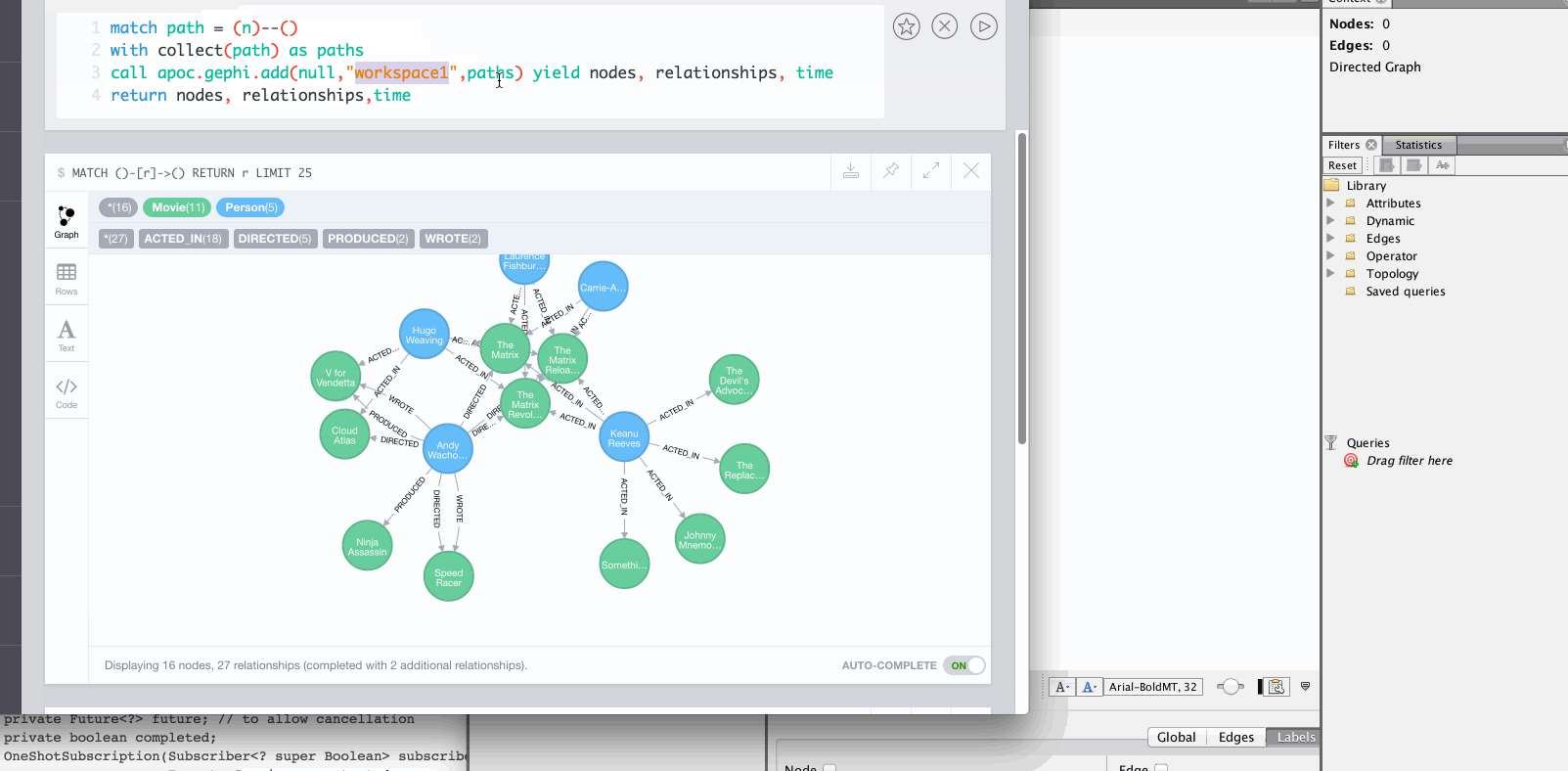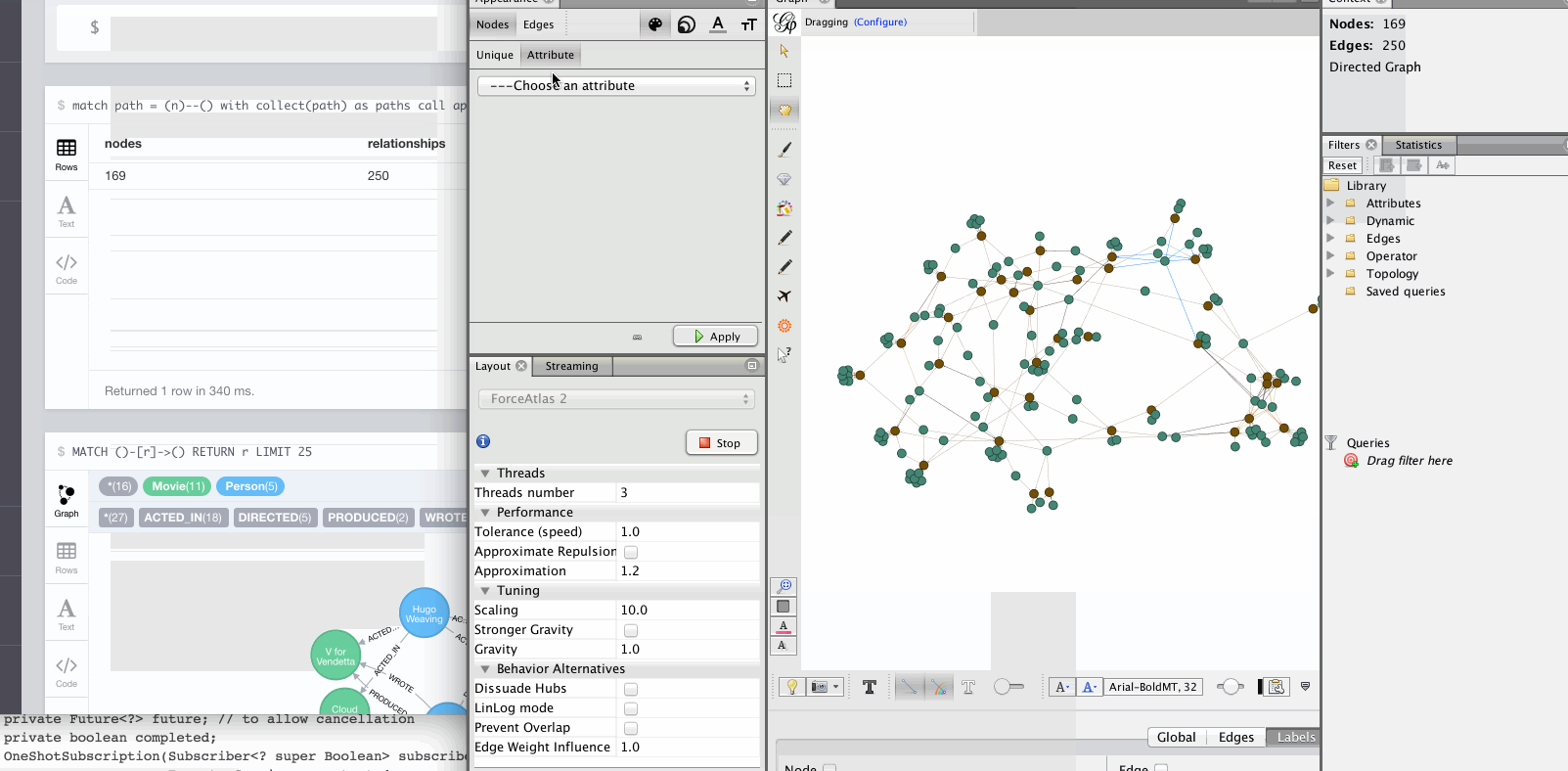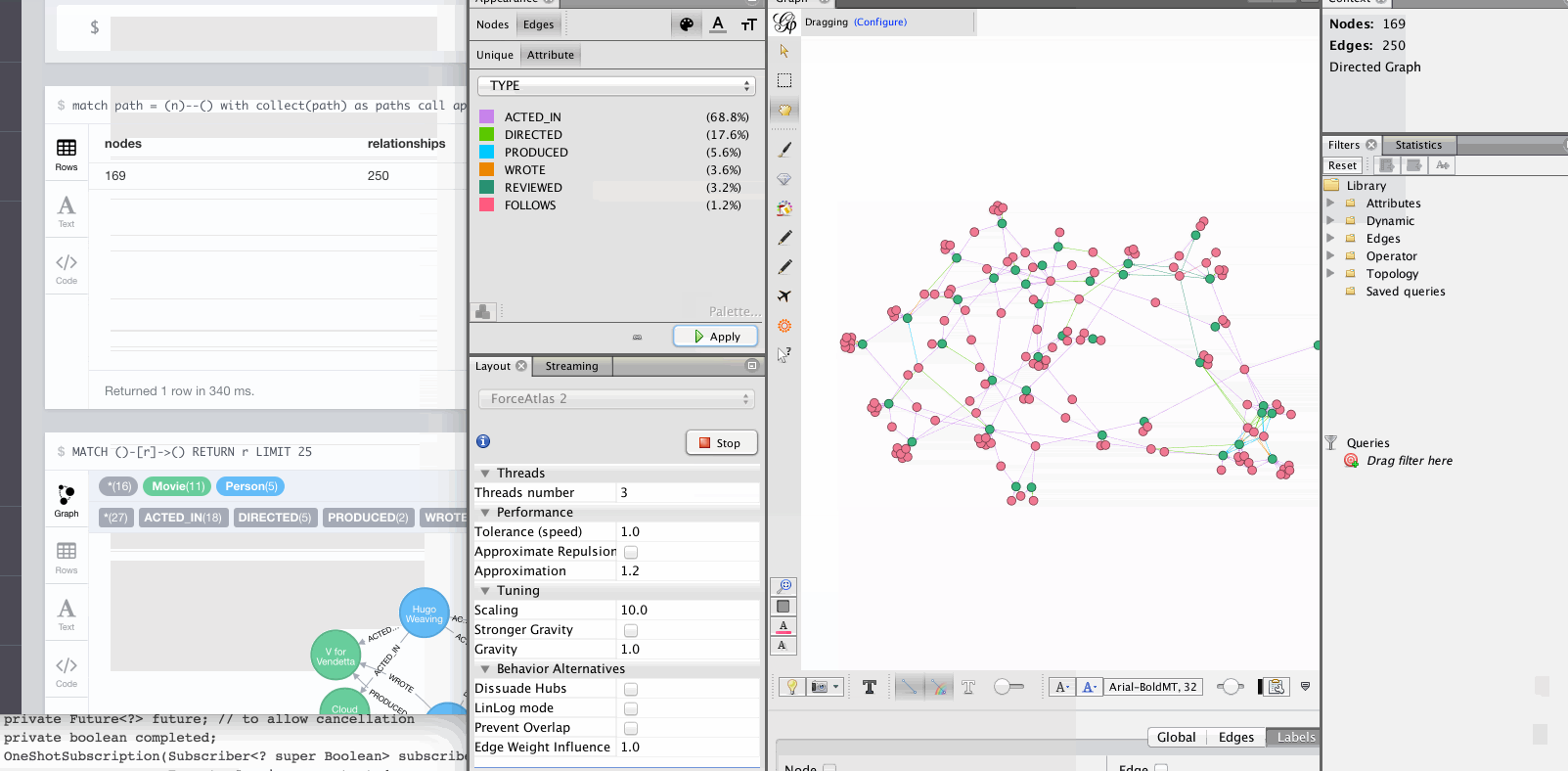
You can export your graph as an unweighted network.
match path = (:Person)-[:ACTED_IN]->(:Movie)
WITH path LIMIT 1000
with collect(path) as paths
call apoc.gephi.add(null,'workspace0', paths) yield nodes, relationships, time
return nodes, relationships, timeYou can export your graph as a weighted network, by specifying the property of a relationship, that holds the weight value.
match path = (:Person)-[r:ACTED_IN]->(:Movie) where exists r.weightproperty
WITH path LIMIT 1000
with collect(path) as paths
call apoc.gephi.add(null,'workspace0', paths, 'weightproperty') yield nodes, relationships, time
return nodes, relationships, timeFormat
We send all nodes and relationships of the passed in data convert into individual Gephi-Streaming JSON fragements, separated by \r\n.
{"an":{"123":{"TYPE":"Person:Actor","label":"Tom Hanks", x:333,y:222,r:0.1,g:0.3,b:0.5}}}\r\n
{"an":{"345":{"TYPE":"Movie","label":"Forrest Gump", x:234,y:122,r:0.2,g:0.2,b:0.7}}}\r\n
{"ae":{"3344":{"TYPE":"ACTED_IN","label":"Tom Hanks",source:"123",target:"345","directed":true,"weight":1.0,r:0.1,g:0.3,b:0.5}}}Specifics Details
Gephi doesn’t render the graph data unless you also provide x,y coordinates in the payload, so we just send random ones within a 1000x1000 grid.
We also generate colors per label combination and relationship-type, both of which are also transferred as TYPE property.
You can have your weight property stored as a number (integer,float) or a string. If the weight property is invalid or null, it will use the default 1.0 value.
ElasticSearch Integration
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.es.stats(host-url-Key) - elastic search statistics |
procedure |
|
apoc.es.get(host-or-port,index-or-null,type-or-null,id-or-null,query-or-null,payload-or-null) yield value - perform a GET operation on elastic search |
procedure |
|
apoc.es.query(host-or-port,index-or-null,type-or-null,query-or-null,payload-or-null) yield value - perform a SEARCH operation on elastic search |
procedure |
|
apoc.es.getRaw(host-or-port,path,payload-or-null) yield value - perform a raw GET operation on elastic search |
procedure |
|
apoc.es.postRaw(host-or-port,path,payload-or-null) yield value - perform a raw POST operation on elastic search |
procedure |
|
apoc.es.post(host-or-port,index-or-null,type-or-null,query-or-null,payload-or-null) yield value - perform a POST operation on elastic search |
procedure |
|
apoc.es.put(host-or-port,index-or-null,type-or-null,id-or-null,query-or-null,payload-or-null) yield value - perform a PUT operation on elastic search |
Example
call apoc.es.post("localhost","tweets","users","1",null,{name:"Chris"})call apoc.es.get("localhost","tweets","users","1",null,null)call apoc.es.stats("localhost")
Pagination
To use the pagination feature of Elasticsearch you have to follow these steps:
-
Call apoc.es.query to get the first chunk of data and obtain also the scroll_id (in order to enable the pagination).
-
Do your merge/create etc. operations with the first N hits
-
Use the range(start,end,step) function to repeat a second call to get all the other chunks until the end. For example, if you have 1000 documents and you want to retrieve 10 documents for each request, you cand do range(11,1000,10). You start from 11 because the first 10 documents are already processed. If you don’t know the exact upper bound (the total size of your documents) you can set a number that is bigger than the real total size.
-
The second call to repeat is apoc.es.get. Remember to set the scroll_id as a parameter.
-
Then process the result of each chunk of data as the first one.
Here an example:
// It's important to create an index to improve performance
CREATE INDEX ON :Document(id)
// First query: get first chunk of data + the scroll_id for pagination
CALL apoc.es.query('localhost','test-index','test-type','name:Neo4j&size=1&scroll=5m',null) yield value with value._scroll_id as scrollId, value.hits.hits as hits
// Do something with hits
UNWIND hits as hit
// Here we simply create a document and a relation to a company
MERGE (doc:Document {id: hit._id, description: hit._source.description, name: hit._source.name})
MERGE (company:Company {name: hit._source.company})
MERGE (doc)-[:IS_FROM]->(company)
// Then call for the other docs and use the scrollId value from previous query
// Use a range to count our chunk of data (i.e. i want to get chunks from 2 to 10)
WITH range(2,10,1) as list, scrollId
UNWIND list as count
CALL apoc.es.get("localhost","_search","scroll",null,{scroll:"5m",scroll_id:scrollId},null) yield value with value._scoll_id as scrollId, value.hits.hits as nextHits
// Again, do something with hits
UNWIND nextHits as hit
MERGE (doc:Document {id: hit._id, description: hit._source.description, name: hit._source.name})
MERGE (company:Company {name: hit._source.company})
MERGE (doc)-[:IS_FROM]->(company) return scrollId, doc, companyThis example was tested on a Mac Book Pro with 16GB of RAM. Loading 20000 documents from ES to Neo4j (100 documents for each request) took 1 minute.
General Structure and Parameters
call apoc.es.post(host-or-port,index-or-null,type-or-null,id-or-null,query-or-null,payload-or-null) yield value
// GET/PUT/POST url/index/type/id?query -d payloadhost or port parameter
The parameter can be a direct host or url, or an entry to be lookup up in neo4j.conf
-
host
-
host:port
-
lookup via key to apoc.es.<key>.url
-
lookup via key apoc.es.<key>.host
-
lookup apoc.es.url
-
lookup apoc.es.host
index parameter
Main ES index, will be sent directly, if null then "_all" multiple indexes can be separated by comma in the string.
type parameter
Document type, will be sent directly, if null then "_all" multiple types can be separated by comma in the string.
id parameter
Document id, will be left off when null.
query parameter
Query can be a map which is turned into a query string, a direct string or null then it is left off.
payload parameter
Payload can be a map which will be turned into a json payload or a string which will be sent directly or null.
Results
Results are stream of map in value.
Load XML
Load XML Introduction
Many existing (enterprise) applications, endpoints and files use XML as data exchange format.
To make these datastructures available to Cypher, you can use apoc.load.xml.
It takes a file or http URL and parses the XML into a map datastructure.
|
Note
|
in previous releases we’ve had apoc.load.xmlSimple. This is now deprecated and got superseeded by
apoc.load.xml(url, [xPath], [config], true).Simple XML Format
|
See the following usage-examples for the procedures.
Example File
"How do you access XML doc attributes in children fields ?"
(Thanks Nicolas Rouyer)
For example, if my XML file is the example book.xml provided by Microsoft.
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies,
...We have the file here, on GitHub.
Simple XML Format
In a simpler XML representation, each type of children gets it’s own entry within the parent map. The element-type as key is prefixed with "_" to prevent collisions with attributes.
If there is a single element, then the entry will just have that element as value, not a collection. If there is more than one element there will be a list of values.
Each child will still have its _type field to discern them.
Here is the example file from above loaded with apoc.load.xmlSimple
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml", '', {}, true){_type: "catalog", _book: [
{_type: "book", id: "bk101",
_author: [{_type: "author", _text: "Gambardella, Matthew"},{_type: author, _text: "Arciniegas, Fabio"}],
_title: {_type: "title", _text: "XML Developer's Guide"},
_genre: {_type: "genre", _text: "Computer"},
_price: {_type: "price", _text: "44.95"},
_publish_date: {_type: "publish_date", _text: "2000-10-01"},
_description: {_type: description, _text: An in-depth look at creating applications ....Simple XML Examples
WITH "https://maps.googleapis.com/maps/api/directions/xml?origin=Mertens%20en%20Torfsstraat%2046,%202018%20Antwerpen&destination=Rubensstraat%2010,%202300%20Turnhout&sensor=false&mode=bicycling&alternatives=false&key=AIzaSyAPPIXGudOyHD_KAa2f_1l_QVNbsd_pMQs" AS url
CALL apoc.load.xmlSimple(url) YIELD value
RETURN value._route._leg._distance._value, keys(value), keys(value._route), keys(value._route._leg), keys(value._route._leg._distance._value)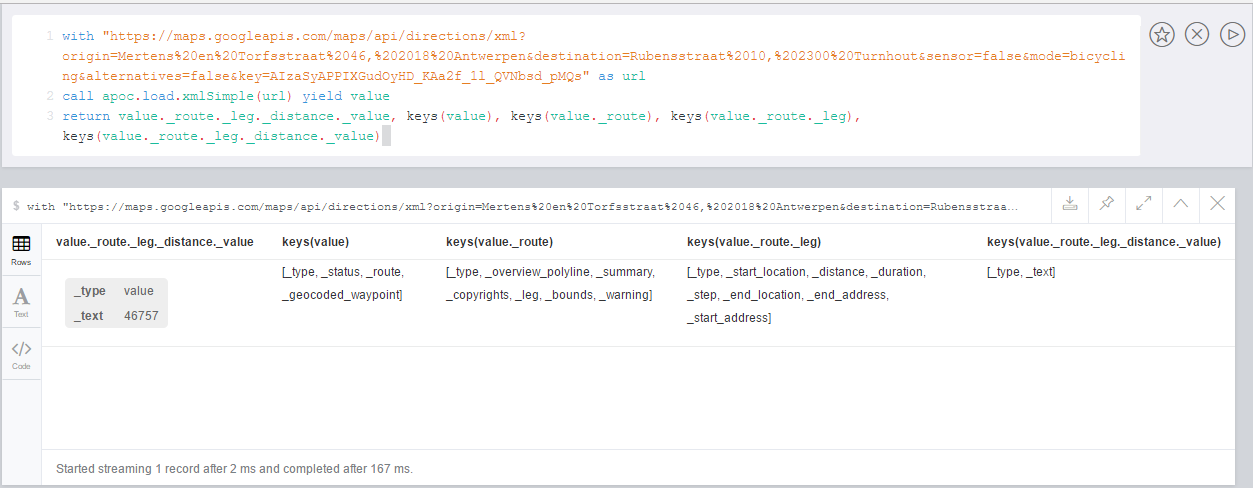
WITH "https://maps.googleapis.com/maps/api/directions/xml?origin=Mertens%20en%20Torfsstraat%2046,%202018%20Antwerpen&destination=Rubensstraat%2010,%202300%20Turnhout&sensor=false&mode=bicycling&alternatives=false&key=AIzaSyAPPIXGudOyHD_KAa2f_1l_QVNbsd_pMQs" AS url
CALL apoc.load.xmlSimple(url) YIELD value
UNWIND keys(value) AS key
RETURN key, apoc.meta.type(value[key]);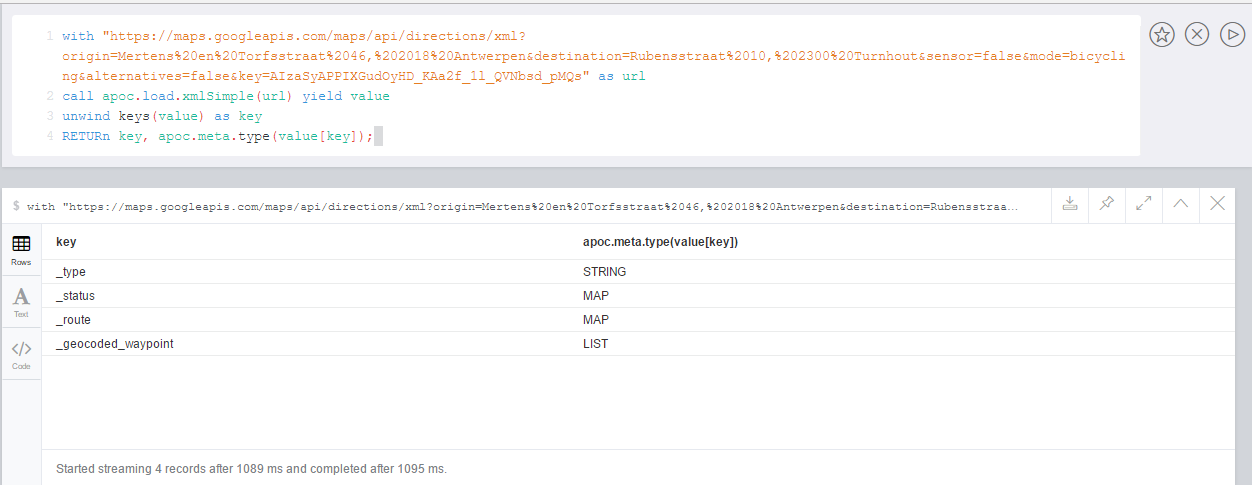
xPath
It’s possible to define a xPath (optional) to selecting nodes from the XML document.
xPath Example
From the Microsoft’s book.xml file we can get only the books that have as genre Computer
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.1/src/test/resources/books.xml", '/catalog/book[genre=\"Computer\"]') yield value as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['title','price'] | attr._text] as pairs
RETURN id, pairs[0] as title, pairs[1] as price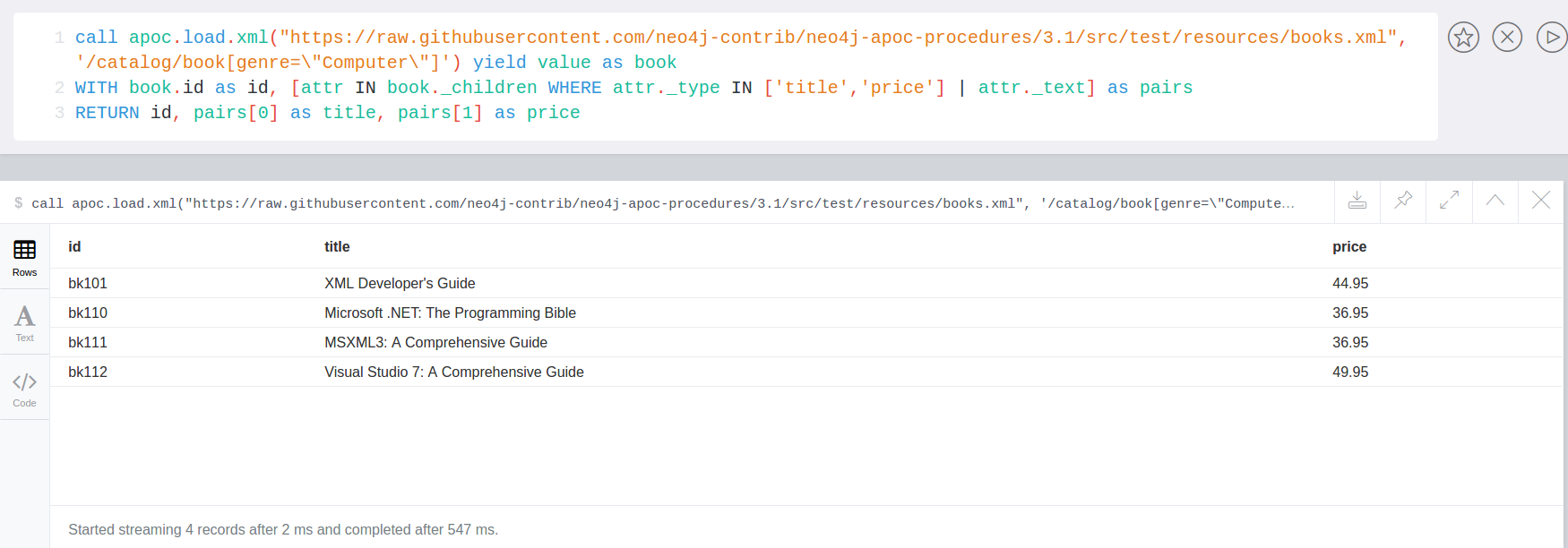
In this case we return only id, title and prize but we can return any other elements
We can also return just a single specific element.
For example the author of the book with id = bg102
call apoc.load.xml('https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.1/src/test/resources/books.xml', '/catalog/book[@id="bk102"]/author') yield value as result
WITH result._text as author
RETURN author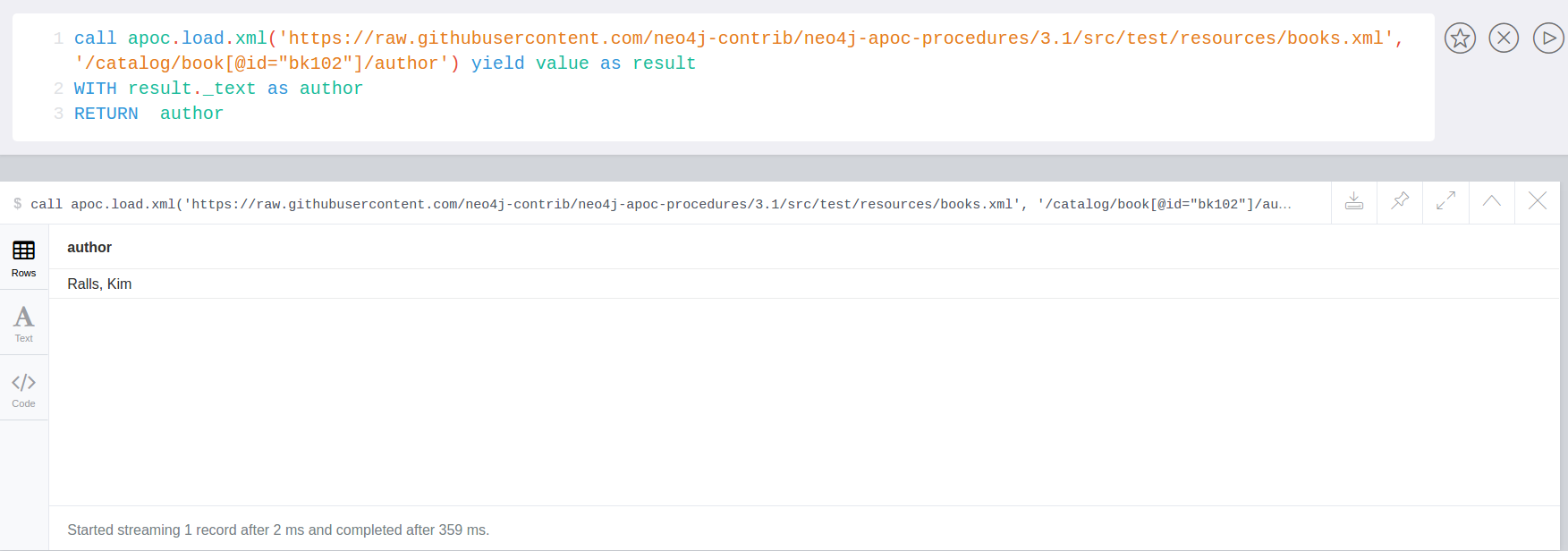
Load XML and Introspect
Let’s just load it and see what it looks like.
It’s returned as value map with nested _type and _children fields, per group of elements.
Attributes are turned into map-entries.
And each element into their own little map with _type, attributes and _children if applicable.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml"){_type: catalog, _children: [
{_type: book, id: bk101, _children: [
{_type: author, _text: Gambardella, Matthew},
{_type: title, _text: XML Developer's Guide},
{_type: genre, _text: Computer},
{_type: price, _text: 44.95},
{_type: publish_date, _text: 2000-10-01},
{_type: description, _text: An in-depth look at creating applications ....For each book, how do I access book id ?
You can access attributes per element directly.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml") yield value as catalog
UNWIND catalog._children as book
RETURN book.id╒═══════╕ │book.id│ ╞═══════╡ │bk101 │ ├───────┤ │bk102 │
For each book, how do I access book author and title ?
Filter into collection
You have to filter over the sub-elements in the _childrens array in this case.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml") yield value as catalog
UNWIND catalog._children as book
RETURN book.id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs╒═══════╤════════════════════════════════════════════════════════════════════════╕ │book.id│pairs │ ╞═══════╪════════════════════════════════════════════════════════════════════════╡ │bk101 │[[author, Gambardella, Matthew], [title, XML Developer's Guide]] │ ├───────┼────────────────────────────────────────────────────────────────────────┤ │bk102 │[[author, Ralls, Kim], [title, Midnight Rain]] │
How do I return collection elements?
This is not too nice, we could also just have returned the values and then grabbed them out of the list, but that relies on element-order.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | attr._text] as pairs
RETURN id, pairs[0] as author, pairs[1] as title╒═════╤════════════════════╤══════════════════════════════╕ │id │author │title │ ╞═════╪════════════════════╪══════════════════════════════╡ │bk101│Gambardella, Matthew│XML Developer's Guide │ ├─────┼────────────────────┼──────────────────────────────┤ │bk102│Ralls, Kim │Midnight Rain │
Extracting Datastructures
Turn Pairs into Map
So better is to turn them into a map with apoc.map.fromPairs
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs
CALL apoc.map.fromPairs(pairs) yield value
RETURN id, value╒═════╤════════════════════════════════════════════════════════════════════╕
│id │value │
╞═════╪════════════════════════════════════════════════════════════════════╡
│bk101│{author: Gambardella, Matthew, title: XML Developer's Guide} │
├─────┼────────────────────────────────────────────────────────────────────┤
│bk102│{author: Ralls, Kim, title: Midnight Rain} │
├─────┼────────────────────────────────────────────────────────────────────┤
│bk103│{author: Corets, Eva, title: Maeve Ascendant} │
Return individual Columns
And now we can cleanly access the attributes from the map.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/master/src/test/resources/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs
CALL apoc.map.fromPairs(pairs) yield value
RETURN id, value.author, value.title╒═════╤════════════════════╤══════════════════════════════╕ │id │value.author │value.title │ ╞═════╪════════════════════╪══════════════════════════════╡ │bk101│Gambardella, Matthew│XML Developer's Guide │ ├─────┼────────────────────┼──────────────────────────────┤ │bk102│Ralls, Kim │Midnight Rain │ ├─────┼────────────────────┼──────────────────────────────┤ │bk103│Corets, Eva │Maeve Ascendant │
Graph Refactorings
Graph Refactoring Procedures
These procedures help refactor the structure of your graph. This is helpful when you need to change your data model or for cleaning up data that was imported from an external source.
Normalize boolean properties
Given raw data boolean properties are often represented by placeholder values. This procedure turns them into boolean properties.
Will be true if "Y", YES"; false if "N", "NO"; null otherwise:
MATCH (n)
CALL apoc.refactor.normalizeAsBoolean(n, "prop", ["Y", "YES"], ["N", NO"])
RETURN n.propCategorization
Categorize replaces string property values on nodes with relationship to a unique category node for that property value.
This example will turn all n.color properties into :HAS_ATTRIBUTE relationships to :Color nodes with a matching .colour property.
CALL apoc.refactor.categorize('color','HAS_ATTRIBUTE',true,'Color','colour',['popularity'],1)Additionally, it will also copy over the first 'popularity' property value encountered on any node n for each newly created :Color node and remove any occurrences of that property value on nodes with the same 'Color'.
Using Cypher and APOC to move a property value to a label
You can use the procedure apoc.create.addLabels to move a property to a label with Cypher as follows
CREATE (:Movie {title: 'A Few Good Men', genre: 'Drama'})MATCH (n:Movie)
CALL apoc.create.addLabels( id(n), [ n.genre ] ) YIELD node
REMOVE node.genre
RETURN nodeCypher Operations
Running Cypher fragments
We can use Cypher as safe, graph-aware, partially compiled scripting language within APOC.
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.cypher.run(fragment, params) yield value - executes reading fragment with the given parameters |
procedure |
|
apoc.cypher.runFile(file or url) - runs each statement in the file, all semicolon separated - currently no schema operations |
procedure |
|
apoc.cypher.runFiles([files or urls]) - runs each statement in the files, all semicolon separated |
procedure |
|
apoc.cypher.runSchemaFile(file or url) - allows only schema operations, runs each schema statement in the file, all semicolon separated |
procedure |
|
apoc.cypher.runSchemaFiles([files or urls]) - allows only schema operations, runs each schema statement in the files, all semicolon separated |
procedure |
|
apoc.cypher.runMany('cypher;\nstatements;',{params}) - runs each semicolon separated statement and returns summary - currently no schema operations |
procedure |
|
|
procedure |
|
apoc.cypher.mapParallel(fragment, params, list-to-parallelize) yield value - executes fragment in parallel batches with the list segments being assigned to _ |
procedure |
|
apoc.cypher.mapParallel2(fragment, params, list-to-parallelize) yield value - executes fragment in parallel batches with the list segments being assigned to _ |
procedure |
|
|
procedure |
|
apoc.cypher.doIt(fragment, params) yield value - executes writing fragment with the given parameters |
procedure |
|
apoc.cypher.runTimeboxed('cypherStatement',{params}, timeout) - abort statement after timeout ms if not finished |
procedure |
|
apoc.when(condition, ifQuery, elseQuery:'', params:{}) yield value - based on the conditional, executes read-only ifQuery or elseQuery with the given parameters |
procedure |
|
apoc.do.when(condition, ifQuery, elseQuery:'', params:{}) yield value - based on the conditional, executes writing ifQuery or elseQuery with the given parameters |
procedure |
|
apoc.case([condition, query, condition, query, …], elseQuery:'', params:{}) yield value - given a list of conditional / read-only query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
procedure |
|
apoc.do.case([condition, query, condition, query, …], elseQuery:'', params:{}) yield value - given a list of conditional / writing query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
function |
|
apoc.cypher.runFirstColumn(statement, params, expectMultipleValues) - executes statement with given parameters, returns first column only, if expectMultipleValues is true will collect results into an array |
Example: Fast Node-Counts by Label
Counts by label are quickly provided by the counts-store, but only if they are the the single thing in the query, like
MATCH (:Person) RETURN count(*);It also works to combine several with UNION ALL, but not via WITH
MATCH (:Person) WITH count(*) as people
MATCH (:Movie) RETURN people, count(*) as movies;MATCH (:Person) RETURN count(*)
UNION ALL
MATCH (:Movie) RETURN count(*);But with apoc.cypher.run we can construct the statement and run each of them individually, so it completes in a few ms.
call db.labels() yield label
call apoc.cypher.run("match (:`"+label+"`) return count(*) as count", null) yield value
return label, value.count as countYou can use a similar approach to get the property-keys per label:
CALL db.labels() yield label
call apoc.cypher.run("MATCH (n:`"+label+"`) RETURN keys(n) as keys LIMIT 1",null) yield value
RETURN label, value.keys as keysRunning a cypher statement timeboxed
There’s a way to terminate a cypher statement if it takes longer than a given threshold. Consider an expensive statement calculating cross product of shortestpaths for each pair of nodes:
call apoc.cypher.runTimeboxed("match (n),(m) match p=shortestPath((n)-[*]-(m)) return p", null, 10000) yield value
return value.pConditional cypher execution
Sometimes queries require conditional execution logic that can’t be adequately expressed in Cypher, even with CASE.
APOC’s conditional execution procedures simulate an if / else structure, where a supplied boolean condition determines which cypher query is executed.
WHEN Procedures
|
based on the condition, executes read-only ifQuery or elseQuery with the given parameters |
|
based on the condition, executes writing ifQuery or elseQuery with the given parameters |
For example, if we wanted to match to neighbor nodes one and two traversals away from a start node, and return the smaller set (either those one hop away, or those that are two hops away), we might use:
MATCH (start:Node)-[:REL]->(a)-[:REL]->(b)
WITH collect(distinct a) as aNodes, collect(distinct b) as bNodes
CALL apoc.when(size(aNodes) <= size(bNodes), 'RETURN aNodes as resultNodes', 'RETURN bNodes as resultNodes', {aNodes:aNodes, bNodes:bNodes}) YIELD value
RETURN value.resultNodes as resultNodesOr, if we wanted to conditionally set or create graph elements if we deem some account to be suspicious, but still want to continue other query operations in either case, we could use apoc.do.when:
MATCH (acc:Account)
OPTIONAL MATCH (acc)-[r:ACCESSED_BY]->(suspect:User)
WHERE suspect.id in {suspiciousUsersIdList}
CALL apoc.do.when(r IS NOT NULL, 'SET acc:Suspicious', '', {acc:acc}) YIELD value
// ignore value and continue
WITH acc
...CASE Procedures
For more complex conditional logic, case procedures allow for a variable-length list of condition / query pairs, where the query following the first conditional evaluating to true is executed. An elseQuery block is executed if none of the conditionals are true.
|
given a list of conditional / read-only query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
|
given a list of conditional / writing query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
If we wanted to MATCH to selection nodes in a column, we could use entirely different MATCHES depending on query parameters, or based on data already in the graph:
MATCH (me:User{id:{myId}})
CALL apoc.case(
[{selection} = 'friends', "RETURN [(me)-[:FRIENDS]-(friend) | friend] as selection",
{selection} = 'coworkers', "RETURN [(me)-[:WORKS_AT*2]-(coworker) | coworker] as selection",
{selection} = 'all', "RETURN apoc.coll.union([(me)-[:FRIENDS]-(friend) | friend], [(me)-[:WORKS_AT*2]-(coworker) | coworker]) as selection"],
'RETURN [] as selection', {me:me}) YIELD value
RETURN value.selection as selectionJob management and periodic execution
Introduction asynchronous transactional execution
|
Note
|
this document is work in progress |
Cypher is great for querying graphs and importing and updating graph structures.
While during imports you can use PERIODIC COMMIT to control transaction sizes in memory,
for other graph refactorings it’s not that easy to commit transactions regularly to free memory for new update state.
Also sometimes you want to schedule execution of Cypher statements to run regularly in the background or asynchronously ("fire & forget").
The apoc.periodic.* procedures provide such capabilities.
Many procedures run in the background or asynchronously. This setting overrides the default thread pool size (processors*2).
apoc.jobs.default.num_threads=10
Many periodic procedures rely on a scheduled executor that has a pool of threads with a default fixed size (processors/4, at least 1). You can configure the pool size using the following configuration property:
apoc.jobs.scheduled.num_threads=10
apoc.periodic.iterate
With apoc.periodic.iterate you provide 2 statements, the first outer statement is providing a stream of values to be processed.
The second, inner statement processes one element at a time or with iterateList:true the whole batch at a time.
The results of the outer statement are passed into the inner statement as parameters, they are automatically made available with their names.
| param | default | description |
|---|---|---|
batchSize |
1000 |
that many inner statements are run within a single tx params: {_count, _batch} |
parallel |
false |
run inner statement in parallel, note that statements might deadlock |
retries |
0 |
if the inner statement fails with an error, sleep 100ms and retry until retries-count is reached, param {_retry} |
iterateList |
false |
the inner statement is only executed once but the whole batchSize list is passed in as parameter {_batch} |
params |
{} |
externally passed in map of params |
|
Note
|
We plan to make iterateList:true the default in upcoming releases, due to the automatic UNWINDing and providing of nested results as variables,
most queries should continue work.
|
So if you were to add an :Actor label to several million :Person nodes, you would run:
CALL apoc.periodic.iterate(
"MATCH (p:Person) WHERE (p)-[:ACTED_IN]->() RETURN p",
"SET p:Actor", {batchSize:10000, parallel:true})Which would take 10k people from the stream and update them in a single transaction, executing the second statement for each person.
Those executions can happen in parallel as updating node-labels or properties doesn’t conflict.
If you do more complex operations like updating or removing relationships, either don’t use parallel OR make sure that you batch the work in a way that each subgraph of data is updated in one operation, e.g. by transferring the root objects.
If you attempt complex operations, try to use e.g. retries:3 to retry failed operations.
CALL apoc.periodic.iterate(
"MATCH (o:Order) WHERE o.date > '2016-10-13' RETURN o",
"MATCH (o)-[:HAS_ITEM]->(i) WITH o, sum(i.value) as value SET o.value = value", {batchSize:100, parallel:true})CALL apoc.periodic.iterate(
"MATCH (o:Order) WHERE o.date > '2016-10-13' RETURN o",
"MATCH (o)-[:HAS_ITEM]->(i) WITH o, sum(i.value) as value SET o.value = value", {batchSize:100, iterateList:true, parallel:true})The stream of other data can also come from another source, like a different database, CSV or JSON file.
apoc.periodic.commit
Especially for graph processing it is useful to run a query repeatedly in separate transactions until it doesn’t process and generates any results anymore. So you can iterate in batches over elements that don’t fulfill a condition and update them so that they do afterwards.
The query is executed repatedly in separate transactions until it returns 0.
call apoc.periodic.commit("
match (user:User) WHERE exists( user.city )
with user limit {limit}
MERGE (city:City {name:user.city})
MERGE (user)-[:LIVES_IN]->(city)
REMOVE user.city
RETURN count(*)
",{limit:10000})+=======+==========+ |updates|executions| +=======+==========+ |2000000|200 | +-------+----------+
apoc.periodic.countdown
Repeats a statement until the termination is reached. The statement must return a numeric value and it should decrement (like a monotonically decreasing function). When the return value reaches 0 than the iteration stops. For example, define a counter with a numeric property:
CREATE (counter:Counter) SET counter.c = 10and decrement this property by 1 each second:
CALL apoc.periodic.countdown('decrement',"MATCH (counter:Counter) SET counter.c = counter.c - 1 RETURN counter.c as count", 1)Further Functions
| type | qualified name | description |
|---|---|---|
procedure |
|
apoc.periodic.list - list all jobs |
procedure |
|
apoc.periodic.commit(statement,params) - runs the given statement in separate transactions until it returns 0 |
procedure |
|
apoc.periodic.cancel(name) - cancel job with the given name |
procedure |
|
apoc.periodic.submit('name',statement) - submit a one-off background statement |
procedure |
|
apoc.periodic.repeat('name',statement,repeat-rate-in-seconds) submit a repeatedly-called background statement |
procedure |
|
apoc.periodic.countdown('name',statement,repeat-rate-in-seconds) submit a repeatedly-called background statement until it returns 0 |
procedure |
|
apoc.periodic.rock_n_roll_while('some cypher for knowing when to stop', 'some cypher for iteration', 'some cypher as action on each iteration', 10000) YIELD batches, total - run the action statement in batches over the iterator statement’s results in a separate thread. Returns number of batches and total processed rows |
procedure |
|
apoc.periodic.iterate('statement returning items', 'statement per item', {batchSize:1000,iterateList:false,parallel:true}) YIELD batches, total - run the second statement for each item returned by the first statement. Returns number of batches and total processed rows |
procedure |
|
apoc.periodic.rock_n_roll('some cypher for iteration', 'some cypher as action on each iteration', 10000) YIELD batches, total - run the action statement in batches over the iterator statement’s results in a separate thread. Returns number of batches and total processed rows |
-
there are also static methods
Jobs.submit, andJobs.scheduleto be used from other procedures -
jobs list is checked / cleared every 10s for finished jobs
Virtual
Virtual Nodes/Rels
Virtual Nodes and Relationships don’t exist in the graph, they are only returned to the UI/user for representing a graph projection. They can be visualized or processed otherwise. Please note that they have negative id’s.
|
returns a virtual node |
|
returns a virtual node |
|
returns virtual nodes |
|
returns a virtual relationship |
|
returns a virtual relationship |
|
returns a virtual pattern |
|
returns a virtual pattern |
Virtual Nodes/Rels Example
vNode, vRelationshipFrom a simple dataset
CREATE(a:Person)-[r:ACTED_IN]->(b:Movie)We can create a virtual copy, adding as attribute name the labels value
MATCH (a)-[r]->(b)
WITH head(labels(a)) AS l, head(labels(b)) AS l2, type(r) AS rel_type, count(*) as count
CALL apoc.create.vNode([l],{name:l}) yield node as a
CALL apoc.create.vNode([l2],{name:l2}) yield node as b
CALL apoc.create.vRelationship(a,rel_type,{count:count},b) yield rel
RETURN *;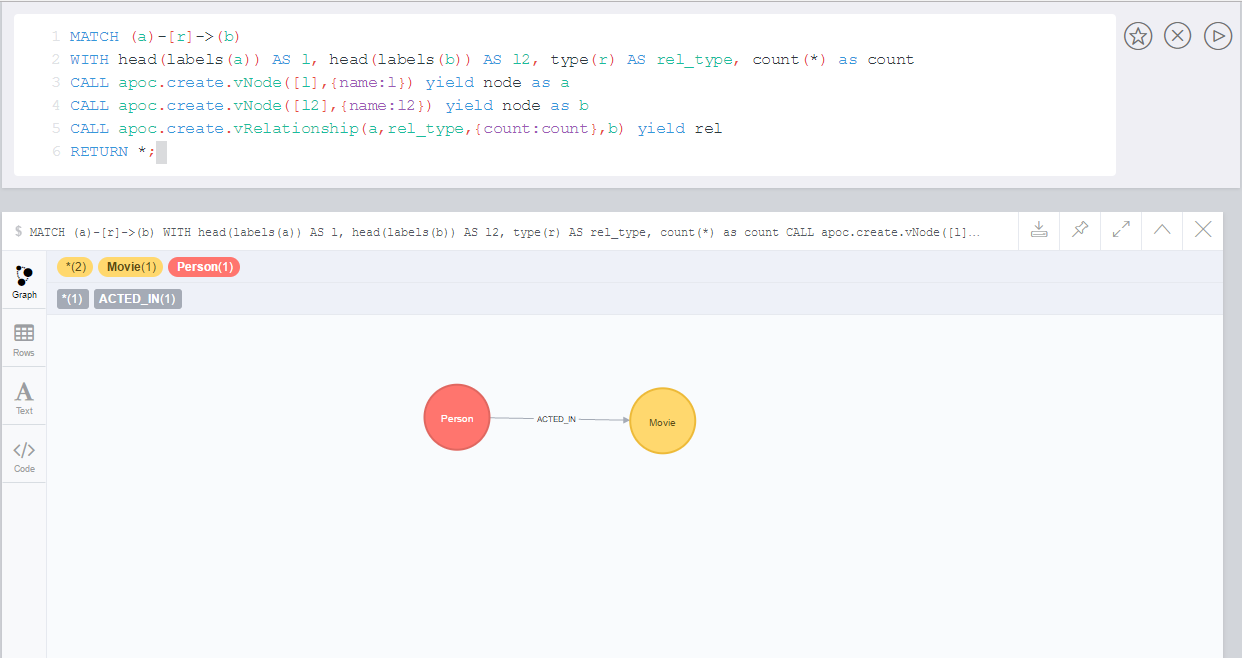
Virtual nodes and virtual relationships have always a negative id

vPatternCALL apoc.create.vPattern({_labels:['Person'],name:'Mary'},'KNOWS',{since:2012},{_labels:['Person'],name:'Michael'})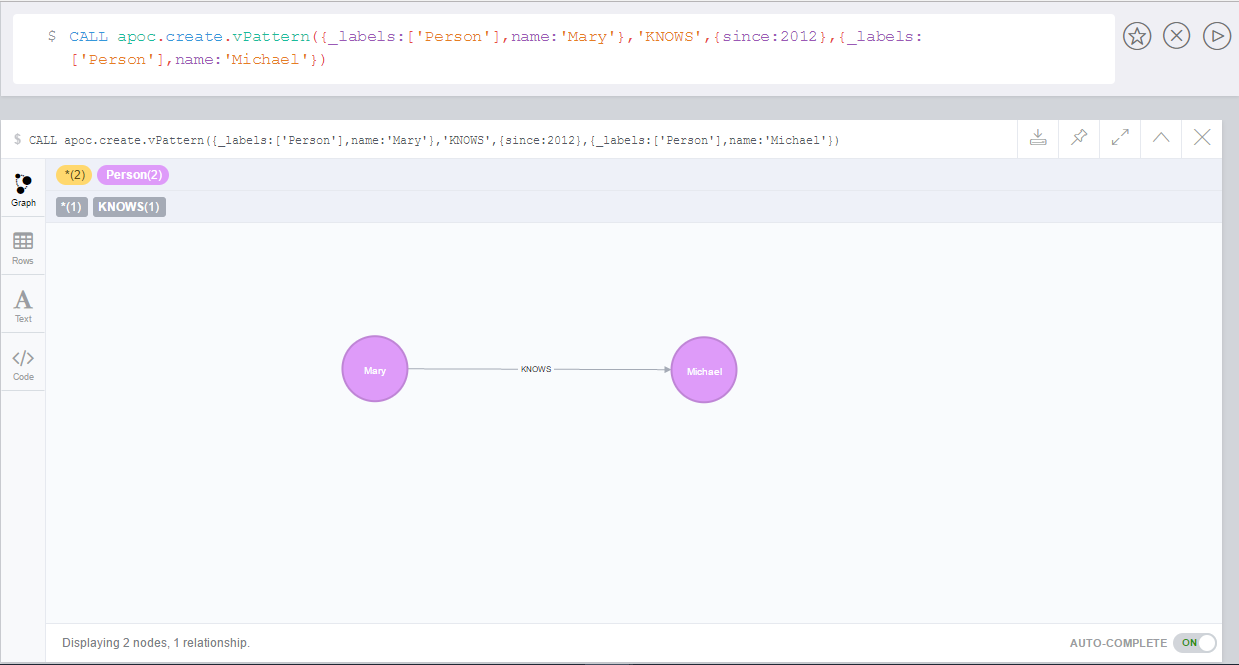
We can add more labels, just adding them on _labels
CALL apoc.create.vPattern({_labels:['Person', 'Woman'],name:'Mary'},'KNOWS',{since:2012},{_labels:['Person', 'Man'],name:'Michael'})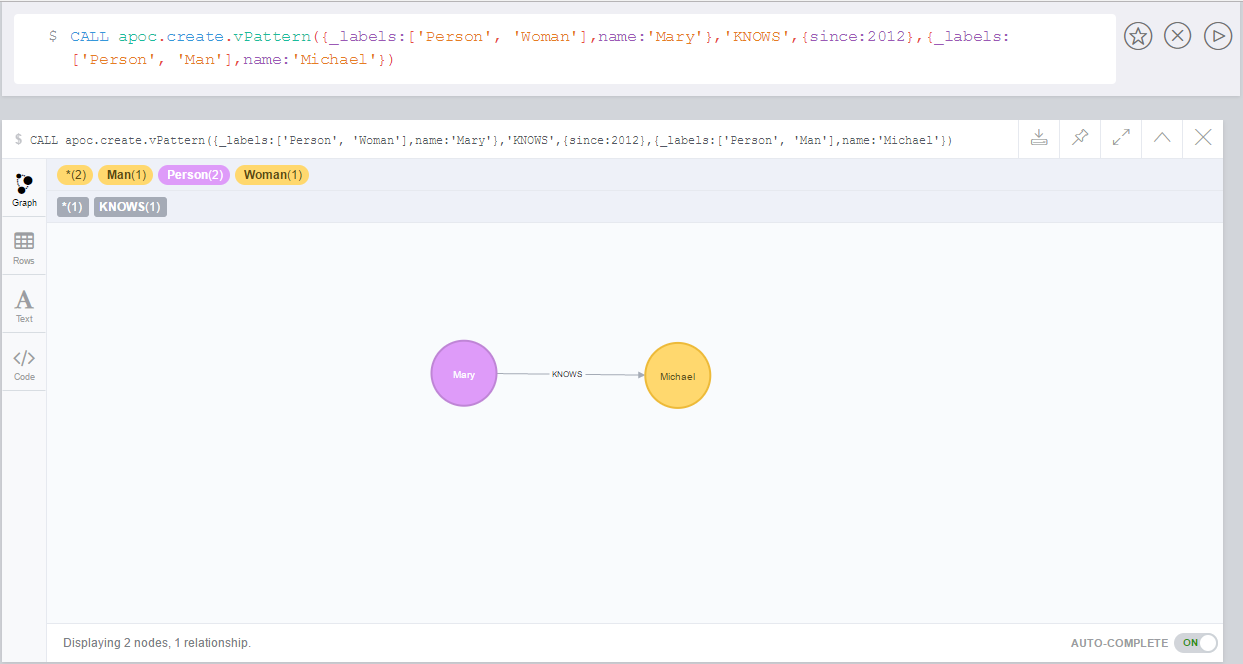
vPatternFullCALL apoc.create.vPatternFull(['British','Person'],{name:'James', age:28},'KNOWS',{since:2009},['Swedish','Person'],{name:'Daniel', age:30})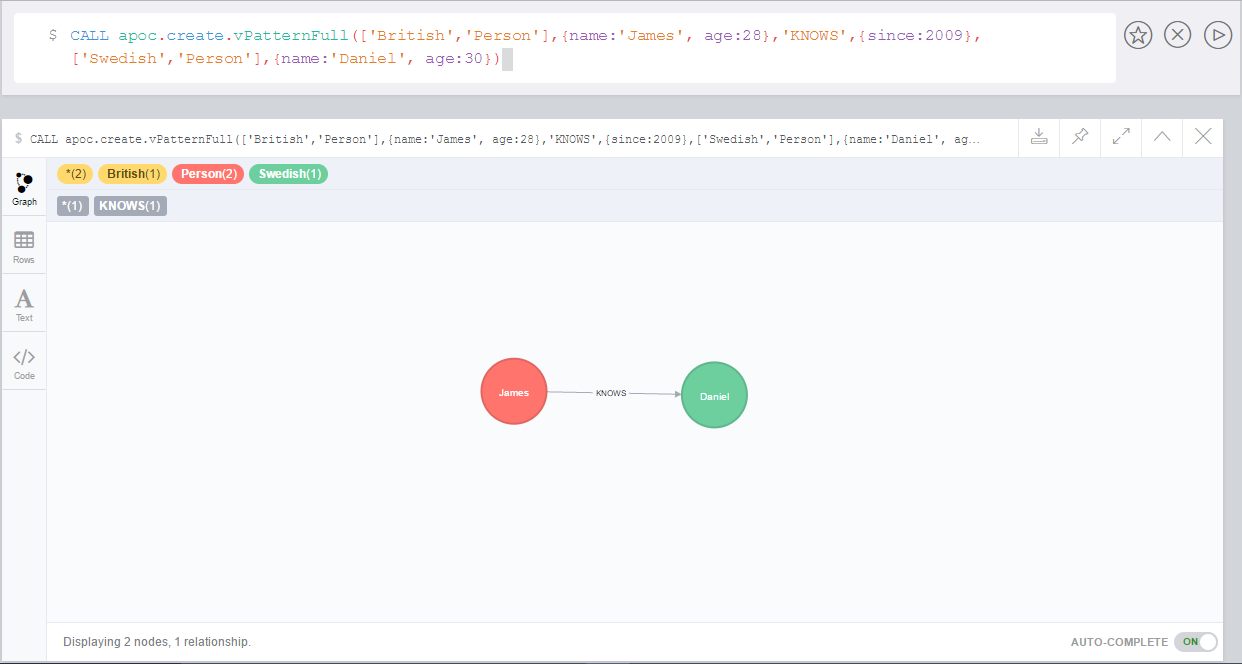
We can create a virtual pattern from an existing one
CREATE(a:Person {name:'Daniel'})-[r:KNOWS]->(b:Person {name:'John'})From this dataset we can create a virtual pattern
MATCH (a)-[r]->(b)
WITH head(labels(a)) AS labelA, head(labels(b)) AS labelB, type(r) AS rel_type, a.name AS aName, b.name AS bName
CALL apoc.create.vPatternFull([labelA],{name: aName},rel_type,{since:2009},[labelB],{name: bName}) yield from, rel, to
RETURN *;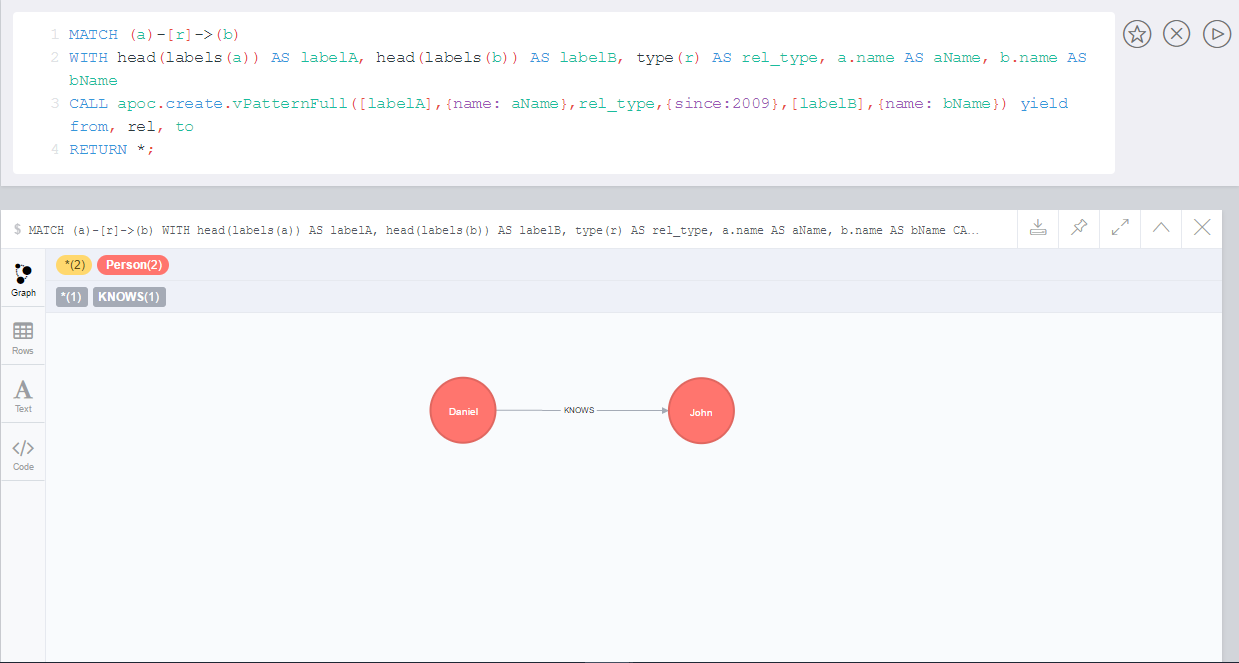
Virtual Graph
Create a graph object (map) from information that’s passed in.
It’s basic structure is: {name:"Name",properties:{properties},nodes:[nodes],relationships:[relationships]}
|
creates a virtual graph object for later processing it tries its best to extract the graph information from the data you pass in |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
Virtual Graph Examples
We create a dataset for our examples
CREATE (a:Actor {name:'Tom Hanks'})-[r:ACTED_IN {roles:'Forrest'}]->(m:Movie {title:'Forrest Gump'}) RETURN *MATCH (n)-[r]->(m) CALL apoc.graph.fromData([n,m],[r],'test',{answer:42}) YIELD graph RETURN *MATCH path = (n)-[r]->(m) CALL apoc.graph.fromPath(path,'test',{answer:42}) YIELD graph RETURN *MATCH path = (n)-[r]->(m) CALL apoc.graph.fromPaths([path],'test',{answer:42}) YIELD graph RETURN *CALL apoc.graph.fromDB('test',{answer:42}) YIELD graph RETURN *CALL apoc.graph.fromCypher('MATCH (n)-[r]->(m) RETURN *',null,'test',{answer:42}) YIELD graph RETURN *As a result we have a virtual graph object for later processing
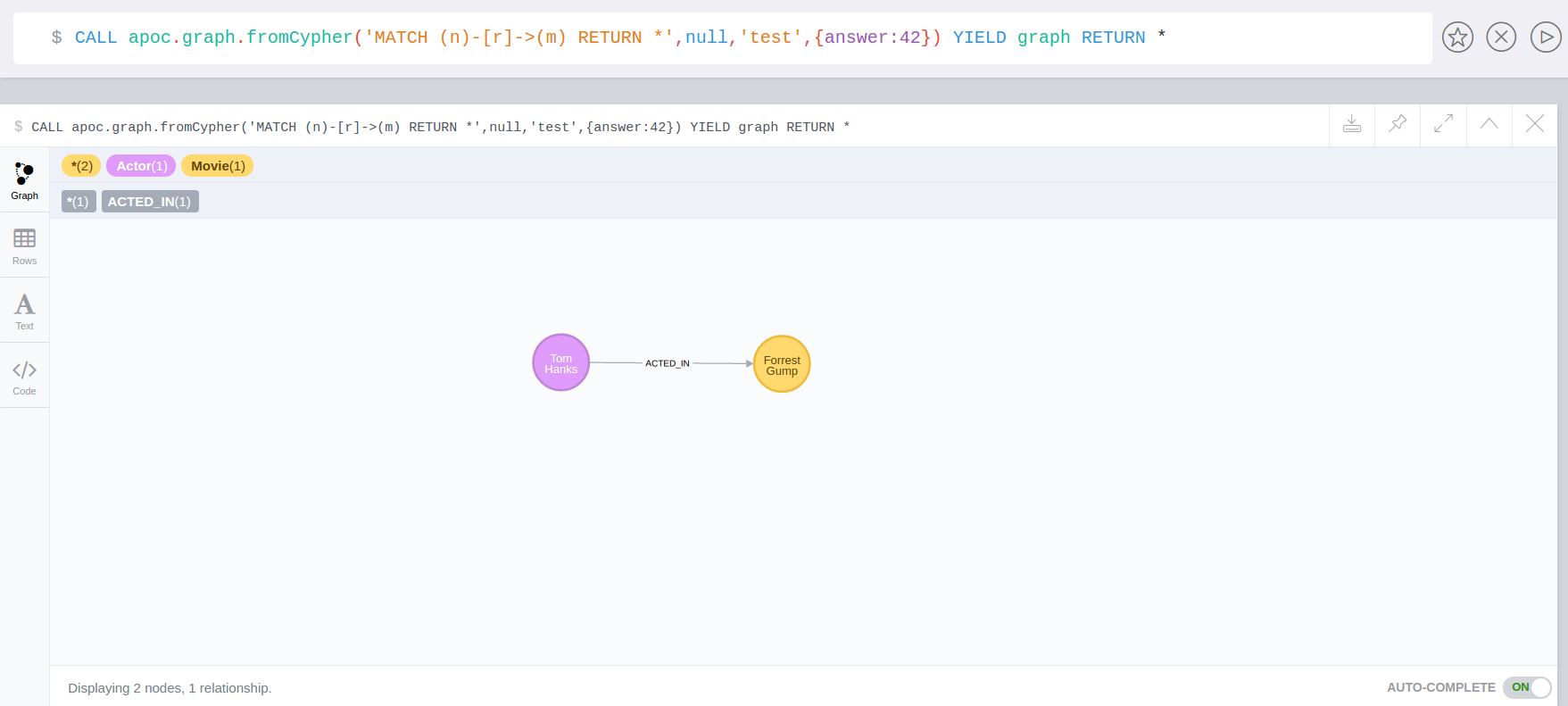
Graph Refactoring
|
clone nodes with their labels and properties |
|
clone nodes with their labels, properties and relationships |
|
merge nodes onto first in list |
|
redirect relationship to use new end-node |
|
redirect relationship to use new start-node |
|
inverts relationship direction |
|
change relationship-type |
|
extract node from relationships |
|
collapse node to relationship, node with one rel becomes self-relationship |
|
normalize/convert a property to be boolean |
|
turn each unique propertyKey into a category node and connect to it |
TODO:
-
merge nodes by label + property
-
merge relationships
Graph Refactoring Examples
We create a dataset
CREATE (f:Foo{name:'Foo'}),(b:Bar{name:'Bar'})As result we have two nodes
MATCH (f:Foo{name:'Foo'}),(b:Bar{name:'Bar'}) WITH f,b
CALL apoc.refactor.cloneNodes([f,b]) yield input, output RETURN *As result we have the two nodes that we have created before and their clones
We create a dataset of two different nodes of type Actor connected with other two different node of type Movie
CREATE (k:Actor {name:'Keanu Reeves'})-[:ACTED_IN {role:'Neo'}]->(m:Movie {title:'The Matrix'}),
(t:Actor {name:'Tom Hanks'})-[:ACTED_IN {role:'Forrest'}]->(f:Movie {title:'Forrest Gump'}) RETURN *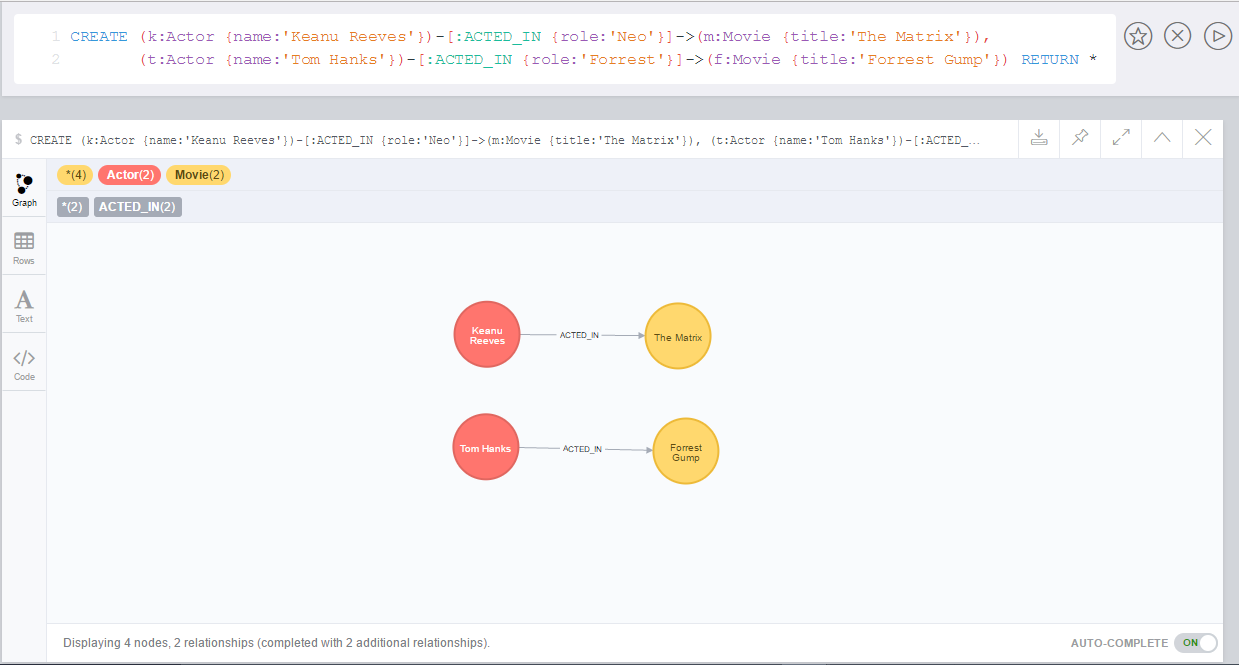
MATCH (k:Actor {name:'Keanu Reeves'}), (t:Actor {name:'Tom Hanks'})
CALL apoc.refactor.cloneNodesWithRelationships([k,t]) YIELD input, output RETURN *As result we have a copy of the nodes and relationships
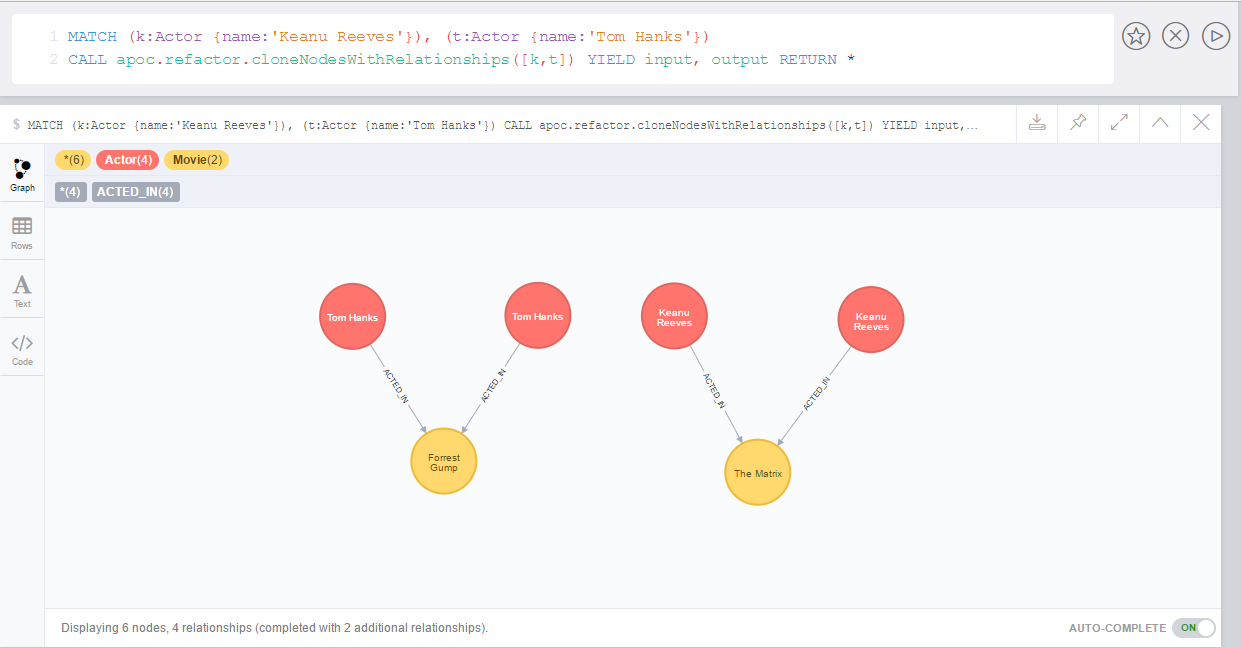
We create two nodes with different properties
CREATE (f:Person {name:'Foo'}), (b:Person {surname:'Bar'}) RETURN f,b
Now we want to merge these nodes into one
MATCH (f:Person {name:'Foo'}), (b:Person {surname:'Bar'})
CALL apoc.refactor.mergeNodes([f,b])
YIELD node RETURN node
Thus we have one node with both properties name and surname
We start with two nodes related each other with a relationship. We create a new node which we will use to redirect the relationship like end node
CREATE (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar)
CREATE (p:Person {name:'Antony'})
RETURN *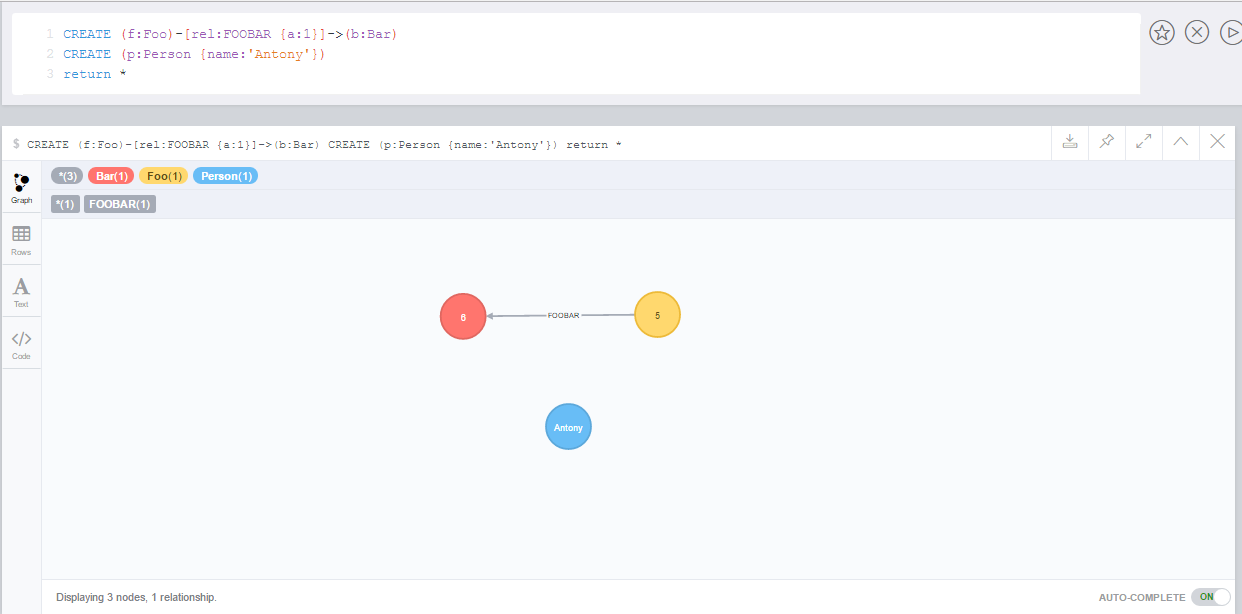
MATCH (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar) with id(rel) as id
MATCH (p:Person {name:'Antony'}) with p as p
MATCH ()-[r]->(), (p:Person) CALL apoc.refactor.to(r, p) YIELD input, output RETURN *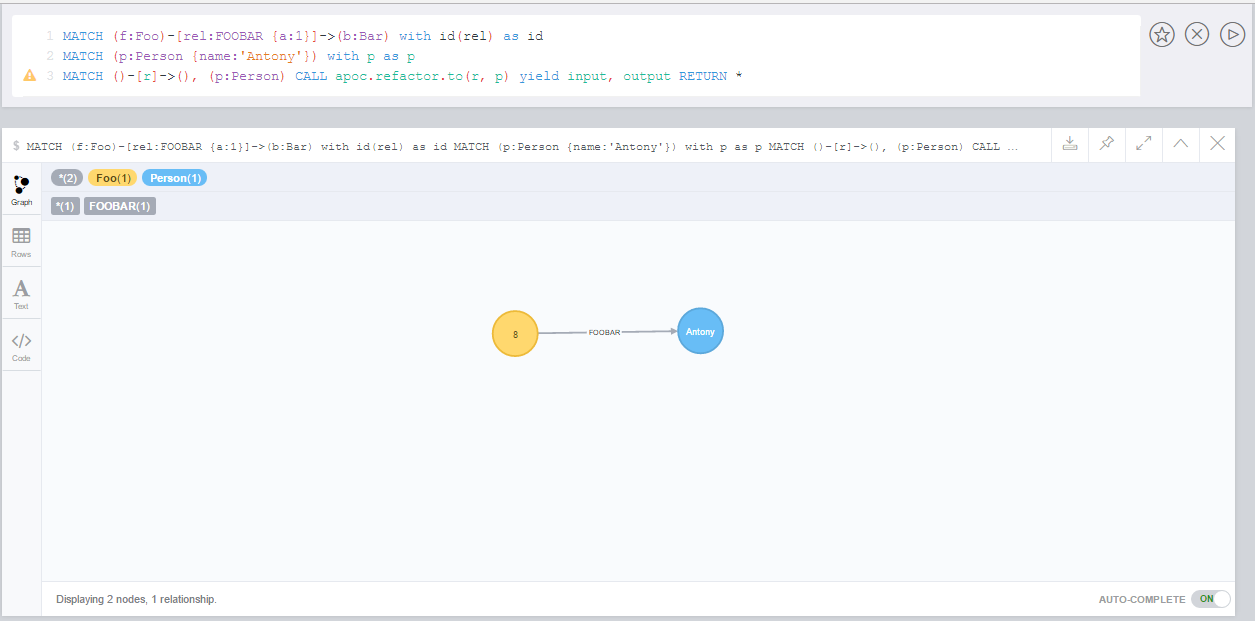
Now the relationship is towards the new node Person
We start with two nodes related each other with a relationship. We create a new node which we will use to redirect the relationship like start node
CREATE (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar)
CREATE (p:Person {name:'Antony'})
RETURN *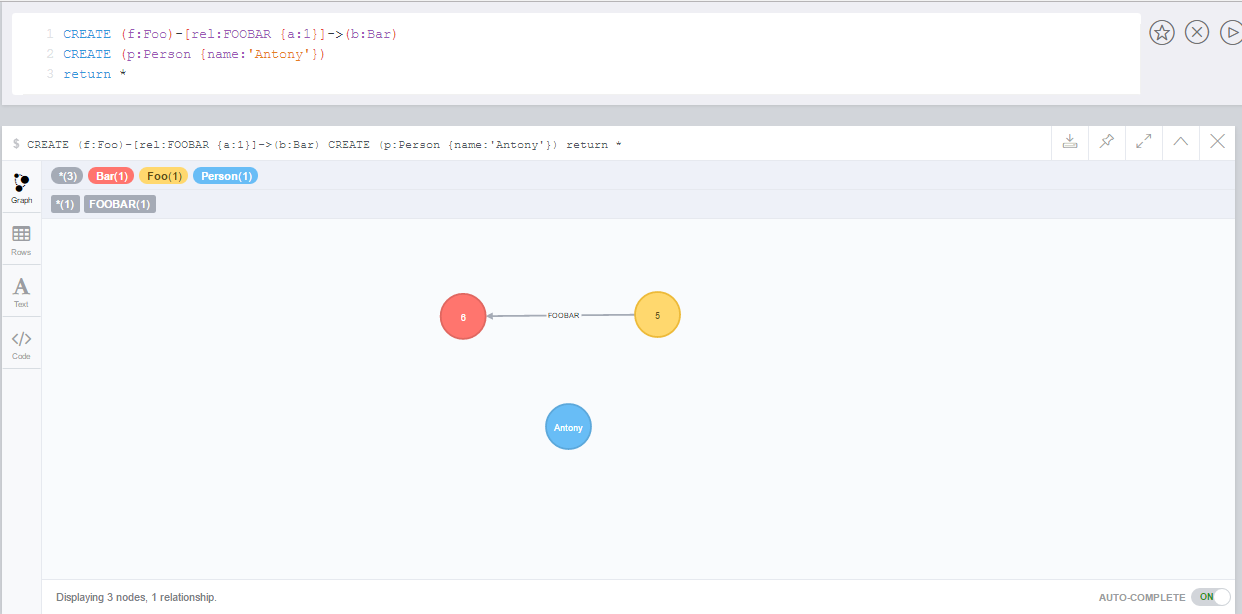
MATCH (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar) with id(rel) as id
MATCH (p:Person {name:'Antony'}) with p as p
MATCH ()-[r]->(), (p:Person) CALL apoc.refactor.from(r, p) YIELD input, output RETURN *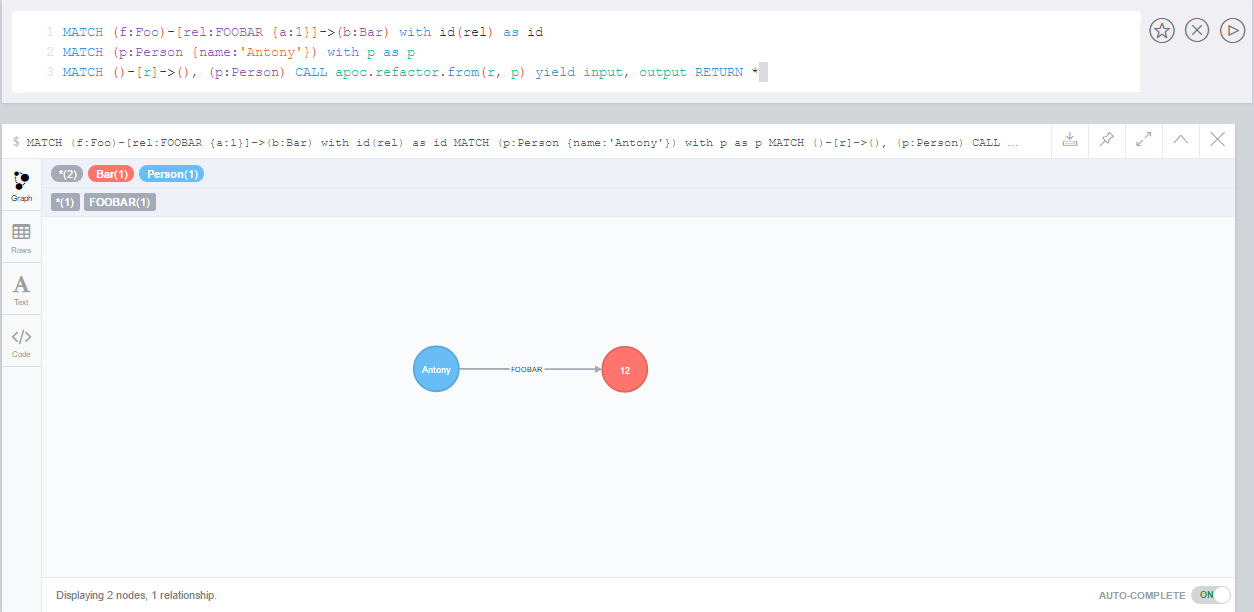
Now the relationship starts from the new node Person from the old node Bar
We start with two nodes connected by a relationship
CREATE (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar)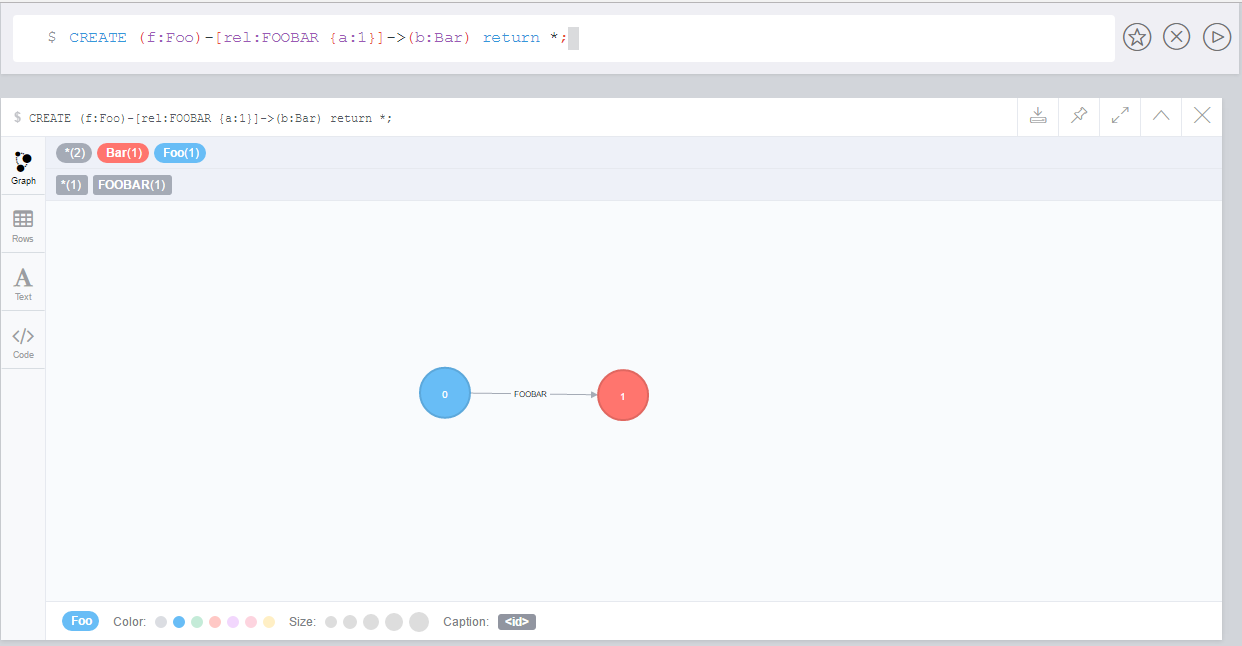
Now we want to invert the relationship direction
MATCH (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar) WITH id(rel) as id
MATCH ()-[r]->() WHERE id(r) = id
CALL apoc.refactor.invert(r) yield input, output RETURN *
With a simple relationship between two node
CREATE (f:Foo)-[rel:FOOBAR]->(b:Bar)
We can change the relationship type from FOOBAR to NEW-TYPE
MATCH (f:Foo)-[rel:FOOBAR]->(b:Bar) with rel
CALL apoc.refactor.setType(rel, 'NEW-TYPE') YIELD input, output RETURN *
CREATE (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar)
We pass the ID of the relationship as parameter to extract a node
MATCH (f:Foo)-[rel:FOOBAR {a:1}]->(b:Bar) WITH id(rel) as id
CALL apoc.refactor.extractNode(id,['FooBar'],'FOO','BAR')
YIELD input, output RETURN *
CREATE (f:Foo)-[:FOO {a:1}]->(b:Bar {c:3})-[:BAR {b:2}]->(f) WITH id(b) as id
CALL apoc.refactor.collapseNode(id,'FOOBAR')
YIELD input, output RETURN *Before we have this situation
And the result are
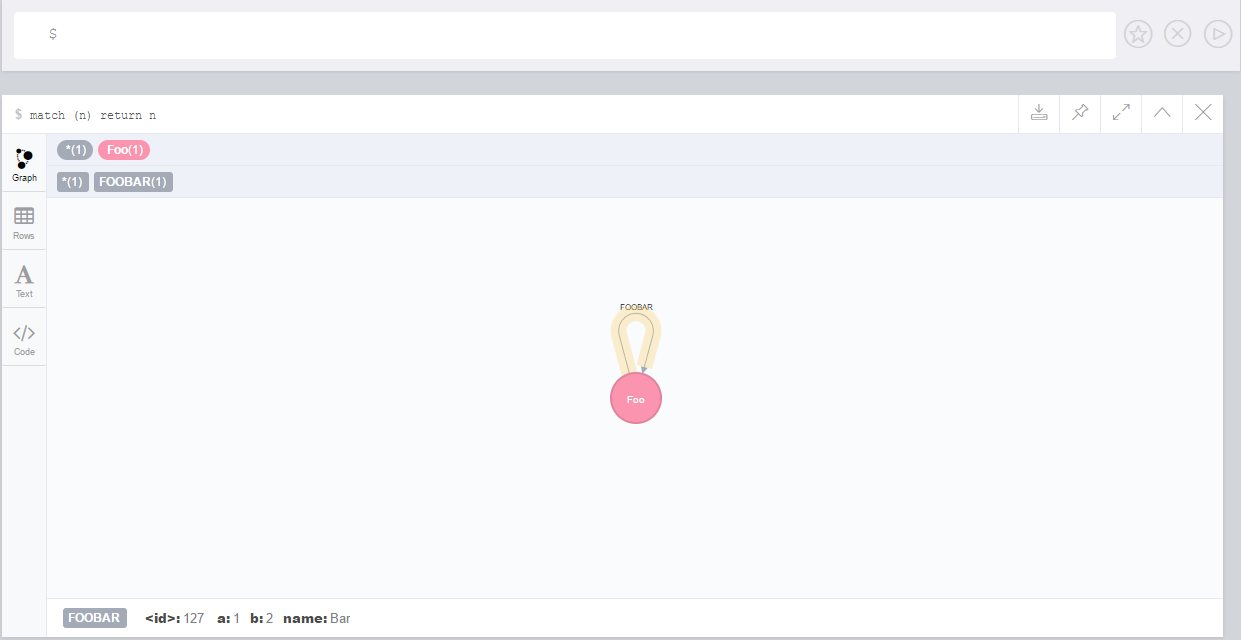
The property of the two relationship and the property of the node are joined in one relationship that has the properties a:1, b:2, name:Bar
CREATE (:Person {prop: 'Y', name:'A'}),(:Person {prop: 'Yes', name:'B'}),(:Person {prop: 'NO', name:'C'}),(:Person {prop: 'X', name:'D'})As a resul we have four nodes with different properties prop like Y, Yes, NO, X
Now we want to transform some properties into a boolean, Y, Yes into true and the properties NO into false.
The other properties that don’t match these possibilities will be set as null.
MATCH (n) CALL apoc.refactor.normalizeAsBoolean(n,'prop',['Y','Yes'],['NO']) WITH n ORDER BY n.id RETURN n.prop AS prop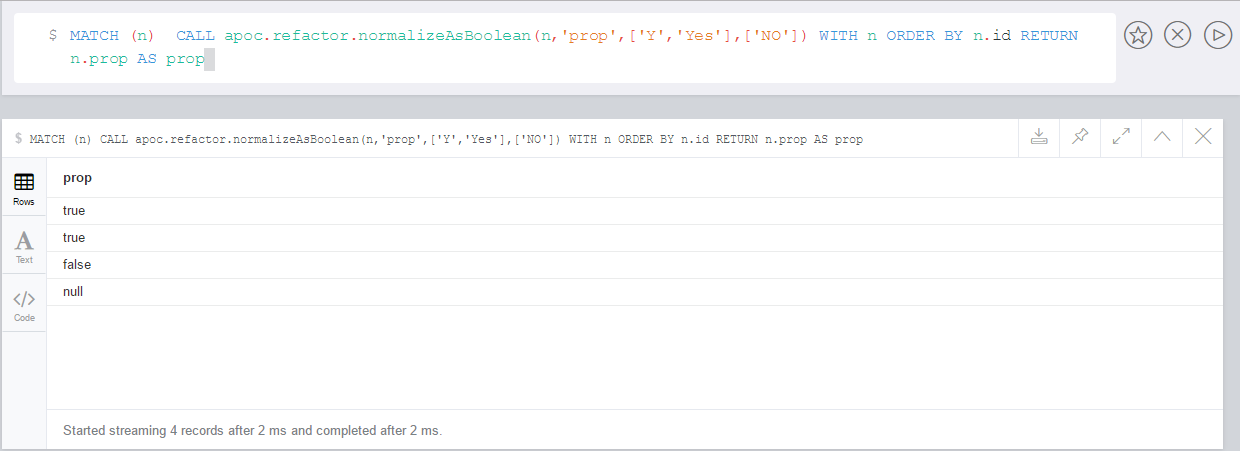
First of all we create some nodes as dataset
CREATE (:Person {prop: 'A', k: 'a', id: 1}),
(:Person {prop: 'A', k: 'a', id: 2}),
(:Person {prop: 'C', k: 'c', id: 3}),
(:Person { id: 4}),
(:Person {prop: 'B', k: 'b', id: 5}),
(:Person {prop: 'C', k: 'c', id: 6})As result we have six nodes with label 'Person' with different properties

Now we want to transform the property prop into a separate node with label Letter and transfer the properties of the nodes Person: prop (now renamed in name) and k.
The nodes Person will keep only the propertie id, and will be connected with a relationship IS_A with the new nodes Letter.
CALL apoc.refactor.categorize('prop','IS_A',true,'Letter','name',['k'],1)
The direction of the relationship (in this case outgoing) is defined by the third field, if true outgoing else incoming.
If a node doesn’t has the property prop (like node with id: 4) it won’t be managed.
Rename
Procedures set for renaming labels, relationship types, nodes and relationships' properties. They return the list of eventually impacted constraints and indexes, the user should take care of.
|
rename a label from 'oldLabel' to 'newLabel' for all nodes. If 'nodes' is provided renaming is applied to this set only |
|
rename all relationships with type 'oldType' to 'newType'. If 'rels' is provided renaming is applied to this set only |
|
rename all node’s property from 'oldName' to 'newName'. If 'nodes' is provided renaming is applied to this set only |
|
rename all relationship’s property from 'oldName' to 'newName'. If 'rels' is provided renaming is applied to this set only |
Triggers
Enable apoc.trigger.enabled=true in $NEO4J_HOME/config/neo4j.conf first.
|
add a trigger statement under a name, in the statement you can use {createdNodes}, {deletedNodes} etc., the selector is {phase:'before/after/rollback'} returns previous and new trigger information |
|
remove previously added trigger, returns trigger information |
|
update and list all installed triggers |
|
it pauses the trigger |
|
it resumes the paused trigger |
Helper Functions
|
function to filter labelEntries by label, to be used within a trigger statement with {assignedLabels} and {removedLabels} {phase:'before/after/rollback'} returns previous and new trigger information |
|
function to filter propertyEntries by property-key, to be used within a trigger statement with {assignedNode/RelationshipProperties} and {removedNode/RelationshipProperties}. Returns [{old,new,key,node,relationship}] |
The statements available are:
| Statement | Description |
|---|---|
transactionId |
returns the id of the transaction |
commitTime |
return the date of the transaction in milliseconds |
createdNodes |
when a node is created our trigger fires |
createdRelationships |
when a relationship is created our trigger fires |
deletedNodes |
when a node is delated our trigger fires |
deletedRelationships |
when a relationship is delated our trigger fires |
removedLabels |
when a label is removed our trigger fires |
removedNodeProperties |
when a properties of node is removed our trigger fires |
removedRelationshipProperties |
when a properties of relationship is removed our trigger fires |
assignedLabels |
when a labes is assigned our trigger fires |
assignedNodeProperties |
when node property is assigned our trigger fires |
assignedRelationshipProperties |
when relationship property is assigned our trigger fires |
Triggers Examples
We could add a trigger that when is added a specific property on a node, that property is added to all the nodes connected to this node
Dataset
CREATE (d:Person {name:'Daniel'})
CREATE (l:Person {name:'Mary'})
CREATE (t:Person {name:'Tom'})
CREATE (j:Person {name:'John'})
CREATE (m:Person {name:'Michael'})
CREATE (a:Person {name:'Anne'})
CREATE (l)-[:DAUGHTER_OF]->(d)
CREATE (t)-[:SON_OF]->(d)
CREATE (t)-[:BROTHER]->(j)
CREATE (a)-[:WIFE_OF]->(d)
CREATE (d)-[:SON_OF]->(m)
CREATE (j)-[:SON_OF]->(d)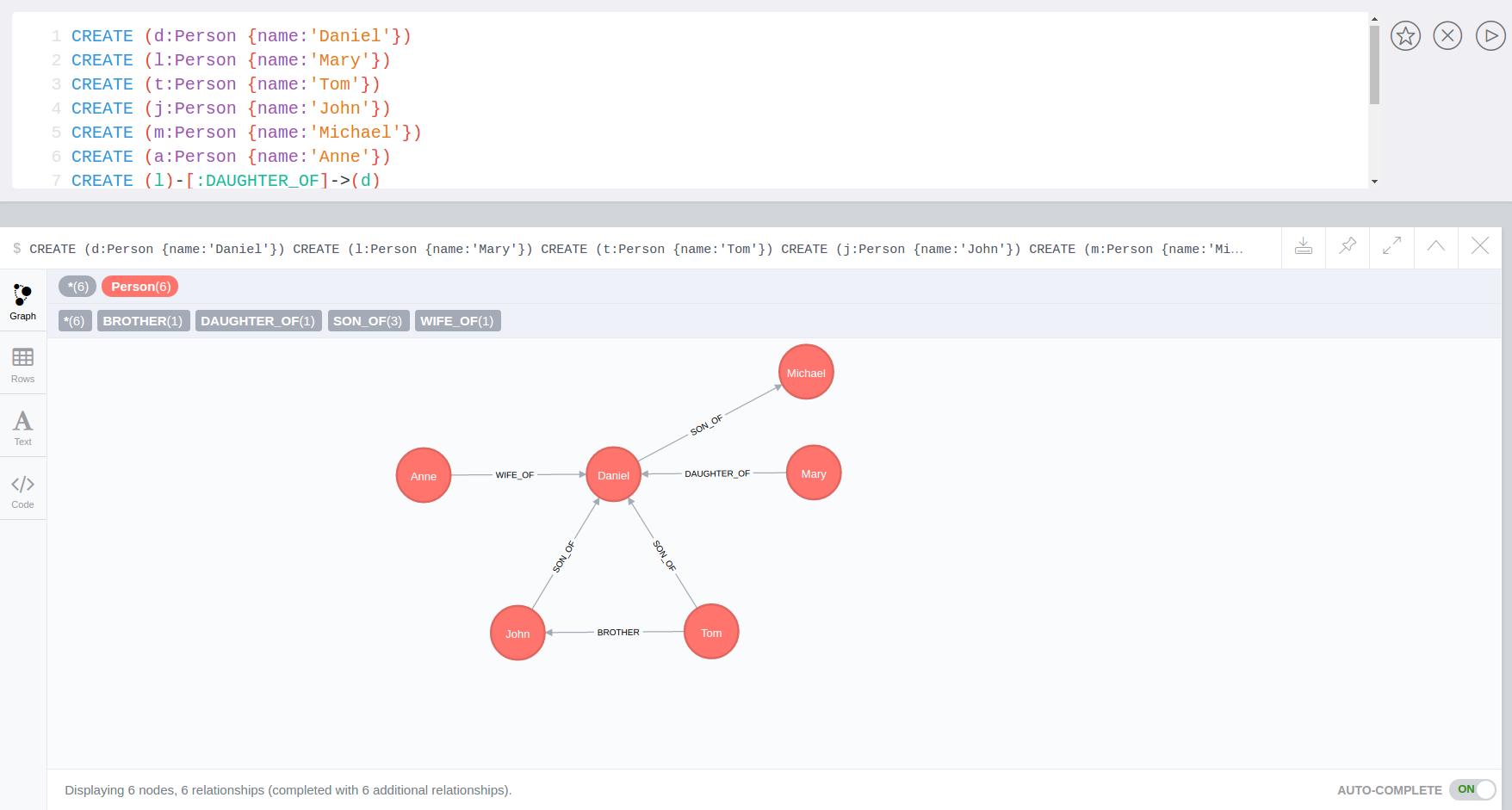
Now we add the trigger using apoc.trigger.propertiesByKey on the surname property
CALL apoc.trigger.add('setAllConnectedNodes','UNWIND apoc.trigger.propertiesByKey({assignedNodeProperties},"surname") as prop
WITH prop.node as n
MATCH(n)-[]-(a)
SET a.surname = n.surname', {phase:'after'});So when we add the surname property on a node, it’s added to all the nodes connected (in this case one level deep)
MATCH (d:Person {name:'Daniel'})
SET d.surname = 'William'
The surname property is add/change on all related nodes
Dataset
CREATE (k:Actor {name:'Keanu Reeves'})
CREATE (l:Actor {name:'Laurence Fishburne'})
CREATE (c:Actor {name:'Carrie-Anne Moss'})
CREATE (m:Movie {title:'Matrix'})
CREATE (k)-[:ACT_IN]->(m)
CREATE (l)-[:ACT_IN]->(m)
CREATE (c)-[:ACT_IN]->(m)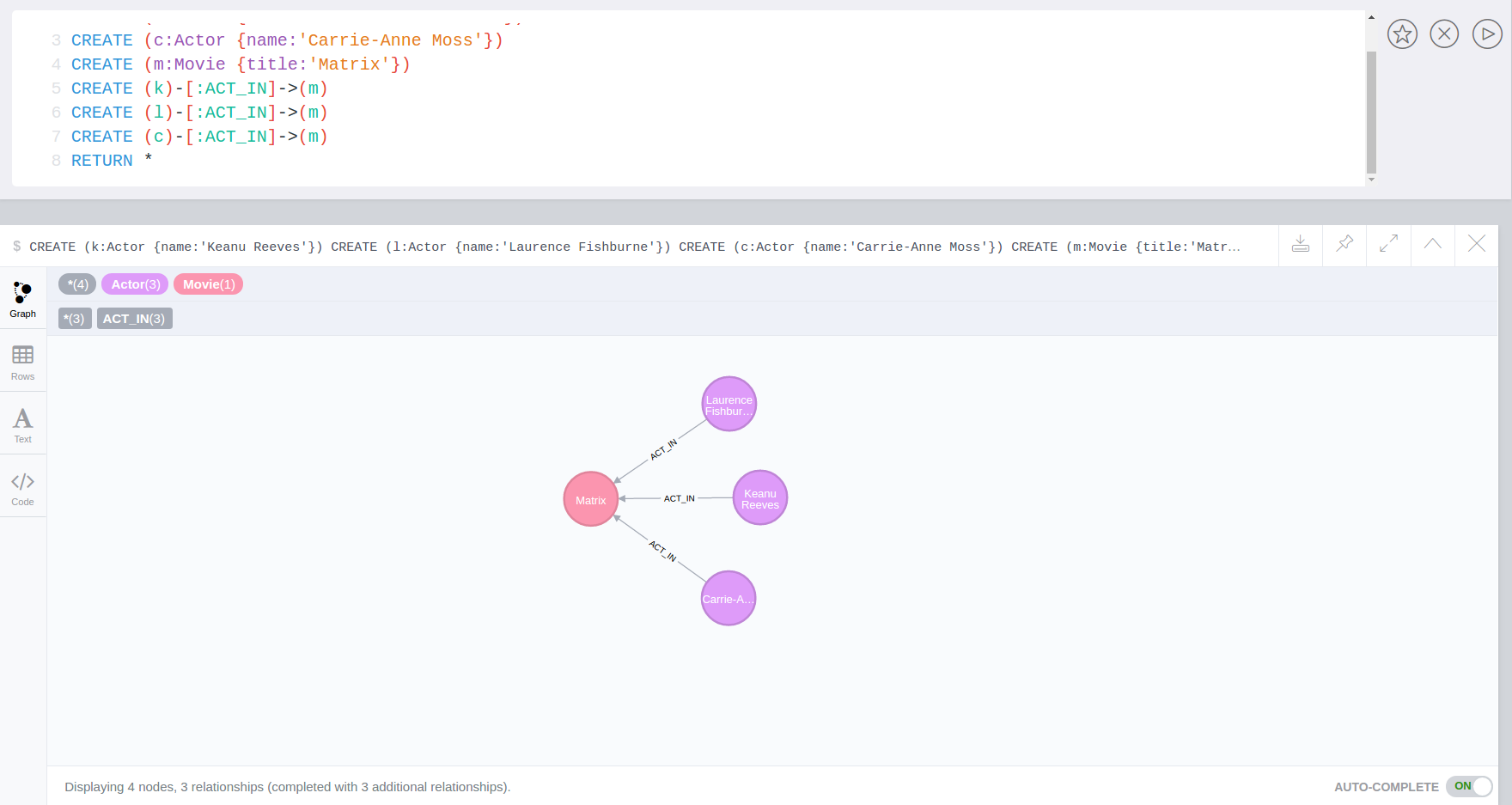
We add a trigger using apoc.trigger.nodesByLabel that when the label Actor of a node is removed, update all labels Actor with Person
CALL apoc.trigger.add('updateLabels',"UNWIND apoc.trigger.nodesByLabel({removedLabels},'Actor') AS node
MATCH (n:Actor)
REMOVE n:Actor SET n:Person SET node:Person", {phase:'before'})MATCH(k:Actor {name:'Keanu Reeves'})
REMOVE k:Actor
We can add a trigger that connect every new node with label Actor and as name property a specific value
CALL apoc.trigger.add('create-rel-new-node',"UNWIND {createdNodes} AS n
MATCH (m:Movie {title:'Matrix'})
WHERE n:Actor AND n.name IN ['Keanu Reeves','Laurence Fishburne','Carrie-Anne Moss']
CREATE (n)-[:ACT_IN]->(m)", {phase:'before'})CREATE (k:Actor {name:'Keanu Reeves'})
CREATE (l:Actor {name:'Laurence Fishburne'})
CREATE (c:Actor {name:'Carrie-Anne Moss'})
CREATE (a:Actor {name:'Tom Hanks'})
CREATE (m:Movie {title:'Matrix'})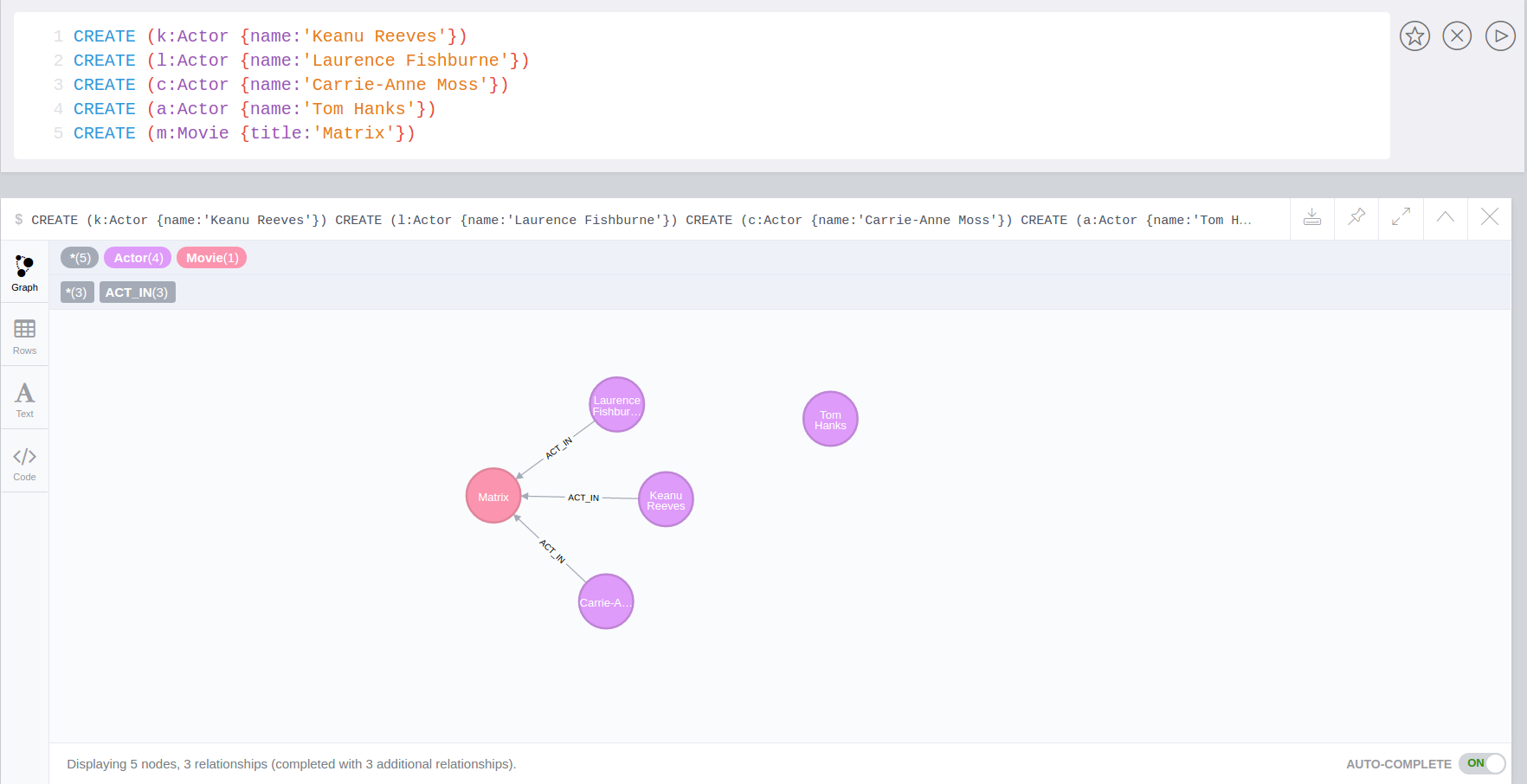
We have the possibility to pause a trigger without remove it, if we will need it in the future
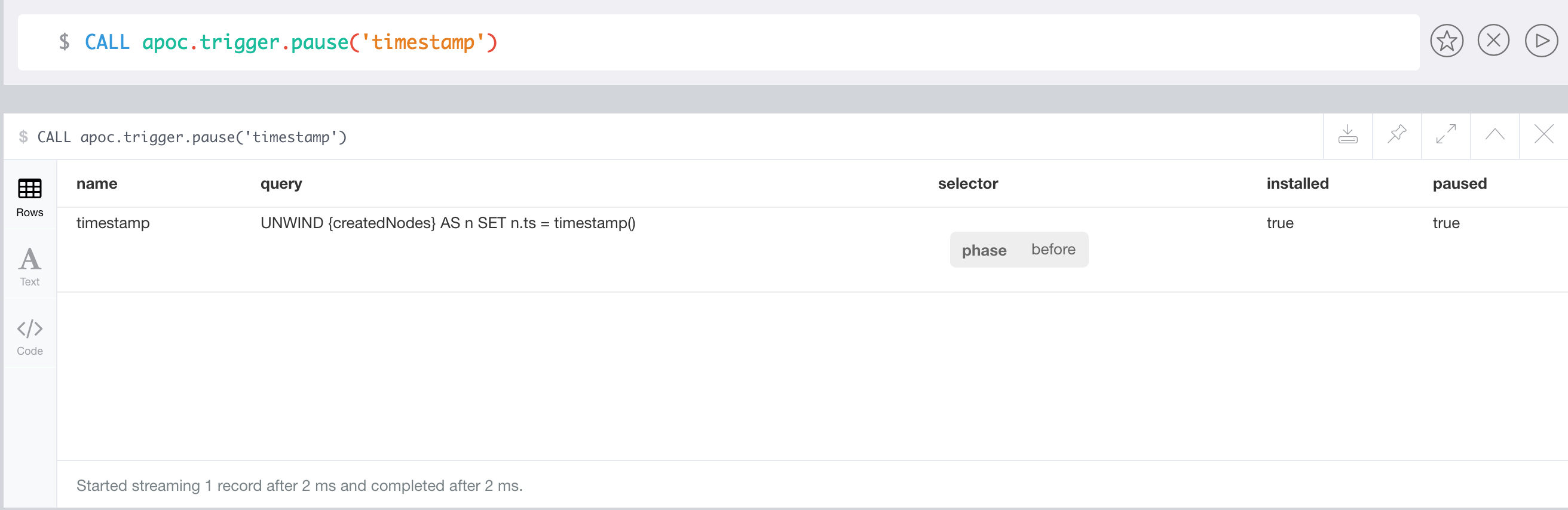
When you need again of a trigger paused
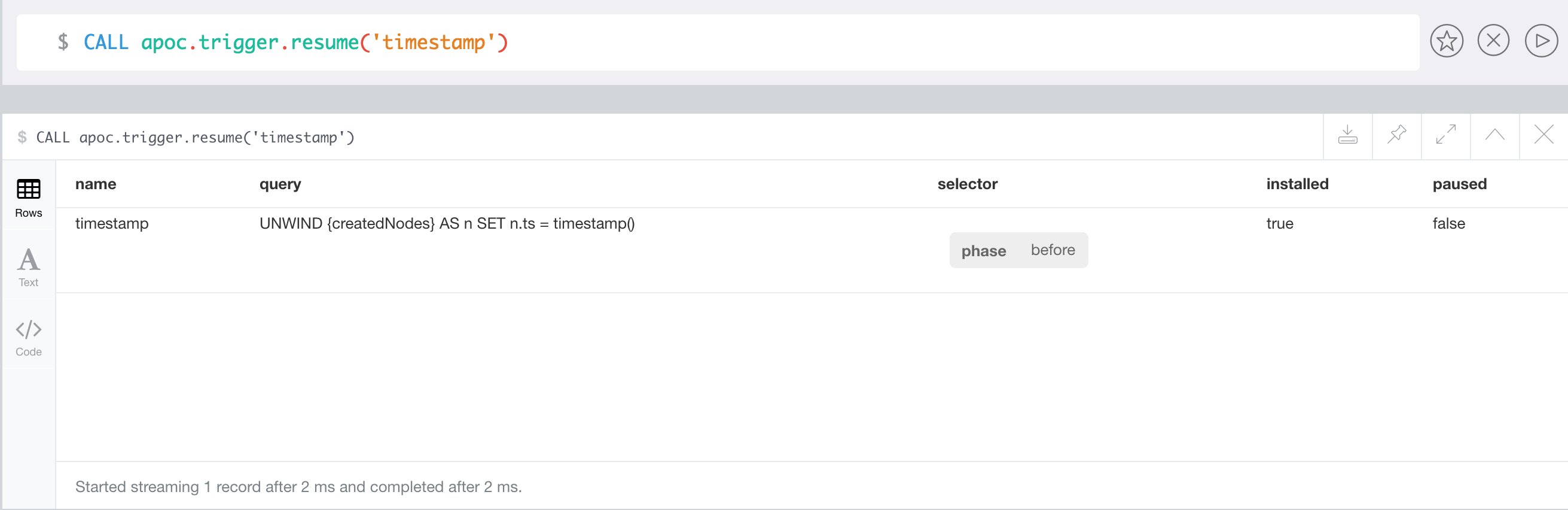
For this example, we would like that all the reference node properties are of type STRING
CALL apoc.trigger.add("forceStringType",
"UNWIND apoc.trigger.propertiesByKey({assignedNodeProperties}, 'reference') AS prop
CALL apoc.util.validate(apoc.meta.type(prop) <> 'STRING', 'expected string property type, got %s', [apoc.meta.type(prop)]) RETURN null", {phase:'before'})CREATE (a:Node) SET a.reference = 1
Neo.ClientError.Transaction.TransactionHookFailedCALL apoc.trigger.add('timestamp','UNWIND {createdNodes} AS n SET n.ts = timestamp()');
CALL apoc.trigger.add('lowercase','UNWIND {createdNodes} AS n SET n.id = toLower(n.name)');
CALL apoc.trigger.add('txInfo', 'UNWIND {createdNodes} AS n SET n.txId = {transactionId}, n.txTime = {commitTime}', {phase:'after'});
CALL apoc.trigger.add('count-removed-rels','MATCH (c:Counter) SET c.count = c.count + size([r IN {deletedRelationships} WHERE type(r) = "X"])')
CALL apoc.trigger.add('lowercase-by-label','UNWIND apoc.trigger.nodesByLabel({assignedLabels},'Person') AS n SET n.id = toLower(n.name)')Schema
To retrieve indexes and constraints information for all the node labels in your database, you can use the following procedure:
CALL apoc.schema.nodes() yield name, label, properties, status, typeWhere the outputs are:
-
name of the index/constraint,
-
label
-
properties, (for Neo4j 3.1 and lower versions is a single element array) that are affected by the constraint
-
status, for index can be one of the following values: ONLINE, POPULATING and FAILED
-
type, always "INDEX" for indexes, constraint type for constraints
To retrieve the constraint information for all the relationship types in your database, you can use the following procedure:
CALL apoc.schema.relationships() yield name, type, properties, statusWhere the outputs are:
-
name of the constraint
-
type of the relationship
-
properties, (for Neo4j 3.1 and lower versions is a single element array) that are affected by the constraint
-
status
N.B. Constraints for property existence on nodes and relationships are available only for the Enterprise Edition.
Examples
Given the following cypher statements:
CREATE CONSTRAINT ON (bar:Bar) ASSERT exists(bar.foobar)
CREATE CONSTRAINT ON (bar:Bar) ASSERT bar.foo IS UNIQUE
CREATE INDEX ON :Person(name)
CREATE INDEX ON :Publication(name)
CREATE INDEX ON :Source(name)When you
CALL apoc.schema.nodes()you will receive this result:

Given the following cypher statements:
CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day)
CREATE CONSTRAINT ON ()-[starred:STARRED]-() ASSERT exists(starred.month)When you
CALL apoc.schema.relationships()you will receive this result:

Check if an index or a constraint exists for a Label and property
Given the previous index definitions, running this statement:
RETURN apoc.schema.node.indexExists("Publication", ["name"])produces the following output:

Given the previous constraint definitions, running this statement:
RETURN apoc.schema.node.constraintExists("Bar", ["foobar"])produces the following output:

If you want to check if a constraint exists for a relationship you can run this statement:
RETURN apoc.schema.relationship.constraintExists('LIKED', ['day'])and you get the following result:

Atomic
Atomic procedures handle the concurrency, it’s add a lock to the resource.
If two users access to the same resource at the same time, with the parameter times (default value 5) we can determine how many time retry to modify the resource, until the lock is release.
|
adds the number to the value of the property |
|
subtracts the number to the value of the property |
|
concatenate the string to the property |
|
inserts the object in the chosen position of the array |
|
remove from the array the element to the position selected |
|
update the property with the result of the expression |
Atomic Examples
Dataset
CREATE (p:Person {name:'Tom',age: 40})We can add 10 to the property age
MATCH (n:Person {name:'Tom'})
CALL apoc.atomic.add(n,'age',10,5) YIELD oldValue, newValue
RETURN n
From the previous example we can go back to age: 40
MATCH (n:Person {name:'Tom'})
CALL apoc.atomic.subtract(n,'age',10,5) YIELD oldValue, newValue
RETURN nDataset
CREATE (p:Person {name:'Will',age: 35})MATCH (p:Person {name:'Will',age: 35})
CALL apoc.atomic.concat(p,"name",'iam',5) YIELD newValue
RETURN p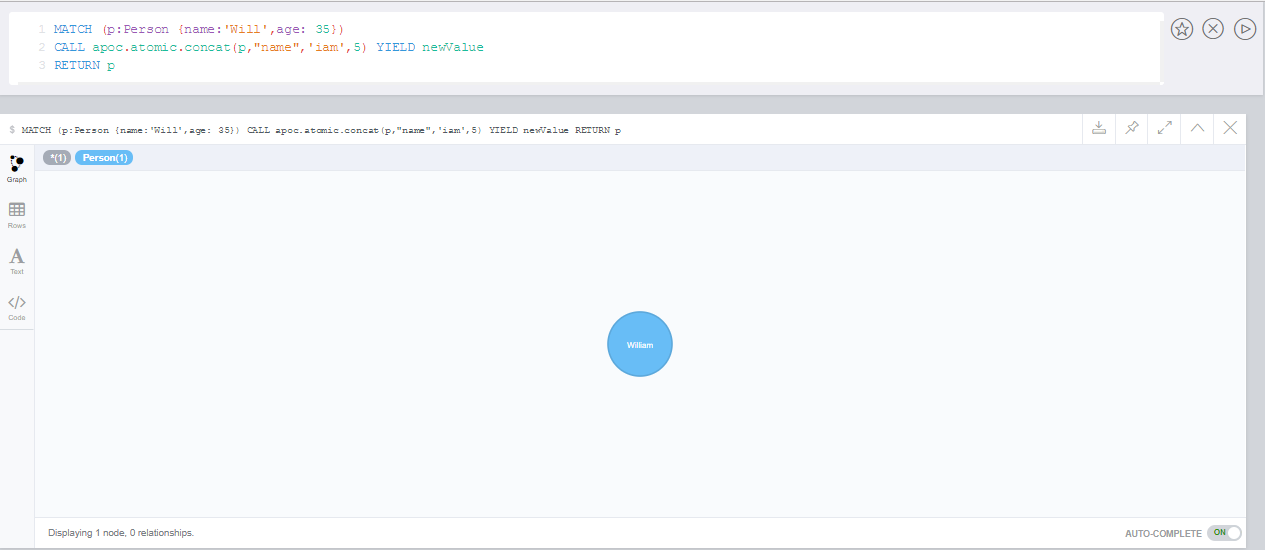
Dataset
we add a propery children that is an array
CREATE (p:Person {name:'Tom', children: ['Anne','Sam','Paul']})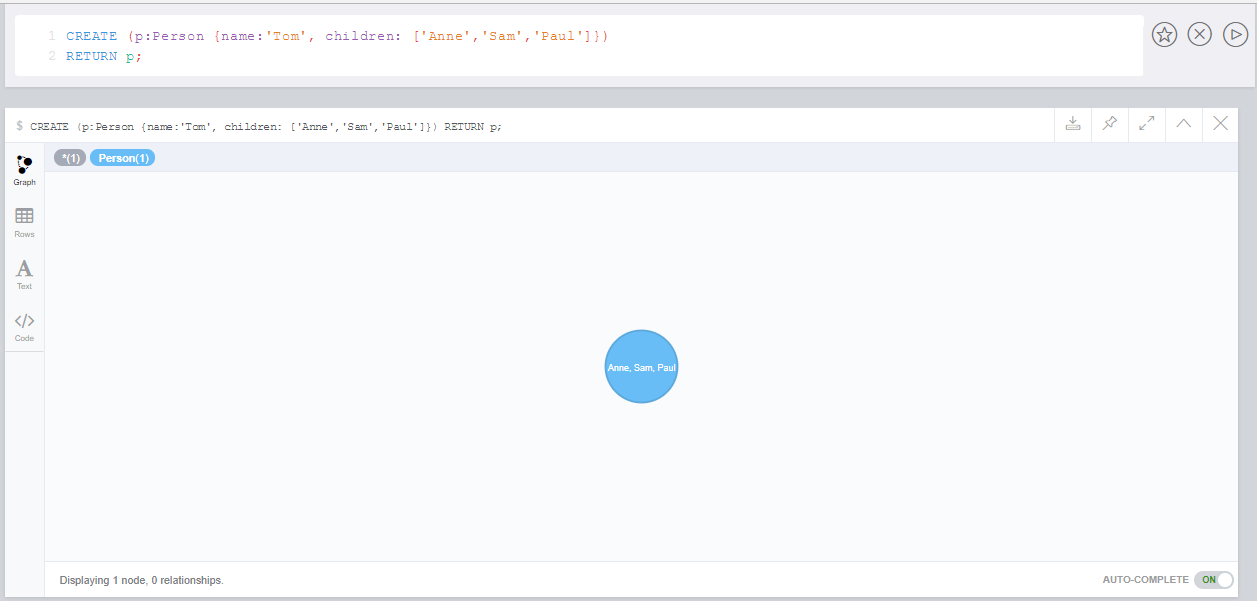
Now we add Mary to propery children at the position 2
MATCH (p:Person {name:'Tom'})
CALL apoc.atomic.insert(p,'children',2,'Mary',5) YIELD newValue
RETURN p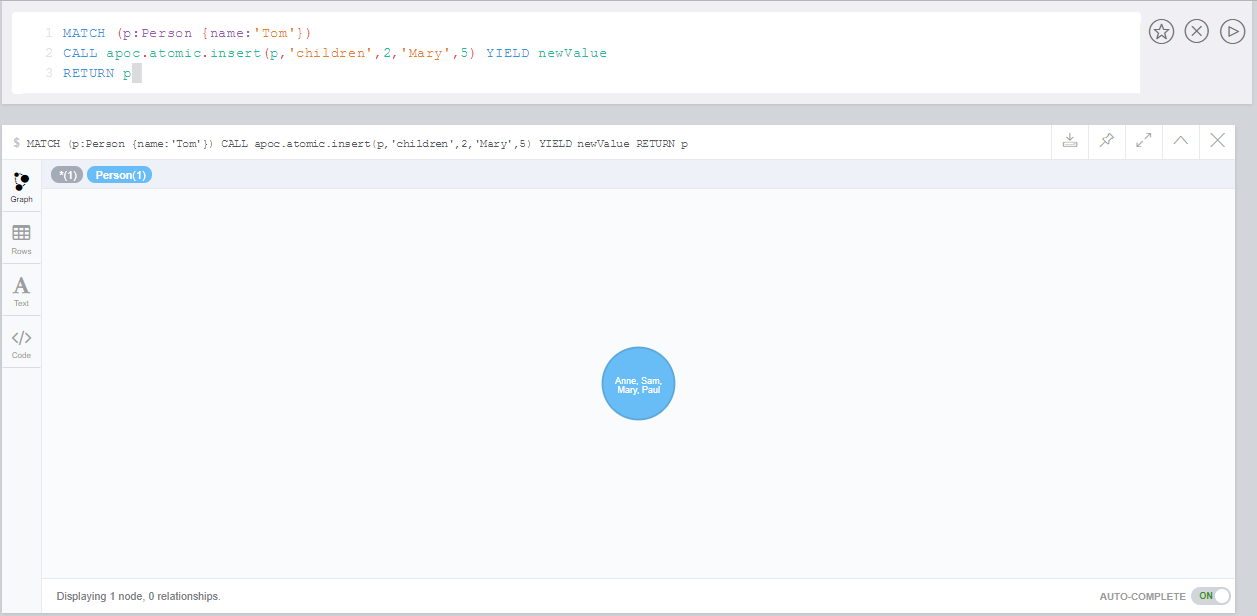
Dataset
CREATE (p:Person {name:'Tom', cars: ['Class A','X3','Focus']})Now we remove the element X3 which is at the position 1 from the array cars
MATCH (p:Person {name:'Tom'})
CALL apoc.atomic.remove(p,'cars',1,5) YIELD newValue
RETURN p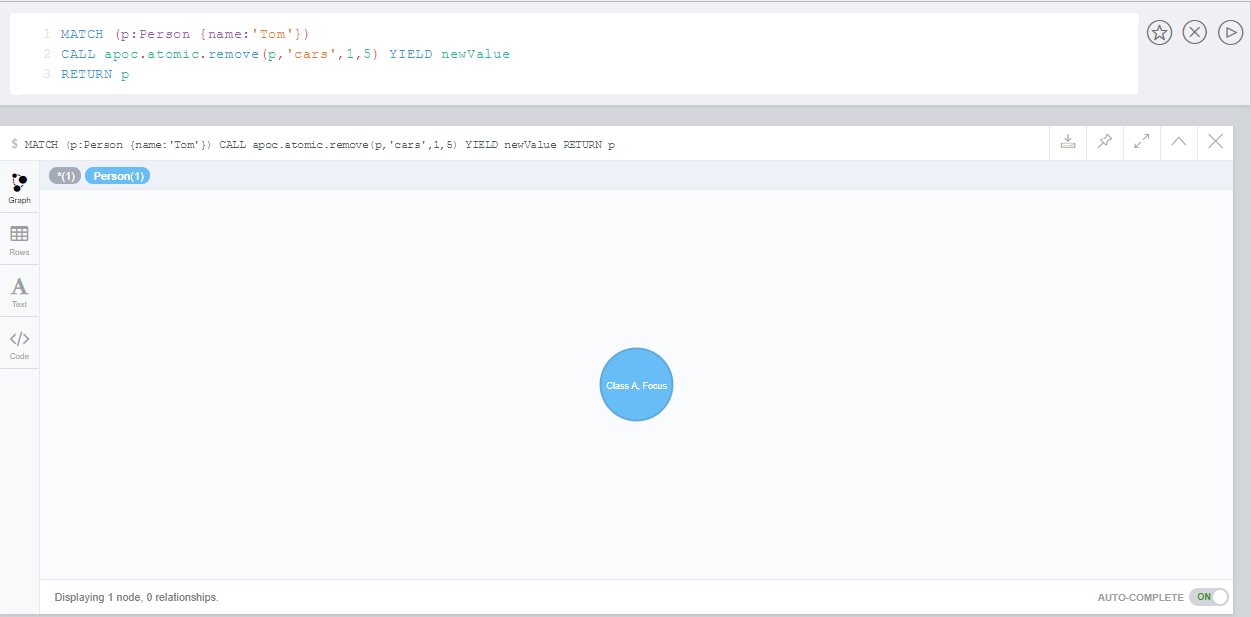
Dataset
CREATE (p:Person {name:'Tom', salary1:1800, salary2:1500})
We want to update salary1 with the result of an expression.
The expression always have to be referenced with the n. that refers to the node/rel passed as parameter.
If we rename our node/rel (as in the example above) we have anyway to refer to it in the expression as n.
MATCH (p:Person {name:'Tom'})
CALL apoc.atomic.update(p,'salary1','n.salary1*3 + n.salary2',5) YIELD newValue
RETURN p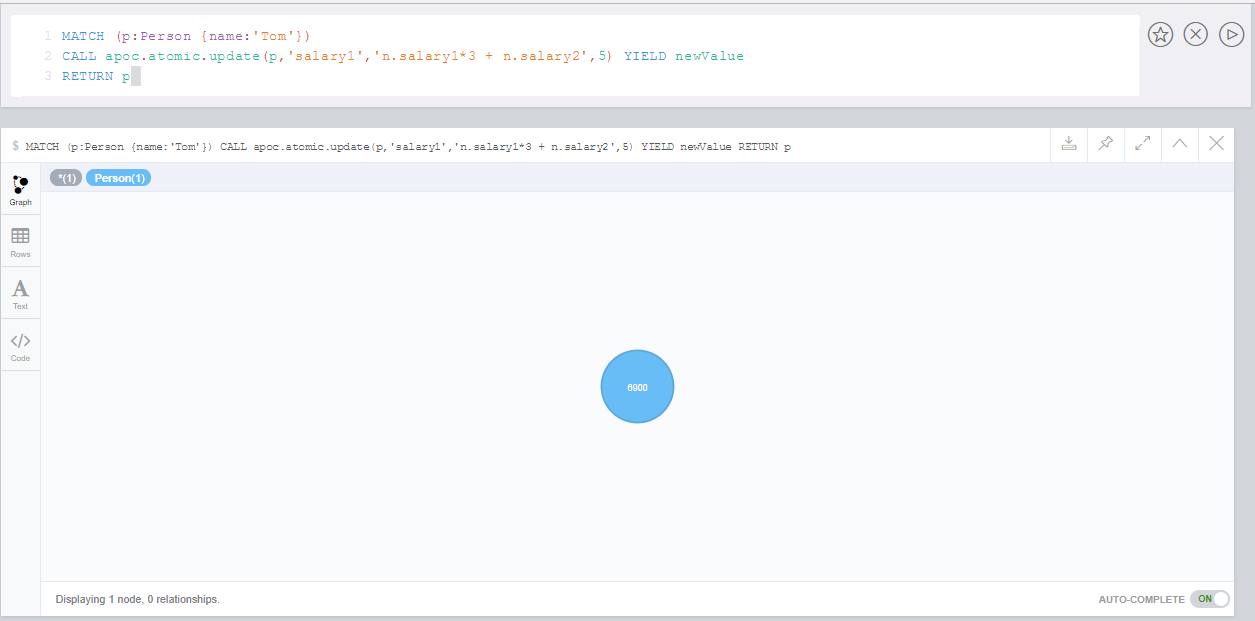
Bolt
Bolt procedures allows to accessing other databases via bolt protocol.
|
access to other databases via bolt for read and write |
|
access to other databases via bolt for read |
urlOrKey param allows users to decide if send url by apoc or if put it into neo4j.conf file.
-
apoc : write the complete url in his right position on the apoc.
call apoc.bolt.load("bolt://user:password@localhost:7687","match(p:Person {name:{name}}) return p", {name:'Michael'})-
neo4j.conf : here the are two choices:
1) complete url: write the complete url with the param apoc.bolt.url;
call apoc.bolt.load("","match(p:Person {name:{name}}) return p", {name:'Michael'})//simple url
apoc.bolt.url=bolt://user:password@localhost:76872) by key: set the url with a personal key apoc.bolt.yourKey.url; in this case in the apoc on the url param user has to insert the key.
call apoc.bolt.load("test","match(p:Person {name:{name}}) return p", {name:'Michael'})//with key
apoc.bolt.test.url=bolt://user:password@localhost:7687
apoc.bolt.production.url=bolt://password:test@localhost:7688Config available are:
-
statistics: possible values are true/false, the default value is false. This config print the execution statistics; -
virtual: possible values are true/false, the default value is false. This config return result in virtual format and not in map format, in apoc.bolt.load.
Driver configuration
To set the configuration of the Driver, you can add the parameter driverConfig in the config.
Is’s a map of values, the values that we don’t pass to the config, are set to the default value.
{logging='INFO', encryption=true, logLeakedSessions:true, maxIdleConnectionPoolSize:10, idleTimeBeforeConnectionTest:-1, trustStrategy:'TRUST_ALL_CERTIFICATES',
routingFailureLimit: 1, routingRetryDelayMillis:5000, connectionTimeoutMillis:5000, maxRetryTimeMs:30000 }| param | description | possible values/ types |
|---|---|---|
logging |
logging provider to use |
INFO, WARNING, OFF, SEVERE, CONFIG, FINE, FINER |
encryption |
Disable or enabled encryption |
true, false |
logLeakedSessions |
Disable or enable logging of leaked sessions |
true, false |
maxIdleConnectionPoolSize |
Max number of connections |
number |
idleTimeBeforeConnectionTest |
Pooled connections that have been idle in the pool for longer than this timeout |
Milliseconds |
trustStrategy |
Specify how to determine the authenticity of an encryption certificate provided by the Neo4j instance we are connecting to |
TRUST_ALL_CERTIFICATES, TRUST_SYSTEM_CA_SIGNED_CERTIFICATES, or directly a custom certificate |
routingFailureLimit |
the number of times to retry each server in the list of routing servers |
number |
routingRetryDelayMillis |
Specify how long to wait before retrying to connect to a routing server |
Milliseconds |
connectionTimeoutMillis |
Specify socket connection timeout |
Milliseconds |
maxRetryTimeMs |
Specify the maximum time transactions are allowed to retry |
Milliseconds |
You can find all the values in the documentation Config.ConfigBuilder
Bolt Examples
Return node in map format
call apoc.bolt.execute("bolt://user:password@localhost:7687",
"match(p:Person {name:{name}}) return p", {name:'Michael'})
Return node in virtual Node format
call apoc.bolt.load("bolt://user:password@localhost:7687",
"match(p:Person {name:{name}}) return p", {name:'Michael'}, {virtual:true})
Create node and return statistic
call apoc.bolt.execute("bolt://user:password@localhost:7687",
"create(n:Node {name:{name}})", {name:'Node1'}, {statistics:true})
Return more scalar values
call apoc.bolt.execute("bolt://user:password@localhost:7687",
"match (n:Person {name:{name}}) return n.age as age, n.name as name, n.surname as surname", {name:'Michael'})
Return relationship in a map format
call apoc.bolt.load("bolt://user:password@localhost:7687",
"MATCH (n:Person{name:{name}})-[r:KNOWS]->(p) return r as rel", {name:'Anne'})
Return virtual path
call apoc.bolt.load("bolt://user:password@localhost:7687",
"START n=node({idNode}) MATCH path= (n)-[r:REL_TYPE*..3]->(o) return path", {idNode:200}, {virtual:true})
Create a Node with params in input
call apoc.bolt.execute("bolt://user:password@localhost:7687",
"CREATE (n:Car{brand:{brand},model:{model},year:{year}}) return n", {brand:'Ferrari',model:'California',year:2016})
Appendix: Complete Overview
Configuration Options
Set these config options in $NEO4J_HOME/neo4j.conf
All boolean options default to false, i.e. they are disabled, unless mentioned otherwise.
|
Enable triggers |
|
Enable time to live background task |
|
Set frequency in seconds to run ttl background task (default 60) |
|
Enable reading properties: |
|
Enable reading local files from disk |
|
Enable writing local files to disk |
|
store jdbc-urls under a key to be used by apoc.load.jdbc |
|
store es-urls under a key to be used by elasticsearch procedures |
|
store mongodb-urls under a key to be used by mongodb procedures |
|
store couchbase-urls under a key to be used by couchbase procedures |
|
Many periodic procedures rely on a scheduled executor that has a pool of threads with a default fixed size. You can configure the pool size using this configuration property |
|
Number of threads in the default APOC thread pool used for background executions. |
Manual Indexes
Index Queries
Procedures to add to and query manual indexes
|
Note
|
Please note that there are (case-sensitive) automatic schema indexes, for equality, non-equality, existence, range queries, starts with, ends-with and contains! |
|
add all nodes to this full text index with the given fields, additionally populates a 'search' index field with all of them in one place |
|
add node to an index for each label it has |
|
add node to an index for the given label |
|
add node to an index for the given name |
|
add relationship to an index for its type |
|
add relationship to an index for the given name |
|
apoc.index.removeRelationshipByName('name',rel) remove relationship from an index for the given name |
|
search for the first 100 nodes in the given full text index matching the given lucene query returned by relevance |
|
lucene query on node index with the given label name |
|
lucene query on relationship index with the given type name |
|
lucene query on relationship index with the given type name bound by either or both sides (each node parameter can be null) |
|
lucene query on relationship index with the given type name for outgoing relationship of the given node, returns end-nodes |
|
lucene query on relationship index with the given type name for incoming relationship of the given node, returns start-nodes |
Index Management
|
lists all manual indexes |
|
removes manual indexes |
|
gets or creates manual node index |
|
gets or creates manual relationship index |
match (p:Person) call apoc.index.addNode(p,["name","age"]) RETURN count(*);
// 129s for 1M People
call apoc.index.nodes('Person','name:name100*') YIELD node, weight return * limit 2Schema Index Queries
Schema Index lookups that keep order and can apply limits
|
schema range scan which keeps index order and adds limit, values can be null, boundaries are inclusive |
|
schema string search which keeps index order and adds limit, operator is 'STARTS WITH' or 'CONTAINS' |
Meta Graph
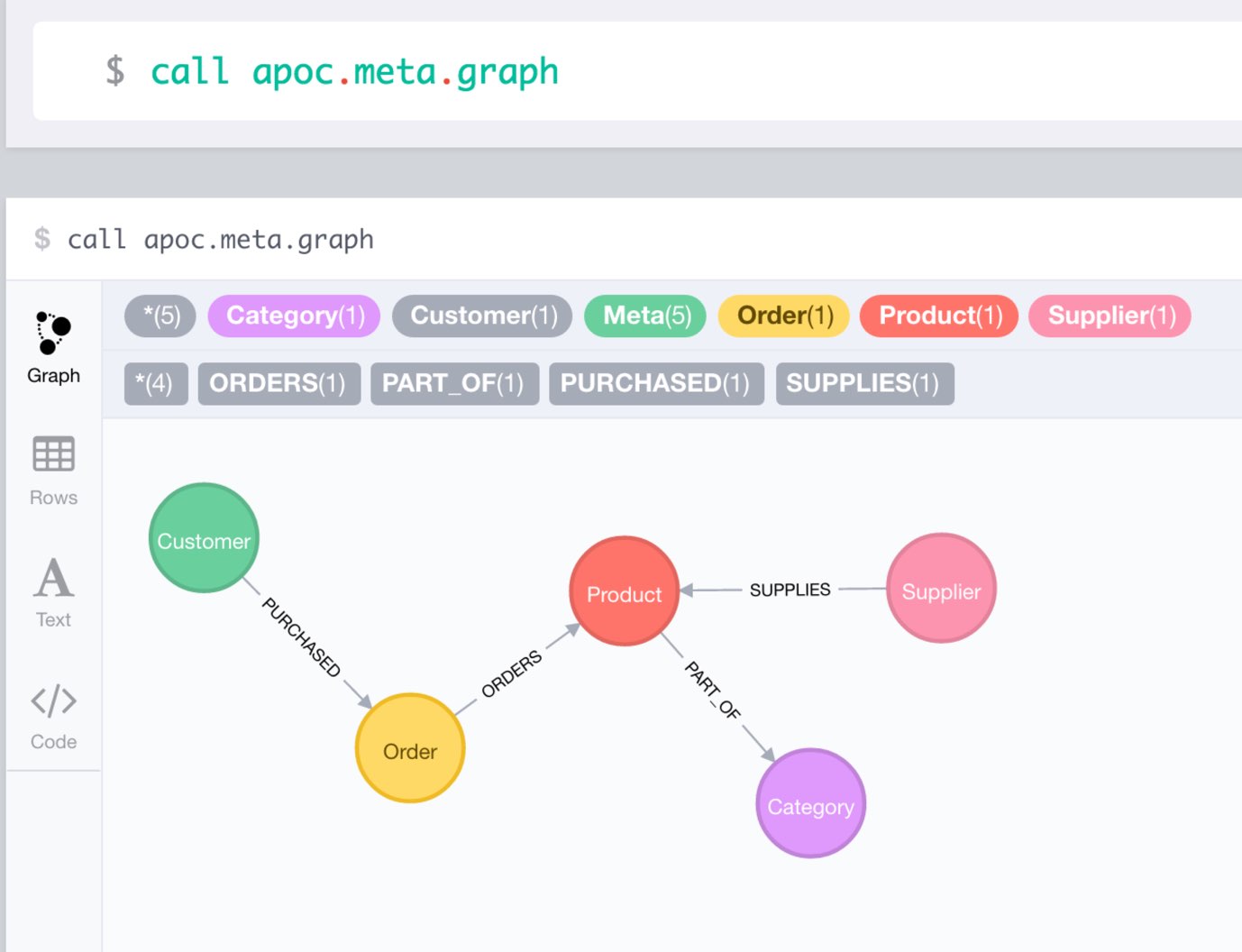
Returns a virtual graph that represents the labels and relationship-types available in your database and how they are connected.
|
examines the database statistics to build the meta graph, very fast, might report extra relationships |
|
examines the database statistics to create the meta-graph, post filters extra relationships by sampling |
|
examines a sample sub graph to create the meta-graph |
|
examines a subset of the graph to provide a tabular meta information |
|
examines a subset of the graph to provide a map-like meta information |
|
returns the information stored in the transactional database statistics |
|
type name of a value ( |
|
returns a row if type name matches none if not |
|
returns a a map of property-keys to their names |
MATCH (n:Person)
RETURN apoc.meta.isType(n.age,"INTEGER") as ageTypeSchema
|
drops all other existing indexes and constraints when |
Locking
|
acquires a write lock on the given nodes |
|
acquires a write lock on the given relationship |
|
acquires a write lock on the given nodes and relationships |
from/toJson
|
converts value to json string |
|
converts value to json map |
|
returns a JSON map with keys sorted alphabetically, with optional case sensitivity |
|
converts json list to Cypher list |
|
converts json map to Cypher map |
|
creates a stream of nested documents representing the at least one root of these paths |
|
converts serialized JSON in property back to original object |
|
converts serialized JSON in property back to map |
|
creates a stream of nested documents representing the at least one root of these paths |
|
sets value serialized to JSON as property with the given name on the node |
Export / Import
Export to CSV
YIELD file, source, format, nodes, relationships, properties, time, rows
|
exports results from the Cypher statement as CSV to the provided file |
|
exports whole database as CSV to the provided file |
|
exports given nodes and relationships as CSV to the provided file |
|
exports given graph object as CSV to the provided file |
Export to Cypher Script
Data is exported as Cypher statements to the given file.
It is possible to choose between three export formats:
-
neo4j-shell: for Neo4j Shell and partlyapoc.cypher.runFile -
cypher-shell: for Cypher shell -
plain: doesn’t output begin / commit / await just plain Cypher
To change the export format, you have to set it on the config params like {format : "cypher-shell"}.
By default the format is neo4j-shell.
It is possible to choose between four cypher export formats:
To change the cypher export format, you have to set it on the config params like {cypherFormat: "updateAll"}
-
create: all CREATE -
updateAll: MERGE instead of CREATE -
addStructure: MATCH for nodes + MERGE for rels -
updateStructure: MERGE + MATCH for nodes and rels
Format and cypherFormat can be used both in the same query giving you complete control over the exact export format:
call apoc.export.cypher.query(
"MATCH (p1:Person)-[r:KNOWS]->(p2:Person) RETURN p1,r,p2",
"/tmp/friendships.cypher",
{format:'plain',cypherFormat:'updateStructure'})`YIELD file, source, format, nodes, relationships, properties, time
|
exports whole database incl. indexes as Cypher statements to the provided file |
|
exports given nodes and relationships incl. indexes as Cypher statements to the provided file |
|
exports given graph object incl. indexes as Cypher statements to the provided file |
|
exports nodes and relationships from the Cypher statement incl. indexes as Cypher statements to the provided file |
|
exports all schema indexes and constraints to cypher |
Examples
CALL apoc.export.cypher.all({fileName},{config})Result:
begin
CREATE (:`Foo`:`UNIQUE IMPORT LABEL` {`name`:"foo", `UNIQUE IMPORT ID`:0});
CREATE (:`Bar` {`name`:"bar", `age`:42});
CREATE (:`Bar`:`UNIQUE IMPORT LABEL` {`age`:12, `UNIQUE IMPORT ID`:2});
commit
begin
CREATE INDEX ON :`Foo`(`name`);
CREATE CONSTRAINT ON (node:`Bar`) ASSERT node.`name` IS UNIQUE;
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT node.`UNIQUE IMPORT ID` IS UNIQUE;
commit
schema await
begin
MATCH (n1:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`:0}), (n2:`Bar`{`name`:"bar"}) CREATE (n1)-[:`KNOWS`]->(n2);
commit
begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
commit
begin
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT node.`UNIQUE IMPORT ID` IS UNIQUE;
commitCALL apoc.export.cypher.schema({fileName},{config})Result:
begin
CREATE INDEX ON :`Foo`(`name`);
CREATE CONSTRAINT ON (node:`Bar`) ASSERT node.`name` IS UNIQUE;
commit
schema awaitGraphML Import / Export
GraphML is used by other tools, like Gephi and CytoScape to read graph data.
YIELD file, source, format, nodes, relationships, properties, time
|
imports graphml into the graph |
|
exports whole database as graphml to the provided file |
|
exports given nodes and relationships as graphml to the provided file |
|
exports given graph object as graphml to the provided file |
|
exports nodes and relationships from the Cypher statement as graphml to the provided file |
| param | default | description |
|---|---|---|
batchSize |
20000 |
define the batch size |
delim |
"," |
define the delimiter character (export csv) |
quotes |
quote-character used for CSV |
|
useTypes |
false |
add type on file header (export csv and graphml export) |
format |
"neo4j-shell" |
In export to Cypher script define the export format. Possible values are: "cypher-shell","neo4j-shell" and "plain" |
nodesOfRelationships |
false |
if enabled add relationship between nodes (export Cypher) |
storeNodeIds |
false |
set nodes' ids (import/export graphml) |
readLabels |
false |
read nodes' labels (import/export graphml) |
defaultRelationshipType |
"RELATED" |
set relationship type (import/export graphml) |
separateFiles |
false |
export results in separated file by type (nodes, relationships..) |
cypherFormat |
create |
In export to cypher script, define the cypher format (for example use |
Loading Data from RDBMS
|
load from relational database, either a full table or a sql statement |
|
load from relational database, either a full table or a sql statement |
|
register JDBC driver of source database |
To simplify the JDBC URL syntax and protect credentials, you can configure aliases in conf/neo4j.conf:
apoc.jdbc.myDB.url=jdbc:derby:derbyDB
CALL apoc.load.jdbc('jdbc:derby:derbyDB','PERSON')
becomes
CALL apoc.load.jdbc('myDB','PERSON')
The 3rd value in the apoc.jdbc.<alias>.url= effectively defines an alias to be used in apoc.load.jdbc('<alias>',….
Loading Data from Web-APIs (JSON, XML, CSV)
Supported protocols are file, http, https with redirect allowed. In case no protocol is passed, this procedure set will try to check whether the url is actually a file.
Moreover, if 'apoc.import.file.use_neo4j_config' is enabled the procedures verify whether file system access is allowed and eventually constrained to a specific directory by
reading the two configuration parameters dbms.security.allow_csv_import_from_file_urls and dbms.directories.import respectively.
|
load from JSON URL (e.g. web-api) to import JSON as stream of values if the JSON was an array or a single value if it was a map |
|
load from XML URL (e.g. web-api) to import XML as single nested map with attributes and |
|
load from XML URL (e.g. web-api) to import XML as single nested map with attributes and |
|
load CSV fom URL as stream of values |
Adding on config the parameter failOnError:false (by default true), in case of error the procedure don’t fail but just return zero rows.
Interacting with Elastic Search
|
elastic search statistics |
|
perform a GET operation |
|
perform a SEARCH operation |
|
perform a raw GET operation |
|
perform a raw POST operation |
|
perform a POST operation |
|
perform a PUT operation |
Interacting with MongoDB
|
false]) yield value |
|
CALL apoc.mongodb.count(host-or-port,db-or-null,collection-or-null,query-or-null) yield value |
|
CALL apoc.mongodb.first(host-or-port,db-or-null,collection-or-null,query-or-null,[compatibleValues=true |
|
perform a first operation on mongodb collection |
|
false]) yield value |
|
CALL apoc.mongodb.insert(host-or-port,db-or-null,collection-or-null,list-of-maps) |
|
CALL apoc.mongodb.delete(host-or-port,db-or-null,collection-or-null,list-of-maps) |
|
CALL apoc.mongodb.update(host-or-port,db-or-null,collection-or-null,list-of-maps) |
If your documents have date fields or any other type that can be automatically converted by Neo4j, you need to set compatibleValues to true. These values will be converted according to Jackson databind default mapping.
Copy these jars into the plugins directory:
-
bson-3.4.2.jar
-
mongo-java-driver-3.4.2.jar
-
mongodb-driver-3.4.2.jar
-
mongodb-driver-core-3.4.2.jar
You should be able to get them from here, and here (BSON) (via Download)
Or you get them locally from your gradle build of apoc.
gradle copyRuntimeLibs cp lib/mongodb*.jar lib/bson*.jar $NEO4J_HOME/plugins/
CALL apoc.mongodb.first('mongodb://localhost:27017','test','test',{name:'testDocument'})If you need automatic conversion of unpackable values then the cypher query will be:
CALL apoc.mongodb.first('mongodb://localhost:27017','test','test',{name:'testDocument'},true)Interacting with Couchbase
|
Retrieves a couchbase json document by its unique ID |
|
Check whether a couchbase json document with the given ID does exist |
|
Insert a couchbase json document with its unique ID |
|
Insert or overwrite a couchbase json document with its unique ID |
|
Append a couchbase json document to an existing one |
|
Prepend a couchbase json document to an existing one |
|
Remove the couchbase json document identified by its unique ID |
|
Replace the content of the couchbase json document identified by its unique ID. |
|
Executes a plain un-parameterized N1QL statement. |
|
Executes a N1QL statement with positional parameters. |
|
Executes a N1QL statement with named parameters. |
Copy these jars into the plugins directory:
mvn dependency:copy-dependencies cp target/dependency/java-client-2.3.1.jar target/dependency/core-io-1.3.1.jar target/dependency/rxjava-1.1.5.jar $NEO4J_HOME/plugins/
CALL apoc.couchbase.get(['localhost'], 'default', 'artist:vincent_van_gogh')Streaming Data to Gephi
|
streams provided data to Gephi |
Creating Data
|
create node with dynamic labels |
|
create multiple nodes with dynamic labels |
|
adds the given labels to the node or nodes |
|
removes the given labels from the node or nodes |
|
sets the given property on the node(s) |
|
sets the given property on the nodes(s) |
|
sets the given property on the relationship(s) |
|
sets the given property on the relationship(s) |
|
create relationship with dynamic rel-type |
|
creates count UUIDs |
|
creates a linked list of nodes from first to last |
|
returns each node and a 'dense' flag if it is a dense node |
|
yields true effectively when the node has the relationships of the pattern |
|
returns an UUID |
Virtual Nodes/Rels
Virtual Nodes and Relationships don’t exist in the graph, they are only returned to the UI/user for representing a graph projection. They can be visualized or processed otherwise. Please note that they have negative id’s.
|
returns a virtual node |
|
returns a virtual node |
|
returns virtual nodes |
|
returns a virtual relationship |
|
returns a virtual relationship |
|
returns a virtual pattern |
|
returns a virtual pattern |
|
Group all nodes and their relationships by given keys, create virtual nodes and relationships for the summary information, you can provide an aggregations map for nodes and rels [{kids:'sum',age:['min','max','avg'],gender:'collect'},{ |
Virtual Graph
Create a graph object (map) from information that’s passed in.
It’s basic structure is: {name:"Name",properties:{properties},nodes:[nodes],relationships:[relationships]}
|
creates a virtual graph object for later processing it tries its best to extract the graph information from the data you pass in |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
|
creates a virtual graph object for later processing |
Generating Graphs
Generate undirected (random direction) graphs with semi-real random distributions based on theoretical models.
|
generates a graph according to Erdos-Renyi model (uniform) |
|
generates a graph according to Watts-Strogatz model (clusters) |
|
generates a graph according to Barabasi-Albert model (preferential attachment) |
|
generates a complete graph (all nodes connected to all other nodes) |
|
generates a graph with the given degree distribution |
Example
CALL apoc.generate.ba(1000, 2, 'TestLabel', 'TEST_REL_TYPE')
CALL apoc.generate.ws(1000, null, null, null)
CALL apoc.generate.simple([2,2,2,2], null, null)Warmup
(thanks @SaschaPeukert)
|
Warmup the node and relationship page-caches by loading one page at a time |
Monitoring
(thanks @ikwattro)
|
node and relationships-ids in total and in use |
|
store information such as kernel version, start time, read-only, database-name, store-log-version etc. |
|
store size information for the different types of stores |
|
number of transactions total,opened,committed,concurrent,rolled-back,last-tx-id |
|
db locking information such as avertedDeadLocks, lockCount, contendedLockCount and contendedLocks etc. (enterprise) |
Cypher Execution
|
executes reading fragment with the given parameters |
|
function that executes statement with given parameters returning first column only, if expectMultipleValues is true will collect results into a list |
|
runs each statement in the file, all semicolon separated - currently no schema operations |
|
runs each statement in the files, all semicolon separated |
|
CALL apoc.cypher.runSchemaFiles([files or urls]) - allows only schema operations, runs each schema statement in the files, all semicolon separated |
|
runs each semicolon separated statement and returns summary - currently no schema operations |
|
executes fragment in parallel batches with the list segments being assigned to _ |
|
executes writing fragment with the given parameters |
|
abort statement after timeout millis if not finished |
Conditional Cypher Execution
|
based on the conditional, executes read-only ifQuery or elseQuery with the given parameters |
|
based on the conditional, executes writing ifQuery or elseQuery with the given parameters |
|
given a list of conditional / read-only query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
|
given a list of conditional / writing query pairs, executes the query associated with the first conditional evaluating to true (or the else query if none are true) with the given parameters |
Triggers
Enable apoc.trigger.enabled=true in $NEO4J_HOME/config/neo4j.conf first.
|
add a trigger statement under a name, in the statement you can use {createdNodes}, {deletedNodes} etc., the selector is {phase:'before/after/rollback'} returns previous and new trigger information |
|
remove previously added trigger, returns trigger information |
|
update and list all installed triggers |
|
it pauses the trigger |
|
it resumes the paused trigger |
Helper Functions
|
function to filter labelEntries by label, to be used within a trigger statement with {assignedLabels} and {removedLabels} {phase:'before/after/rollback'} returns previous and new trigger information |
|
function to filter propertyEntries by property-key, to be used within a trigger statement with {assignedNode/RelationshipProperties} and {removedNode/RelationshipProperties}. Returns [{old,new,key,node,relationship}] |
Job Management
|
repeats an batch update statement until it returns 0, this procedure is blocking |
|
list all jobs |
|
submit a one-off background statement |
|
submit a repeatedly-called background statement |
|
submit a repeatedly-called background statement until it returns 0 |
|
iterate over first statement and apply action statement with given transaction batch size. Returns to numeric values holding the number of batches and the number of total processed rows. E.g. |
|
run the second statement for each item returned by the first statement. Returns number of batches and total processed rows |
-
there are also static methods
Jobs.submit, andJobs.scheduleto be used from other procedures -
jobs list is checked / cleared every 10s for finished jobs
name property of each person to lastnameCALL apoc.periodic.rock_n_roll('match (p:Person) return id(p) as id_p', 'MATCH (p) where id(p)={id_p} SET p.lastname =p.name', 20000)Graph Refactoring
|
clone nodes with their labels and properties |
|
clone nodes with their labels, properties and relationships |
|
merge nodes onto first in list |
|
merge relationships onto first in list |
|
redirect relationship to use new end-node |
|
redirect relationship to use new start-node |
|
inverts relationship direction |
|
change relationship-type |
|
extract node from relationships |
|
collapse node to relationship, node with one rel becomes self-relationship |
|
normalize/convert a property to be boolean |
|
turn each unique propertyKey into a category node and connect to it |
On mergeRelationship with config properties you can choose from 3 different management: * "overwrite" : if there is the same property in more relationship, in the new one will have the last relationship’s property value * "discard" : if there is the same property in more relationship, the new one will have the first relationship’s property value * "combine" : if there is the same property in more relationship, the new one a value’s array with all relationships' values
TODO:
-
merge nodes by label + property
Spatial
|
look up geographic location of location from openstreetmap geocoding service |
|
sort a given collection of paths by geographic distance based on lat/long properties on the path nodes |
Helpers
Static Value Storage
|
returns statically stored value from config (apoc.static.<key>) or server lifetime storage |
|
returns statically stored values from config (apoc.static.<prefix>) or server lifetime storage |
|
stores value under key for server livetime storage, returns previously stored or configured value |
Conversion Functions
Sometimes type information gets lost, these functions help you to coerce an "Any" value to the concrete type
|
tries it’s best to convert the value to a string |
|
tries it’s best to convert the value to a map |
|
tries it’s best to convert the value to a list |
|
tries it’s best to convert the value to a boolean |
|
tries it’s best to convert the value to a node |
|
tries it’s best to convert the value to a relationship |
|
tries it’s best to convert the value to a set |
Map Functions
|
creates map from nodes with this label grouped by property |
|
creates map from list with key-value pairs |
|
creates map from a keys and a values list |
|
creates map from alternating keys and values in a list |
|
creates map from merging the two source maps |
|
merges all maps in the list into one |
|
returns the map with the value for this key added or replaced |
|
returns the map with the key removed |
|
returns the map with the keys removed |
|
removes the keys and values (e.g. null-placeholders) contained in those lists, good for data cleaning from CSV/JSON |
|
creates a map of the list keyed by the given property, with single values |
|
creates a map of the list keyed by the given property, with list values |
|
returns a list of key/value list pairs, with pairs sorted by keys alphabetically, with optional case sensitivity |
returns map - adds the {data} map on each level of the nested tree, where the key-value pairs match |
Collection Functions
|
sum of all values in a list |
|
avg of all values in a list |
|
minimum of all values in a list |
|
maximum of all values in a list |
|
sums all numeric values in a list |
|
partitions a list into sublists of |
|
all values in a list |
|
[1,2],[2,3],[3,null] |
|
[1,2],[2,3] |
|
returns a unique list backed by a set |
|
sort on Collections |
|
sort nodes by property |
|
sort maps by map key |
|
returns the reversed list |
|
optimized contains operation (using a HashSet) (returns single row or not) |
|
optimized contains-all operation (using a HashSet) (returns single row or not) |
|
optimized contains on a sorted list operation (Collections.binarySearch) (returns single row or not) |
|
optimized contains-all on a sorted list operation (Collections.binarySearch) (returns single row or not) |
|
creates the distinct union of the 2 lists |
|
returns unique set of first list with all elements of second list removed |
|
returns first list with all elements of second list removed |
|
returns the unique intersection of the two lists |
|
returns the disjunct set of the two lists |
|
creates the full union with duplicates of the two lists |
|
splits collection on given values rows of lists, value itself will not be part of resulting lists |
|
position of value in the list |
|
returns the shuffled list |
|
returns a random item from the list |
|
returns a list of |
|
returns true if a collection contains duplicate elements |
|
returns a list of duplicate items in the collection |
|
returns a list of duplicate items in the collection and their count, keyed by |
|
returns the count of the given item in the collection |
|
sort list of maps by several sort fields (ascending with ^ prefix) and optionally applies limit and skip |
|
flattens a nested list |
Lookup Functions
|
id |
|
quickly returns all nodes with these id’s |
|
id |
|
quickly returns all relationships with these id’s |
Math Functions
|
rounds value with optionally given precision (default 0) and optional rounding mode (default HALF_UP) |
|
return the maximum value a long can have |
|
return the minimum value a long can have |
|
return the largest positive finite value of type double |
|
return the smallest positive nonzero value of type double |
|
return the maximum value a int can have |
|
return the minimum value a int can have |
|
return the maximum value a byte can have |
|
return the minimum value a byte can have |
Text Functions
|
replace each substring of the given string that matches the given regular expression with the given replacement. |
|
returns an array containing a nested array for each match. The inner array contains all match groups. |
|
join the given strings with the given delimiter. |
|
sprintf format the string with the params given |
|
left pad the string to the given width |
|
right pad the string to the given width |
|
returns domain part of the value |
|
returns a random string to the specified length |
|
capitalise the first letter of the word |
|
capitalise the first letter of every word in the text |
|
decapitalize the first letter of the word |
|
decapitalize the first letter of all words |
|
Swap the case of a string |
|
Convert a string to camelCase |
|
Convert a string to UpperCamelCase |
|
Convert a string to snake-case |
|
Convert a string to UPPER_CASE |
Phonetic Comparison Functions
|
Compute the US_ENGLISH phonetic soundex encoding of all words of the text value which can be a single string or a list of strings |
|
strip the given string of everything except alpha numeric characters and convert it to lower case. |
|
compare the given strings stripped of everything except alpha numeric characters converted to lower case. |
|
Compute the US_ENGLISH soundex character difference between two given strings |
Utilities
|
computes the sha1 of the concatenation of all string values of the list |
|
computes the md5 of the concatenation of all string values of the list |
|
sleeps for <duration> millis, transaction termination is honored |
|
raises exception if prediate evaluates to true |
Config
|
Lists the Neo4j configuration as key,value table |
|
Lists the Neo4j configuration as map |
Time to Live (TTL)
Enable TTL with setting in neo4j.conf : apoc.ttl.enabled=true
There are some convenience procedures to expire nodes.
You can also do it yourself by running
SET n:TTL
SET n.ttl = timestamp() + 3600
|
expire node in given time-delta by setting :TTL label and |
|
expire node at given time by setting :TTL label and |
Optionally set apoc.ttl.schedule=5 as repeat frequency.
Date/time Support
(thanks @tkroman)
Conversion Functions between formatted dates and timestamps
|
same as previous, but accepts custom datetime format |
|
the same as previous, but accepts custom datetime format |
|
return the system timezone display format string |
-
possible unit values:
ms,s,m,h,dand their long formsmillis,milliseconds,seconds,minutes,hours,days. -
possible time zone values: Either an abbreviation such as
PST, a full name such asAmerica/Los_Angeles, or a custom ID such asGMT-8:00. Full names are recommended. You can view a list of full names in this Wikipedia page.
Conversion of timestamps between different time units
-
apoc.date.convert(12345, 'ms', 'd')convert a timestamp in one time unit into one of a different time unit -
possible unit values:
ms,s,m,h,dand their long forms.
Adding/subtracting time unit values to timestamps
-
apoc.date.add(12345, 'ms', -365, 'd')given a timestamp in one time unit, adds a value of the specified time unit -
possible unit values:
ms,s,m,h,dand their long forms.
Reading separate datetime fields
Splits date (optionally, using given custom format) into fields returning a map from field name to its value.
-
apoc.date.fields('2015-03-25 03:15:59')
Current timestamp
apoc.date.currentTimestamp() provides the System.currentTimeMillis which is current throughout transaction execution compared to Cypher’s timestamp() function which does not update within a transaction
Bitwise operations
Provides a wrapper around the java bitwise operations.
apoc.bitwise.op(a long, "operation", b long ) as <identifier> |
examples
operator |
name |
example |
result |
a & b |
AND |
apoc.bitwise.op(60,"&",13) |
12 |
a | b |
OR |
apoc.bitwise.op(60,"|",13) |
61 |
a ^ b |
XOR |
apoc.bitwise.op(60,"&",13) |
49 |
~a |
NOT |
apoc.bitwise.op(60,"&",0) |
-61 |
a << b |
LEFT SHIFT |
apoc.bitwise.op(60,"<<",2) |
240 |
a >> b |
RIGHT SHIFT |
apoc.bitwise.op(60,">>",2) |
15 |
a >>> b |
UNSIGNED RIGHT SHIFT |
apoc.bitwise.op(60,">>>",2) |
15 |
Path Expander
(thanks @keesvegter)
The apoc.path.expand procedure makes it possible to do variable length path traversals where you can specify the direction of the relationship per relationship type and a list of Label names which act as a "whitelist" or a "blacklist" or define end nodes for the expansion. The procedure will return a list of Paths in a variable name called "path".
|
expand from given nodes(s) taking the provided restrictions into account |
Variations allow more configurable expansions, and expansions for more specific use cases:
|
expand from given nodes(s) taking the provided restrictions into account |
|
expand a subgraph from given nodes(s) taking the provided restrictions into account; returns all nodes in the subgraph |
|
expand a subgraph from given nodes(s) taking the provided restrictions into account; returns the collection of subgraph nodes, and the collection of all relationships within the subgraph |
|
expand a spanning tree from given nodes(s) taking the provided restrictions into account; the paths returned collectively form a spanning tree |
Relationship Filter
Syntax: [<]RELATIONSHIP_TYPE1[>]|[<]RELATIONSHIP_TYPE2[>]|…
| input | type | direction |
|---|---|---|
|
|
OUTGOING |
|
|
INCOMING |
|
|
BOTH |
Label Filter
Syntax: [+-/>]LABEL1|LABEL2|…
As of APOC 3.1.3.x multiple label filter operations are allowed.
In prior versions, only one type of operation is allowed in the label filter (+ or - or / or >, never more than one).
With APOC 3.2.x.x, label filters will no longer apply to starting nodes of the expansion by default.
| input | label | result |
|---|---|---|
|
|
blacklist filter - No node in the path will have a label in the blacklist. |
|
|
whitelist filter - All nodes in the path must have a label in the whitelist (exempting termination and end nodes, if using those filters). If no whitelist operator is present, all labels are considered whitelisted. |
|
|
termination filter - Only return paths up to a node of the given labels, and stop further expansion beyond it. Termination nodes do not have to respect the whitelist. Termination filtering takes precedence over end node filtering. |
|
|
end node filter - Only return paths up to a node of the given labels, but continue expansion to match on end nodes beyond it. End nodes do not have to respect the whitelist to be returned, but expansion beyond them is only allowed if the node has a label in the whitelist. |
Uniqueness
Uniqueness of nodes and relationships guides the expansion and the returned results.
Uniqueness is only configurable using expandConfig().
subgraphNodes(), subgraphAll(), and spanningTree() all use 'NODE_GLOBAL' uniqueness.
| value | description |
|---|---|
|
For each returned node there’s a (relationship wise) unique path from the start node to it. This is Cypher’s default expansion mode. |
|
A node cannot be traversed more than once. This is what the legacy traversal framework does. |
|
Entities on the same level are guaranteed to be unique. |
|
For each returned node there’s a unique path from the start node to it. |
|
This is like NODE_GLOBAL, but only guarantees uniqueness among the most recent visited nodes, with a configurable count. Traversing a huge graph is quite memory intensive in that it keeps track of all the nodes it has visited. For huge graphs a traverser can hog all the memory in the JVM, causing OutOfMemoryError. Together with this Uniqueness you can supply a count, which is the number of most recent visited nodes. This can cause a node to be visited more than once, but scales infinitely. |
|
A relationship cannot be traversed more than once, whereas nodes can. |
|
Entities on the same level are guaranteed to be unique. |
|
Same as for NODE_RECENT, but for relationships. |
|
No restriction (the user will have to manage it) |
Parallel Node Search
Utility to find nodes in parallel (if possible). These procedures return a single list of nodes or a list of 'reduced' records with node id, labels, and the properties where the search was executed upon.
|
A distinct set of Nodes will be returned. |
|
All the found Nodes will be returned. |
|
A merged set of 'minimal' Node information will be returned. One record per node (-id). |
|
All the found 'minimal' Node information will be returned. One record per label and property. |
|
|
(JSON or Map) For every Label-Property combination a search will be executed in parallel (if possible): Label1.propertyOne, label2.propOne and label2.propTwo. |
|
'exact' or 'contains' or 'starts with' or 'ends with' |
Case insensitive string search operators |
|
"<", ">", "=", "<>", "⇐", ">=", "=~" |
Operators |
|
'Keanu' |
The actual search term (string, number, etc). |
CALL apoc.search.nodeAll('{Person: "name",Movie: ["title","tagline"]}','contains','her') YIELD node AS n RETURN n
call apoc.search.nodeReduced({Person: 'born', Movie: ['released']},'>',2000) yield id, labels, properties RETURN *Graph Algorithms (work in progress)
Provides some graph algorithms (not very optimized yet)
|
run dijkstra with relationship property name as cost function |
|
run dijkstra with relationship property name as cost function and a default weight if the property does not exist |
|
run A* with relationship property name as cost function |
|
run A* with relationship property name as cost function |
|
run allSimplePaths with relationships given and maxNodes |
|
compute degree distribution in parallel |
|
calculate betweenness centrality for given nodes |
|
calculate closeness centrality for given nodes |
|
return relationships between this set of nodes |
|
calculates page rank for given nodes |
|
calculates page rank for given nodes |
|
simple label propagation kernel |
|
search the graph and return all maximal cliques at least at large as the minimum size argument. |
|
search the graph and return all maximal cliques that are at least as large than the minimum size argument and contain this node |
|
Compute cosine similarity |
|
Compute Euclidean distance |
|
Compute Euclidean similarity |
Example: find the weighted shortest path based on relationship property d from A to B following just :ROAD relationships
MATCH (from:Loc{name:'A'}), (to:Loc{name:'D'})
CALL apoc.algo.dijkstra(from, to, 'ROAD', 'd') yield path as path, weight as weight
RETURN path, weightPerformance Tests
Import and Export to Cypher
Refers to the issue #439 we documented some performance tests of export and import of a big graph into Cypher format file. For the test we used a server with this characteristics:
-
6 cores
-
Intel® Xeon® CPU E5-1650 v2 @ 3.50GHz
-
128 GB of RAM
-
dbms.memory.heap.initial_size=8192m
-
dbms.memory.heap.max_size=8192m
-
dbms.memory.pagecache.size=4g
They have not be noticed significative difference with 4 GB of heap memory.
-
total nodes 3.158.994
-
total relationships 16.800.936
Download here LDBC SF1
Script to execute all the tests
We created a script that execute all the tests explained below, you can run it like in this example:
./performanceCypherTest.sh 'neo4jHome' 'userName' 'password' 'address'the address parameter is optional, the default address is : bolt://localhost:7687
If you use the LDBC SF1 graph, or another big one is better to change the open files allowed from the default 1024 at last to 40.000.
Download performanceCypherTest.sh
Export all
Batch size
With the use of the config param batchSize we done some tests with different batch size.
The default value is 20000.
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.export.cypher.all('yourPath/exportAll', {format:'neo4j-shell', batchSize: 10000})"Results
real 1m52.744s user 0m0.936s sys 0m0.064s
real 1m50.715s user 0m0.932s sys 0m0.076s
real 1m49.577s user 0m0.888s sys 0m0.120s
real 1m51.297s user 0m0.928s sys 0m0.088s
Different output formats
We try the different output formats, changing the config parameter format.
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.export.cypher.all('yourPath/exportData.cypher', {format:'neo4j-shell'})"Results
real 1m49.268s user 0m0.904s sys 0m0.072s
real 1m55.089s user 0m0.892s sys 0m0.092s
real 1m54.490s user 0m0.932s sys 0m0.076s
Many files (separateFiles config)
With the param separateFiles (default false) we can export our graph or part of it, in different files.
In the example below we name the exported file exportAll.cypher so our export will be:
-
exportAll.cleanup.cypher
-
exportAll.nodes.cypher
-
exportAll.relationships.cypher
-
exportAll.schema.cypher
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.export.cypher.all('yourPath/exportAll.cypher', {format:'neo4j-shell',separateFiles:true})"Result
real 1m55.229s user 0m0.960s sys 0m0.084s
Export from query
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.export.cypher.query('MATCH (n) OPTIONAL MATCH p = (n)-[r]-(m) RETURN n,r,m',
'yourPath/exportQuery.cypher', {format:'neo4j-shell', batchSize: 10000})"Result
real 3m34.924s user 0m0.992s sys 0m0.068s
Export from given nodes and rels
time ./cypher-shell -u yourUsername -p yourPassword "Match (n:Person)-[r:LIKES_COMMENT]->(c:Comment)
with collect(n) as colN, collect(c) as colC, collect(r) as colR
CALL apoc.export.cypher.data(colN+colC,colR, 'yourPath/exportData.cypher',{format:'plain'}) YIELD nodes, relationships
RETURN nodes, relationships"Result
real 2m30.576s user 0m6.264s sys 0m0.372s
Export from graph object
time ./cypher-shell -u yourUsername -p yourPassword "CALL apoc.graph.fromDB('test',{})
yield graph CALL apoc.export.cypher.graph(graph, 'yourPath/exportGraph.cypher',null)
YIELD nodes, relationships
RETURN nodes, relationships"Result
real 4m50.006s user 17m26.149s sys 0m13.145s
real 5m6.467s user 19m14.328s sys 0m11.821s
real 4m57.598s user 17m26.557s sys 0m13.465s
Import Schema file
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.cypher.runSchemaFile('yourPath/exportPlain.schema.cypher')"Result
real 0m0.683s user 0m0.896s sys 0m0.092s
Import from file
runFile
The runFile procedure takes much time to import from files like the ones we’ve generated before.
These file has more than 19.000.000 rows.
It was created an issue about this #500.
time ./cypher-shell -u yourUsername -p yourPassword
"call apoc.cypher.runFile('yourPath/import/exportPlain.cypher')"With this command we import not more than 10/15 nodes per second.
Import cypher-shell
time ./cypher-shell -u yourUsername -p yourPassword
< 'yourPath/import/exportCypherShell.cypher'
> 'yourPath/cypherShellOutput'real 890m38.003s user 43m34.935s sys 23m10.951s
-
imported nodes 3.158.994
-
imported relationships 16.800.936
Import neo4j-shell
time ./neo4j-shell -u yourUsername -p yourPassword -file
< 'yourPath/import/exportNeo4jShell.cypher'
> 'yourPath/neo4jShellOutput'We tried to import the DB via neo4j-shell, but after 24 hours it was still uploading. We tried with a subset of the graph :
-
130.000 nodes
-
500.000 relationships
The result is that neo4j-shell is 7 times slower than the cypher-shell.
Cypher-shell
real 14m43.923s user 1m1.448s sys 0m48.556s
Neo4j-shell
real 98m54.617s user 21m5.140s sys 37m35.852s
Import and Export to GraphML
Refers to the issue #440 we documented some performance tests of export and import of a big graph into GraphML format.
Script to execute all the tests
We created a script that execute all the tests explained below, you can run it like in this example:
./performanceGraphmlTest.sh 'neo4jHome' 'userName' 'password' 'address'Export all
call apoc.export.graphml.all('yourPath/exportAll.graphml',null)Results
real 1m25.530s user 0m0.968s sys 0m0.068s
real 1m53.521s user 0m0.908s sys 0m0.096s
real 1m26.898s user 0m0.900s sys 0m0.096s
real 1m30.592s user 0m0.916s sys 0m0.116s
real 1m30.829s user 0m0.928s sys 0m0.068s
call apoc.export.graphml.all('yourPath/exportAll.graphml',{storeNodeIds:true, readLabels:true, useTypes:true, defaultRelationshipType:'RELATED'})Export GraphML from query
call apoc.export.graphml.query(
'MATCH (n) OPTIONAL MATCH p = (n)-[r]-(m) RETURN n,r,m',
'yourPath/exportQuery.graphml', {useTypes:true})Results
real 3m2.257s user 0m0.972s sys 0m0.084s
real 3m15.295s user 0m0.860s sys 0m0.132s
Export GraphML from Graph object
CALL apoc.graph.fromDB('test',{}) yield graph
CALL apoc.export.graphml.graph(graph, 'yourPath/exportGraph.graphml',null)
YIELD nodes, relationships, properties, file, source,format, time
RETURN *Results
real 4m12.586s user 15m27.490s sys 0m20.609s
real 4m44.876s user 16m46.379s sys 0m13.421s
Export GraphML from given nodes and rels
MATCH (n:Person)-[r:LIKES_COMMENT]->(c:Comment)
WITH collect(n) as colN, collect(c) as colC, collect(r) as colR
CALL apoc.export.cypher.data(colN+colC,colR, 'yourPath/exportData.graphml',{useTypes:true})
YIELD nodes, relationships
RETURN 'none'Results
real 3m54.067s user 0m6.648s sys 0m0.496s
real 4m29.370s user 0m6.676s sys 0m0.436s
Import GraphML
Test of import in a blank database of the export files created before
call apoc.import.graphml('yourPath/exportAll.graphml',{batchSize: 10000})real 6m50.497s user 0m1.032s sys 0m0.084s
| file | source | format | nodes | relationships | properties | time | rows |
|---|---|---|---|---|---|---|---|
'yourPath/exportAll.graphml' |
"file" |
"graphml" |
3158994 |
16800936 |
42538498 |
409761 |
0 |
Like we can see from the output we have the same number of nodes and relationship.
"call apoc.import.graphml('yourPath/exportAllConfig.graphml',
{batchSize: 10000, readLabels: true, storeNodeIds: false, defaultRelationshipType:'RELATED'})real 6m44.330s user 0m0.976s sys 0m0.100s
| file | source | format | nodes | relationships | properties | time | rows |
|---|---|---|---|---|---|---|---|
'yourPath/exportAll.graphml' |
"file" |
"graphml" |
3158994 |
16800936 |
22578568 |
403615 |
0 |
Import on Gephi
We tried to import a subset of the graph on Gephi :
-
25.000 nodes
-
1.000.000 relationships
-
153.000 properties
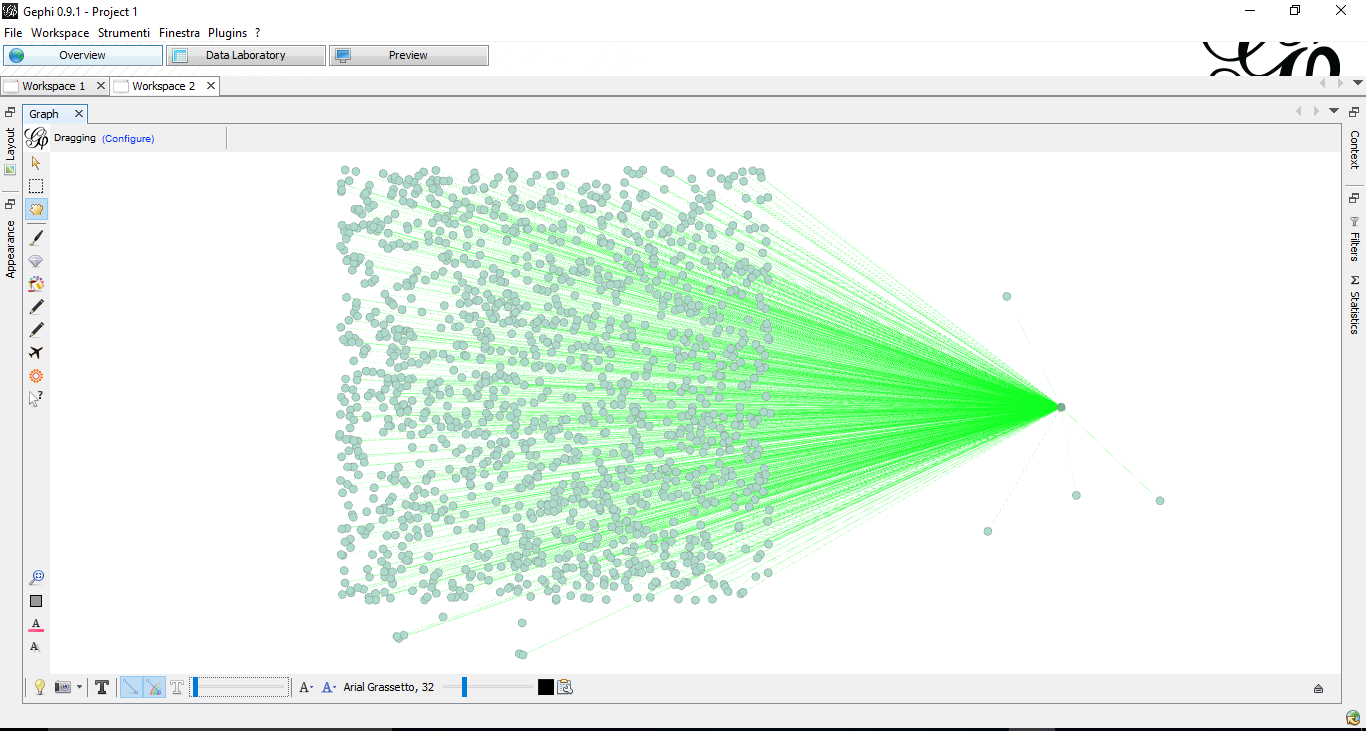
The file has been imported in few seconds.
Import on yEd
With the same subset we tried to import it on yEd. The export file has to convert into UTF-8.