Overview
Features
-
Neo4j-ETL UI in Neo4j Desktop
-
Manage multiple RDBMS connections
-
automatically extract database metadata from relational database
-
derive graph model
-
visually edit labels, relationship-types, property-names and types
-
visualize current model as a graph
-
persist mapping as json
-
retrieve relevant CSV data from relational databases
-
run import via neo4j-import, bolt-connector, cypher-shell, neo4j-shell
-
bundles MySQL, PostgreSQL, allows custom JDBC driver with Neo4j Enterprise
License
This tool is licensed under the NEO4J PRE-RELEASE LICENSE AGREEMENT.
Issues & Feedback & Contributions
-
You can raise GitHub issues or send feedback to feedback@neo4j.com
-
Please also join our neo4j-users Slack and ask in the #help-import channel
Download & Run
Download & unzip the latest neo4j-etl.zip.
Examples of command usage:
./bin/neo4j-etl export \ --rdbms:url <url> --rdbms:user <user> --rdbms:password <password> \ --destination $NEO4J_HOME/data/databases/graph.db/ --import-tool $NEO4J_HOME/bin \ --csv-directory $NEO4J_HOME/import
./bin/neo4j-etl export \
--rdbms:url <url> --rdbms:user <user> --rdbms:password <password> --rdbms:schema <schema> \
--using { bulk:neo4j-import | cypher:neo4j-shell | cypher:shell | cypher:direct } \
--neo4j:url <neo4j url> --neo4j:user <neo4j user> --neo4j:password <neo4j password> \
--destination $NEO4J_HOME/data/databases/graph.db/ --import-tool $NEO4J_HOME/bin \
--csv-directory $NEO4J_HOME/import --options-file import-tool-options.json --force --debug
For detailed usage see also the: tool documentation.
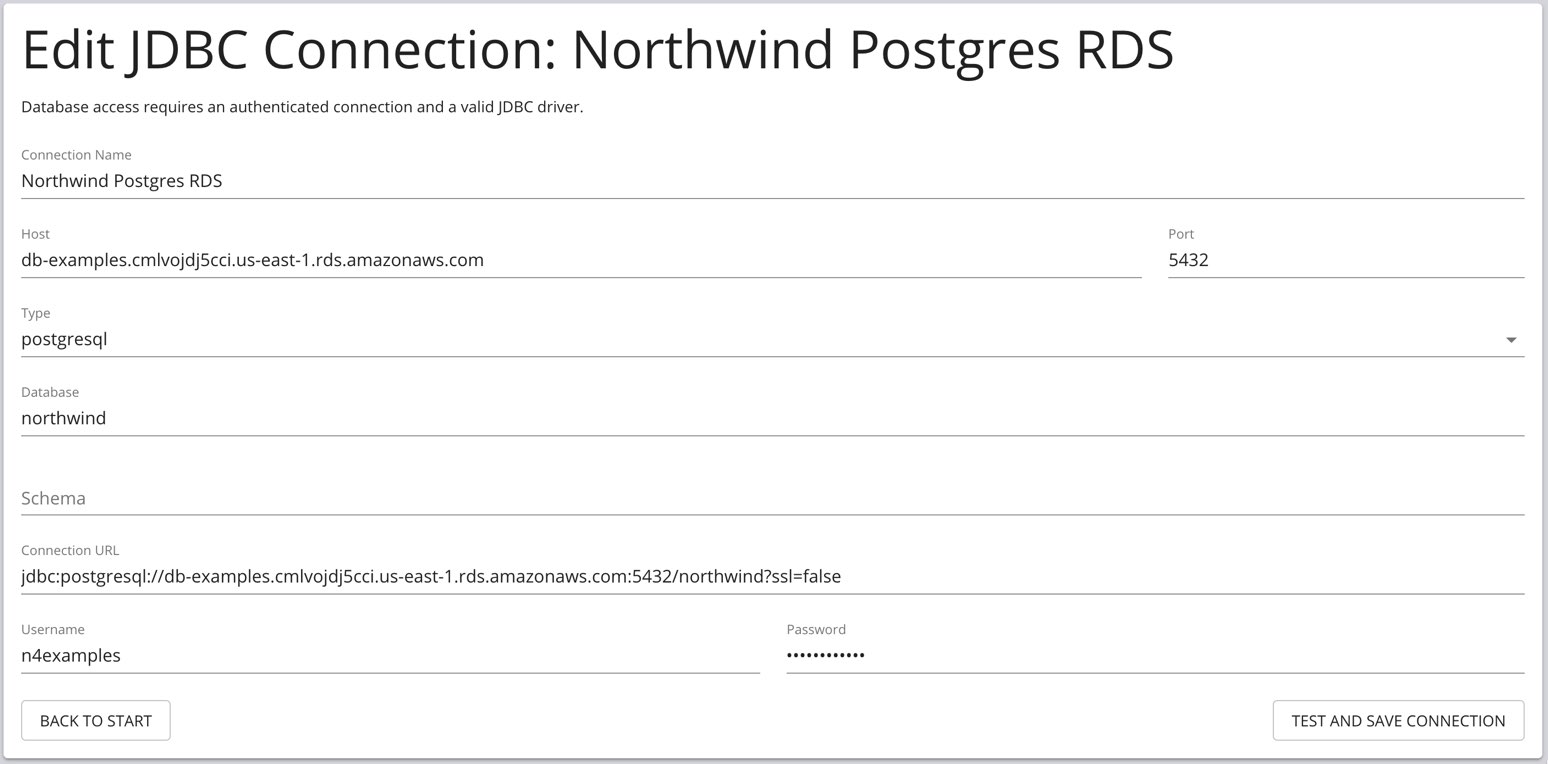
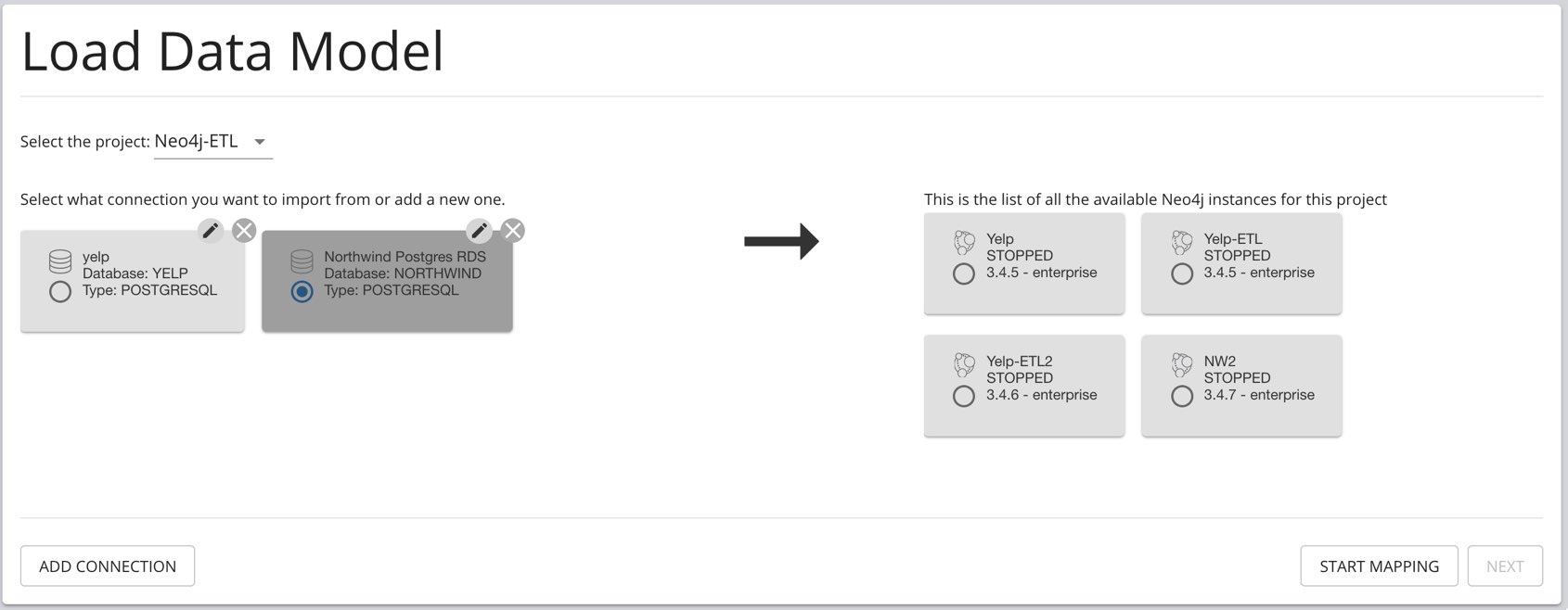
Neo4j-Desktop
You can add Neo4j ETL to Neo4j Desktop by adding the appropriate application key. Please ask your Neo4j contact or send an email to devrel@neo4j.com
Then the next time you start Neo4j Desktop you’ll see Neo4j ETL as a UI to be used interactively.
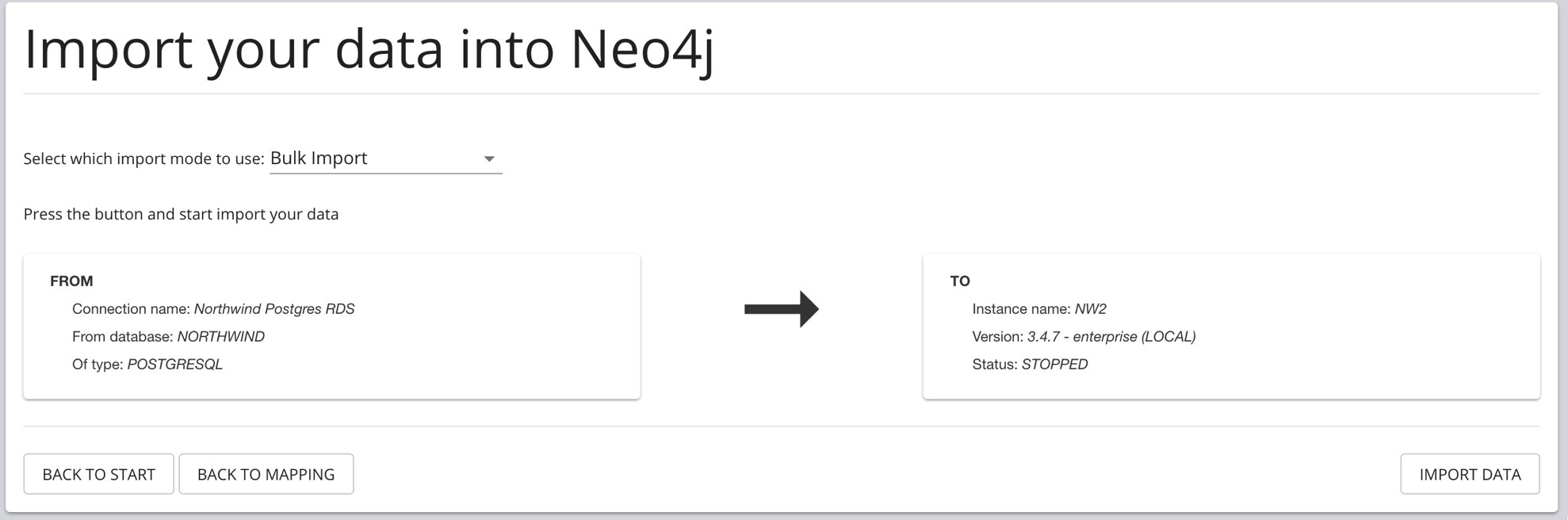
| Configure Driver | Load Mapping | Edit Mapping | Import Data |
|---|---|---|---|
|
|
|
|
JDBC Drivers
The drivers for MySQL and PostgreSQL are bundled with the Neo4j-ETL tool.
To use other JDBC drivers use these download links and JDBC URLs.
Provide the JDBC driver jar-file to the command line tool or Neo4j-ETL application.
And use the JDBC-URL with the --rdbms:url parameter or in the JDBC-URL input field.
| Database | JDBC-URL | Driver Source |
|---|---|---|
Oracle |
|
|
MS SQLServer |
|
|
IBM DB2 |
|
|
Derby |
|
Included since JDK6 |
Cassandra |
|
|
SAP Hana |
|
|
MySQL |
|
|
PostgreSQL |
|
Introduction
The Neo4j ETL, especially the neo4j-etl command-line tool, can be used to import well modeled (i.e. normalized) relational data into Neo4j.
It applies some simple rules for transforming the relational model.
The process as outlined below:
-
Read database metadata and generate mapping.json
-
Optionally edit mapping.json with the
neo4j-etl-uiin Neo4j Desktop -
Export relational data to CSV
-
Generate Mapping Headers
-
Import into Neo4j using
-
the
neo4j-importtool for initial offline bulk load -
the
neo4j-shelltool for incremental offline bulk load -
the
cypher-shelltool for incremental online single-transaction load -
the
java bolt driverfor incremental online batch load
-
Architecture Diagram
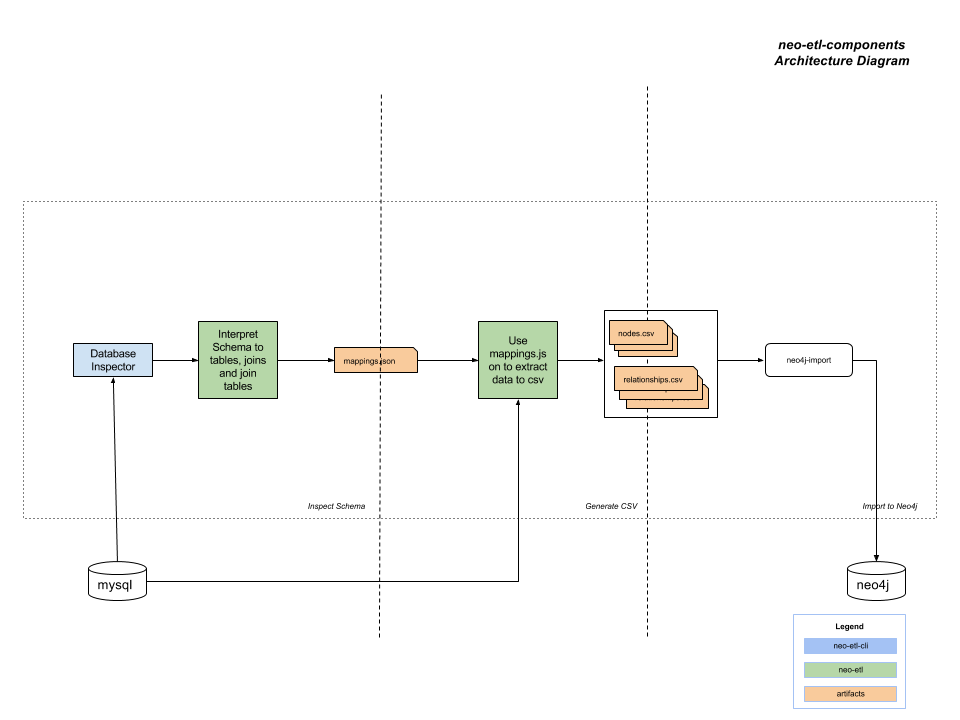
What it is
-
Command-Line tools
-
Java API/library
-
Infer Schema and save in mapping file
-
Filter and merge strategies
-
Read mapping file to export data from other databases then
-
Import into Neo via different tools (
neo4j-import,neo4j-shell,cypher-shell,java bolt driver) -
Work in offline and online mode
-
Import in both an empty (initial load) and not-empty graph (incremental)
-
Build indexes and constraints
-
Support on Unix-like and Microsoft Operating Systems
-
Support for most popular relational databases like MySQL, PostgreSQL, Oracle and Microsoft SQL
-
Support user specified JDBC drivers
-
UI tool to visually modify mappings
Plans for the Future
-
Custom Mapping Rules + Transformations for names, data, links
-
Exemplary integration into a 3rd party ETL pipeline
-
More data types (binary, datetime, geo)
Who is it for
-
Developer learning to work with Neo4j for initial data import
-
Partners providing data integration with Neo4j
-
Enterprise developers building applications based on well modeled relational data
Open Questions
-
Date and binary datatypes
-
Security (secure connections, handling of passwords, encrypting data)
neo4j-etl Command Line Tool
This is the command-line tool you use to retrieve and map the metadata from your relational database and drive the export from the relational and import into Neo4j database.
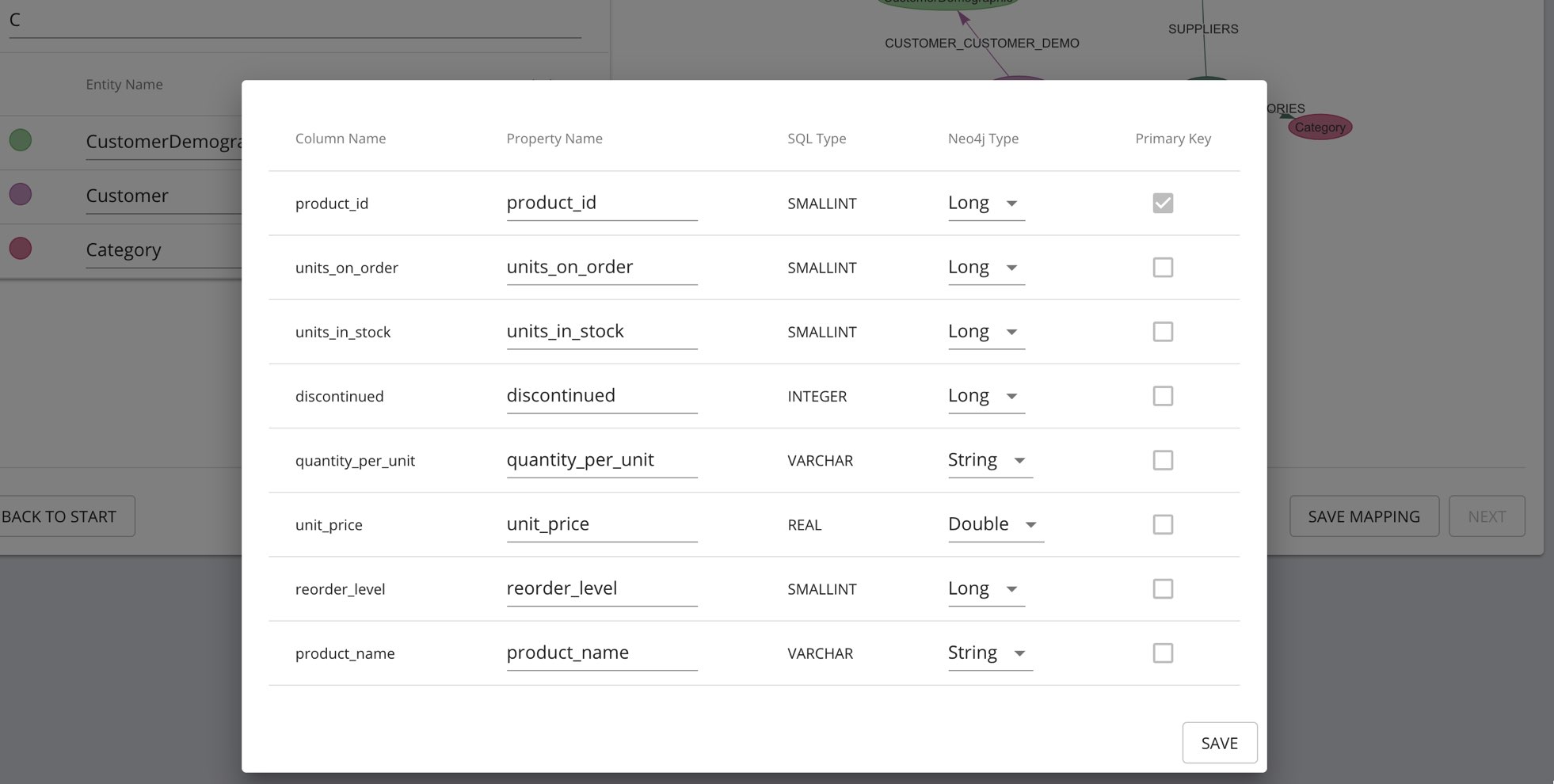
With the graphical user interface you can preview the resulting graph data model and eventually adapt it by changing labels, property names, relationship-types and property types.
It supports all relational databases with a JDBC driver, like MySQL, PostgreSQL, Oracle and Microsoft SQL.
You can get the latest version of the import tool from GitHub.
Once downloaded and uncompressed the operating system specific zip / tar.gz, you also need download the proper JDBC Driver and add it to the lib folder.
You can follow the proper link in the below table in order to download the proper driver jar
| Vendor | JDBC Driver URL |
|---|---|
http://www.oracle.com/technetwork/database/features/jdbc/default-2280470.html |
|
https://www.microsoft.com/en-us/download/details.aspx?id=55539 |
|
Note
|
For very large databases make sure to have enough disk-space for the CSV export and the Neo4j datastore and enough RAM and CPUs to finish the import quickly. |
Available commands
'generate-metadata-mapping' command
NAME
neo4j-etl generate-metadata-mapping - Create RDBMS to Neo4j metadata
mapping Json.
SYNOPSIS
neo4j-etl generate-metadata-mapping
[ {--columns | --cols} <Columns>... ]
[ --config-file <Configuration File> ]
[ {-d | --database} <RDBMS database> ] [ --debug ]
[ --delimiter <delimiter> ] [ {--driver | --jars} <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>... ]
[ {--exclusion-mode | --exc} <Tables: exclude|include|none(default)> ]
[ {--exclusion-mode-column-type | --exctype} <exclude|include|none(default)> ]
[ {--exclusion-mode-columns | --excc} <exclude|include|none(default)> ]
[ {--exclusion-mode-tables | --exct} <exclude|include|none(default)> ]
[ --options-file <option file> ] [ --output-mapping-file <file|stdout> ]
[ {-p | --port} <RDBMS port> ] [ --quote <quote> ]
[ {--rdbms:fetch-size | --fs} <fetch-size> ]
[ {--rdbms:password | --password} <RDBMS password> ]
[ {--rdbms:schema | -s | --schema} <schema> ]
[ {--rdbms:url | --url} <RDBMS url> ]
[ {--rdbms:user | -u | --user} <RDBMS user> ]
[ {--relationship-name | --rel-name} <table(default)|column> ]
[ --schemas <Schemas>... ] [ {--tables | --tabs} <Tables>... ]
[ --tiny-int <byte(default)|boolean> ] [ --types <Types>... ] [--] [ <table1 table2 ...>... ]
OPTIONS
--columns <Columns>, --cols <Columns>
Lists all columns to include/exclude by name or pattern
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.orders\..*_id' or
'northwind\.orders\..*_id' ,
'-g' <PATTERN> for grep syntax, ex. '-g .*\.orders\..*_id' or
'northwind\.orders\..*_id' ,
or '-l' <LIST> to list all columns names ex. '-l
northwind.customers.id,northwind.purchase.id,northwind.orders.id'
--config-file <Configuration File>
Specify the path to a file containing the configuration for the
selected command
-d <RDBMS database>, --database <RDBMS database>
RDBMS database.
This option is required if any of the following options are
specified: host
--debug
Print detailed diagnostic output.
--delimiter <delimiter>
Delimiter to separate fields in CSV.
--driver <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>, --jars <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>
List of additional drivers as a list
--exclusion-mode <Tables: exclude|include|none(default)>, --exc <Tables: exclude|include|none(default)>
Specifies how to handle table exclusion. Options are mutually
exclusive.
exclude: Excludes specified tables from the process. All other
tables will be included.
include: Includes specified tables only. All other tables will be
excluded.
none: All tables are included in the process.
--exclusion-mode-column-type <exclude|include|none(default)>, --exctype
<exclude|include|none(default)>
Specifies how to handle column type exclusion. Options are mutually
exclusive.
exclude: Excludes specified columns types from the process. All
other columns types will be included.
include: Includes specified columns types only. All other columns
types will be excluded.
none: All columns types are included in the process.
--exclusion-mode-columns <exclude|include|none(default)>, --excc
<exclude|include|none(default)>
Specifies how to handle column exclusion. Options are mutually
exclusive.
exclude: Excludes specified columns from the process. All other
columns will be included.
include: Includes specified columns only. All other columns will be
excluded.
none: All columns are included in the process.
--exclusion-mode-tables <exclude|include|none(default)>, --exct
<exclude|include|none(default)>
Specifies how to handle table exclusion. Options are mutually
exclusive.
exclude: Excludes specified tables from the process. All other
tables will be included.
include: Includes specified tables only. All other tables will be
excluded.
none: All tables are included in the process.
--options-file <option file>
Path to file containing Neo4j import tool options.
--output-mapping-file <file|stdout>
Path to the output metadata mapping file.
-p <RDBMS port>, --port <RDBMS port>
Port number to use for connection to RDBMS.
--quote <quote>
Character to treat as quotation character for values in CSV data.
--rdbms:fetch-size <fetch-size>, --fs <fetch-size>
RDBMS Fetch size
--rdbms:password <RDBMS password>, --password <RDBMS password>
Password for login to RDBMS.
This option is required if any of the following options are
specified: --rdbms:url, --url
--rdbms:schema <schema>, -s <schema>, --schema <schema>
RDBMS schema.
--rdbms:url <RDBMS url>, --url <RDBMS url>
Url to use for connection to RDBMS.
--rdbms:user <RDBMS user>, -u <RDBMS user>, --user <RDBMS user>
User for login to RDBMS.
This option is required if any of the following options are
specified: --rdbms:url, --url
--relationship-name <table(default)|column>, --rel-name
<table(default)|column>
Specifies whether to get the name for relationships from table names
or column names.
--schemas <Schemas>
Lists all schemas to include by name or pattern.
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.north.*',
'-g' <PATTERN> for grep syntax, ex. '-g .*\.north.*' ,
or '-l' <LIST> to list all schemas names ex. '-l northwind,exc'
--tables <Tables>, --tabs <Tables>
Lists all tables to include/exclude by name or pattern.
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.purchase.*' or
'northwind.purchase.*' ,
'-g' <PATTERN> for grep syntax, ex. '-g .*\.purchase.*' or
'northwind.purchase.*' ,
or '-l' <LIST> to list all tables names ex. '-l
customers,purchase,orders'
--tiny-int <byte(default)|boolean>
Specifies whether to convert TinyInt to byte or boolean
--types <Types>
Lists all column types to include/exclude by name separated by
commas. Valid values:
unknown,
binary,
bit,
character,
id,
integer,
real,
reference,
temporal,
url,
xml,
large_object,
object;
--
This option can be used to separate command-line options from the
list of arguments (useful when arguments might be mistaken for
command-line options)
<table1 table2 ...>
Tables to be excluded/included
'export' command
NAME
neo4j-etl export - Export from RDBMS and import into NEO4J via CSV
files.
SYNOPSIS
neo4j-etl export [ {--columns | --cols} <Columns>... ]
[ --config-file <Configuration File> ]
[ --csv-directory <csv directory> ]
[ {-d | --database} <RDBMS database> ] [ --debug ]
[ --delimiter <delimiter> ] [ --destination <directory> ] [ {--driver | --jars} <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>... ]
[ {--exclusion-mode | --exc} <Tables: exclude|include|none(default)> ]
[ {--exclusion-mode-column-type | --exctype} <exclude|include|none(default)> ]
[ {--exclusion-mode-columns | --excc} <exclude|include|none(default)> ]
[ {--exclusion-mode-tables | --exct} <exclude|include|none(default)> ]
[ --force ] [ --import-tool <import tool path> ]
[ --mapping-file <file|stdin> ] [ {--neo4j:password | --graph:password | --graph:neo4j:password} <neo4j password> ]
[ {--neo4j:url | --graph:url | --graph:neo4j:url} <neo4j url> ]
[ {--neo4j:user | --graph:user | --graph:neo4j:user} <neo4j user> ]
[ --options-file <option file> ] [ --output-mapping-file <file|stdout> ]
[ {-p | --port} <RDBMS port> ] [ --quote <quote> ]
[ {--rdbms:fetch-size | --fs} <fetch-size> ]
[ {--rdbms:password | --password} <RDBMS password> ]
[ {--rdbms:schema | -s | --schema} <schema> ]
[ {--rdbms:url | --url} <RDBMS url> ]
[ {--rdbms:user | -u | --user} <RDBMS user> ]
[ {--relationship-name | --rel-name} <table(default)|column> ]
[ --schemas <Schemas>... ] [ {--tables | --tabs} <Tables>... ]
[ --tiny-int <byte(default)|boolean> ] [ --types <Types>... ]
[ --using <import tool> ] [--] [ <table1 table2 ...>... ]
OPTIONS
--columns <Columns>, --cols <Columns>
Lists all columns to include/exclude by name or pattern
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.orders\..*_id' or
'northwind\.orders\..*_id' ,
'-g' <PATTERN> for grep syntax, ex. '-g .*\.orders\..*_id' or
'northwind\.orders\..*_id' ,
or '-l' <LIST> to list all columns names ex. '-l
northwind.customers.id,northwind.purchase.id,northwind.orders.id'
--config-file <Configuration File>
Specify the path to a file containing the configuration for the
selected command
--csv-directory <csv directory>
Path to directory for intermediate CSV files.
-d <RDBMS database>, --database <RDBMS database>
RDBMS database.
This option is required if any of the following options are
specified: host
--debug
Print detailed diagnostic output.
--delimiter <delimiter>
Delimiter to separate fields in CSV.
--destination <directory>
Path to destination store directory.
--driver <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>, --jars <--driver <PATH_TO_YOUR_JAR1> --driver <PATH_TO_YOUR_JAR2>>
List of additional drivers as a list
--exclusion-mode <Tables: exclude|include|none(default)>, --exc <Tables: exclude|include|none(default)>
Specifies how to handle table exclusion. Options are mutually
exclusive.
exclude: Excludes specified tables from the process. All other
tables will be included.
include: Includes specified tables only. All other tables will be
excluded.
none: All tables are included in the process.
--exclusion-mode-column-type <exclude|include|none(default)>, --exctype
<exclude|include|none(default)>
Specifies how to handle column type exclusion. Options are mutually
exclusive.
exclude: Excludes specified columns types from the process. All
other columns types will be included.
include: Includes specified columns types only. All other columns
types will be excluded.
none: All columns types are included in the process.
--exclusion-mode-columns <exclude|include|none(default)>, --excc
<exclude|include|none(default)>
Specifies how to handle column exclusion. Options are mutually
exclusive.
exclude: Excludes specified columns from the process. All other
columns will be included.
include: Includes specified columns only. All other columns will be
excluded.
none: All columns are included in the process.
--exclusion-mode-tables <exclude|include|none(default)>, --exct
<exclude|include|none(default)>
Specifies how to handle table exclusion. Options are mutually
exclusive.
exclude: Excludes specified tables from the process. All other
tables will be included.
include: Includes specified tables only. All other tables will be
excluded.
none: All tables are included in the process.
--force
Force delete destination store directory if it already exists.
--import-tool <import tool path>
Path to directory containing Neo4j import tool.
--mapping-file <file|stdin>
Path to an existing metadata mapping file. The name 'stdin' will
cause the CSV resources definitions to be read from standard input.
--neo4j:password <neo4j password>, --graph:password <neo4j password>,
--graph:neo4j:password <neo4j password>
Password for login to Neo4j.
--neo4j:url <neo4j url>, --graph:url <neo4j url>, --graph:neo4j:url
<neo4j url>
Url to use for connection to Neo4j.
--neo4j:user <neo4j user>, --graph:user <neo4j user>, --graph:neo4j:user
<neo4j user>
User for login to Neo4j.
--options-file <option file>
Path to file containing Neo4j import tool options.
--output-mapping-file <file|stdout>
Path to the output metadata mapping file.
-p <RDBMS port>, --port <RDBMS port>
Port number to use for connection to RDBMS.
--quote <quote>
Character to treat as quotation character for values in CSV data.
--rdbms:fetch-size <fetch-size>, --fs <fetch-size>
RDBMS Fetch size
--rdbms:password <RDBMS password>, --password <RDBMS password>
Password for login to RDBMS.
This option is required if any of the following options are
specified: --rdbms:url, --url
--rdbms:schema <schema>, -s <schema>, --schema <schema>
RDBMS schema.
--rdbms:url <RDBMS url>, --url <RDBMS url>
Url to use for connection to RDBMS.
--rdbms:user <RDBMS user>, -u <RDBMS user>, --user <RDBMS user>
User for login to RDBMS.
This option is required if any of the following options are
specified: --rdbms:url, --url
--relationship-name <table(default)|column>, --rel-name
<table(default)|column>
Specifies whether to get the name for relationships from table names
or column names.
--schemas <Schemas>
Lists all schemas to include by name or pattern.
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.north.*',
'-g' <PATTERN> for grep syntax, ex. '-g .*\.north.*' ,
or '-l' <LIST> to list all schemas names ex. '-l northwind,exc'
--tables <Tables>, --tabs <Tables>
Lists all tables to include/exclude by name or pattern.
Use '-r' <PATTERN> to filter by regex, ex. '-r .*\.purchase.*' or
'northwind.purchase.*' ,
'-g' <PATTERN> for grep syntax, ex. '-g .*\.purchase.*' or
'northwind.purchase.*' ,
or '-l' <LIST> to list all tables names ex. '-l
customers,purchase,orders'
--tiny-int <byte(default)|boolean>
Specifies whether to convert TinyInt to byte or boolean
--types <Types>
Lists all column types to include/exclude by name separated by
commas. Valid values:
unknown,
binary,
bit,
character,
id,
integer,
real,
reference,
temporal,
url,
xml,
large_object,
object;
--using <import tool>
Import tool that will be used to load data into neo4j.
--
This option can be used to separate command-line options from the
list of arguments (useful when arguments might be mistaken for
command-line options)
<table1 table2 ...>
Tables to be excluded/included
Parameters Usage
There are two ways for write Etl parameters:
1) write parameters in command line:
$NEO4J_HOME/bin/neo4j-etl export|generate-metadata-mapping
--rdbms:url jdbc:oracle:thin:@localhost:49161:XE
--rdbms:user northwind --rdbms :password northwind
--rdbms:schema northwind
--using bulk:neo4j-import
--import-tool $NEO4J_HOME/bin
--csv-directory /tmp/northwind
--options-file /tmp/northwind/options.json
--quote '"' --force
...
2) use a config file:
$NEO4J_HOME/bin/neo4j-etl export|generate-metadata-mapping \
--config-file <path to .config file>
Above there is an Example of config file.
#EXAMPLE - ETL CONFIG FILE
#RDBMS
rdbms-url=url
rdbms-schema=schema
rdbms-password=neo4j
rdbms-user=neo4j
rdbms-fetch-size=10000
#NEO4J
using=cypher:direct
neo4j-url=bolt://127.0.0.1:7687
neo4j-user=neo4j
neo4j-password=neo4j
#RULES
exclusion-mode-tables=INCLUDE
tables=-l table1,table2,...
exclusion-mode-columns=INCLUDE
columns=-l column1,column2,...
exclusion-mode-column-types=EXCLUDE
column-types=type1,type2,...
#MISC
output-mapping-file=path_to_output_mapping_file
import-tool=path_to_import_tool
csv-directory=path_to_directory
mapping-file=path_to_file
debug=false
Example Session: Basic
Generate Metadata Mapping
export NEO4J_HOME=/path/to/neo4j-enterprise-3.4.0 mkdir -p /tmp/northwind $NEO4J_HOME/bin/neo4j-etl generate-metadata-mapping \ --rdbms:url jdbc:oracle:thin:@localhost:49161:XE \ --rdbms:user northwind --rdbms:password northwind \ --rdbms:schema northwind --output-mapping-file /tmp/northwind/mapping.json
Offline Bulk Import via neo4j-import tool for initial load (Neo4j database must be empty)
echo '{ "multiline-fields" : "true" }' > /tmp/northwind/options.json
$NEO4J_HOME/bin/neo4j-etl export \
--rdbms:url jdbc:oracle:thin:@localhost:49161:XE \
--rdbms:user northwind --rdbms :password northwind \
--rdbms:schema northwind \
--using bulk:neo4j-import \
--import-tool $NEO4J_HOME/bin \
--csv-directory /tmp/northwind \
--options-file /tmp/northwind/options.json \
--quote '"' --force
$NEO4J_HOME/bin/neo4j-shell -path $NEO4J_HOME/data/databases/graph.db/ -c 'MATCH (n) RETURN labels(n), count(*);' +--------------------------+ | labels(n) | count(*) | +--------------------------+ | ["Shipper"] | 3 | | ["Employee"] | 9 | | ["Region"] | 4 | | ["Customer"] | 93 | | ["Territory"] | 53 | | ["Product"] | 77 | | ["Supplier"] | 29 | | ["Order"] | 830 | | ["Category"] | 8 | +--------------------------+ 9 rows
Online Batch Import via java-bolt-driver for incremental load (neo4j can be already populated)
echo '{ "multiline-fields" : "true" }' > /tmp/northwind/options.json
$NEO4J_HOME/bin/neo4j-etl export \
--rdbms:url jdbc:oracle:thin:@localhost:49161:XE \
--rdbms:user northwind --rdbms:password northwind \
--rdbms:schema northwind \
--using cypher:direct \
--neo4j:url bolt://localhost:7687 \
--neo4j:user neo4j --neo4j:password neo4j \
--import-tool $NEO4J_HOME/bin \
--csv-directory /tmp/northwind \
--options-file /tmp/northwind/options.json \
--quote '"' --force
$NEO4J_HOME/bin/cypher-shell -a bolt://localhost:7687 -u neo4j -p neo4j 'MATCH (n) RETURN labels(n), count(*);' +--------------------------+ | labels(n) | count(*) | +--------------------------+ | ["Shipper"] | 3 | | ["Employee"] | 9 | | ["Region"] | 4 | | ["Customer"] | 93 | | ["Territory"] | 53 | | ["Product"] | 77 | | ["Supplier"] | 29 | | ["Order"] | 830 | | ["Category"] | 8 | +--------------------------+ 9 rows
Example Session: Docker + Northwind
This example session is based on the Northwind example dataset.
DDL scripts are available here:
MySQL
Download, start and configure the docker container with MySQL:
docker pull mysql docker run --name neo4j-etl-mysql -e MYSQL_ROOT_PASSWORD=admin -e MYSQL_DATABASE=northwind -e MYSQL_USER=neo4j -e MYSQL_PASSWORD=neo4j -d -p 3306:3306 mysql:latest docker exec -it neo4j-etl-mysql bash root@eb6f279fdb88:/# mysql -u root -p Enter password: admin Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.18 MySQL Community Server (GPL) Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> grant all privileges on *.* to 'neo4j'@'%' with grant option; Query OK, 0 rows affected (0.00 sec) mysql> quit; Bye root@bf99fbc0d31c:/# exit exit
Load the database via the following sql script: https://raw.githubusercontent.com/neo4j-contrib/neo4j-etl/master/neo4j-etl-it/src/main/resources/scripts/mysql/northwind.sql
export NEO4J_HOME=/path/to/neo4j-enterprise-3.4.0
mkdir -p /tmp/northwind
echo '{ "multiline-fields" : "true" }' > /tmp/northwind/options.json
./bin/neo4j-etl export \
--rdbms:url jdbc:mysql://localhost:5433/northwind?autoReconnect=true&useSSL=false \
--rdbms:user neo4j --rdbms:password neo4j \
--import-tool $NEO4J_HOME/bin \
--options-file /tmp/northwind/options.json \
--csv-directory /tmp/northwind \
--destination $NEO4J_HOME/data/databases/graph.db/ \
--quote '"' --force
PostgreSQL
Download, start and configure the docker container with PostgreSQL 9.6.2:
docker pull postgres docker run --name neo4j-etl-postgres -e POSTGRES_USER=neo4j -e POSTGRES_PASSWORD=neo4j -d -p 5433:5432 postgres docker run -it --rm --link neo4j-etl-postgres:postgres postgres psql -h postgres -U neo4j Password for user neo4j: psql (9.6.2) Type "help" for help. neo4j=# DROP DATABASE IF EXISTS northwind; neo4j=# CREATE DATABASE northwind WITH OWNER 'neo4j' ENCODING 'UTF8' LC_COLLATE = 'en_US.utf8' LC_CTYPE = 'en_US.utf8'; neo4j=# \q
Load the database via the following sql script: northwind.sql
export NEO4J_HOME=/path/to/neo4j-enterprise-3.4.0
mkdir -p /tmp/northwind
echo '{"multiline-fields":"true"}' > /tmp/northwind/options.json
./bin/neo4j-etl export \
--rdbms:url jdbc:postgresql://localhost:5433/northwind?ssl=false \
--rdbms:user neo4j --rdbms:password neo4j \
--import-tool $NEO4J_HOME/bin \
--options-file /tmp/northwind/options.json \
--csv-directory /tmp/northwind \
--destination $NEO4J_HOME/data/databases/graph.db/ \
--quote '"' --force
Oracle
Download, start and configure the docker container with Oracle XE 11g:
docker pull wnameless/oracle-xe-11g
docker run --name neo4j-etl-oracle -d -p 49160:22 -p 49161:1521 wnameless/oracle-xe-11g
ssh root@localhost -p 49160
root@localhost's password: admin
Welcome to Ubuntu 16.04.1 LTS (GNU/Linux 4.9.13-moby x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Mon May 1 17:32:48 2017 from 172.17.0.1
root@692c446a274b:~# wget https://raw.githubusercontent.com/neo4j-contrib/neo4j-etl/master/neo4j-etl-it/src/main/resources/scripts/oracle/northwind.sql
root@692c446a274b:~# sqlplus system/oracle
SQL> CREATE USER northwind IDENTIFIED BY northwind;
SQL> GRANT DBA TO northwind;
SQL> CONN northwind/northwind;
SQL> SET sqlblanklines ON;
SQL> @northwind.sql
SQL> quit;
root@692c446a274b:~# exit
export NEO4J_HOME=/path/to/neo4j-enterprise-3.4.0
mkdir -p /tmp/northwind
echo '{"multiline-fields":"true"}' > /tmp/northwind/options.json
./bin/neo4j-etl export \
--rdbms:url jdbc:oracle:thin:@localhost:49161:XE \
--rdbms:user northwind --rdbms:password northwind \
--rdbms:schema northwind \
--import-tool $NEO4J_HOME/bin \
--options-file /tmp/northwind/options.json \
--csv-directory /tmp/northwind \
--destination $NEO4J_HOME/data/databases/graph.db/ \
--quote '"' --force
--driver /tmp/ojdbc6-11.2.0.3.jar
Microsoft SQL
Download, start and configure the docker container with Microsoft SQL Server:
docker run --name neo4j-etl-mssql -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Passw0rd!' -p 1433:1433 -d microsoft/mssql-server-linux
If you want to connect to Microsoft SQL client console then you can run the following command:
docker exec -it neo4j-etl-mssql /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P 'Passw0rd!' -d <DATABASE>
export NEO4J_HOME=/path/to/neo4j-enterprise-3.4.0
mkdir -p /tmp/wideworldimporters
echo '{"multiline-fields":"true"}' > /tmp/wideworldimporters/options.json
./bin/neo4j-etl export \
--rdbms:password "Passw0rd!" \
--rdbms:user sa \
--rdbms:url "jdbc:sqlserver://localhost:1433;databaseName=WideWorldImporters" \
--import-tool $NEO4J_HOME/bin \
--options-file /tmp/wideworldimporters/options.json \
--csv-directory /tmp/wideworldimporters \
--destination $NEO4J_HOME/data/databases/graph.db/ \
--driver /tmp/mssql-jdbc-6.1.0.jre8.jar \
How to import World Wide Importers database into a MS SQL server Docker instance
# Create docker instance for MS-SQL Server docker run --name mssql-etl \ -e MSSQL_COLLATION=Latin1_General_100_CI_AS \ -e 'ACCEPT_EULA=Y' \ -e 'SA_PASSWORD=<YOUR_PASSWORD>' \ -p 1433:1433 \ -v /tmp:/tmp \ -d microsoft/mssql-server-linux:2017-latest # Download World Wide Importers backup file wget https://github.com/Microsoft/sql-server-samples/releases/download/wide-world-importers-v1.0/WideWorldImporters-Full.bak # Create a backup directory sudo docker exec -it mssql-etl mkdir /var/opt/mssql/backup # Load backup file into the container sudo docker cp WideWorldImporters-Full.bak mssql-etl:/var/opt/mssql/backup # Restore Wide World Importers database sudo docker exec -it mssql-etl /opt/mssql-tools/bin/sqlcmd \ -S localhost \ -U SA \ -P '<YOUR_PASSWORD>' \ -Q 'RESTORE FILELISTONLY FROM DISK = "/var/opt/mssql/backup/WideWorldImporters-Full.bak"' \ | tr -s ' ' \ | cut -d ' ' -f 1-2 sudo docker exec -it mssql-etl /opt/mssql-tools/bin/sqlcmd \ -S localhost \ -U SA \ -P '<YOUR_PASSWORD>' \ -Q 'RESTORE DATABASE WideWorldImporters FROM DISK = "/var/opt/mssql/backup/WideWorldImporters-Full.bak" WITH MOVE "WWI_Primary" TO "/var/opt/mssql/data/WideWorldImporters.mdf", MOVE "WWI_UserData" TO "/var/opt/mssql/data/WideWorldImporters_userdata.ndf", MOVE "WWI_Log" TO "/var/opt/mssql/data/WideWorldImporters.ldf", MOVE "WWI_InMemory_Data_1" TO "/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1"'
Capabilities
Inferring Schema with Mapping Rules (generate-metadata-mapping)
-
Generic relational database mapping based on the following rules
-
A table with a foreign key is treated as a Join and imported as a node with a relationship
-
Ex:
Person -> Addressis imported as(Person)-[:ADDRESS_ID]->(Address) -
A table that has two foreign keys is imported as a JoinTable and imported as a relationship
-
Ex:
Student <- Student_Course -> Courseis imported as
(Student) -[:STUDENT_COURSE]-> (Course) -
A table that has more than two foreign keys is treated as an intermediate node and imported as node with multiple relationships
-
Ex:
Order_Detail -> Shipping_Address, Order_Detail -> Payment_Information, Order_Detail -> Shipment_Instructionsis imported as
(Shipping_Address) -[:SHIPPING]-> (Order_Detail) (Payment_Information) -[:PAYMENT]-> (Order_Detail) (Shipment_Instructions) -[:SHIPMENT]-> (Order_Detail)
-
Resolve relationships through composite keys.
-
Support most of the data types.
-
TinyInt can be imported as either Byte or as a Boolean (This is to support boolean values being saved in mysql as TinyInt)
-
Dates are imported as String
-
Blobs are skipped while importing until the import-tool supports binary array data.
-
Decimal to be confirmed.
-
-
Relationship names can either take column name or the table that is being referred to
-
--relationship-name=tablethen aPerson->Addresswill become(Person)-[:ADDRESS]->(Address) -
--relationship-name=columnwill become(Person)-[:ADDRESS_ID]->(Address)
-
-
Filter tables that you want to include or exclude using
--includeand--exclude -
TODO: Filter columns that you want to include or exclude using
--includeand--exclude -
TODO: Retaining natural keys(marked as PrimaryKeys and ForeignKeys) as needed using <TBA> flag
-
A Foreign Key is usually used to create a relationship between 2 nodes without being saved as a property.
-
With this flag, the node would keep that value as a property.
-
Ex: A loan has the SSN of the loan applicant which would normally be used to connect the
LoanandPersonnodes. -
With this flag the
Loannode will also keep theSSNas a property.
-
Edit Mapping via UI
A Neo4j-ETL graph application can be added Neo4j Desktop which allows visual editing of the mapping and interactive import.
The UI allows you to change and set you preferred label names, property names and types, relationship types, with a preview of the resulting graph.
Exporting Data (export)
-
Generate CSV files from relational source as outlined by
mappings.json-
TODO: Use a streaming api that is more performant
-
-
Import CSV providing the correct labels and rel-types and headers headers
-
TODO: Missing ability to pass options to
neo4j-importtool as a file instead of command line arguments -
TODO: Create indexes and constraints related to not-primary key columns
-