Many existing (enterprise) applications, endpoints and files use XML as data exchange format.
To make these datastructures available to Cypher, you can use apoc.load.xml.
It takes a file or http URL and parses the XML into a map datastructure.
|
in previous releases we’ve had |
See the following usage-examples for the procedures.
"How do you access XML doc attributes in children fields ?"
(Thanks Nicolas Rouyer)
For example, if my XML file is the example book.xml provided by Microsoft.
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies,
...We have the file here, on GitHub.
In a simpler XML representation, each type of children gets it’s own entry within the parent map. The element-type as key is prefixed with "_" to prevent collisions with attributes.
If there is a single element, then the entry will just have that element as value, not a collection. If there is more than one element there will be a list of values.
Each child will still have its _type field to discern them.
Here is the example file from above loaded with apoc.load.xmlSimple
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml", '', {}, true){_type: "catalog", _book: [
{_type: "book", id: "bk101",
_author: [{_type: "author", _text: "Gambardella, Matthew"},{_type: author, _text: "Arciniegas, Fabio"}],
_title: {_type: "title", _text: "XML Developer's Guide"},
_genre: {_type: "genre", _text: "Computer"},
_price: {_type: "price", _text: "44.95"},
_publish_date: {_type: "publish_date", _text: "2000-10-01"},
_description: {_type: description, _text: An in-depth look at creating applications ....Example 1.
WITH "https://maps.googleapis.com/maps/api/directions/xml?origin=Mertens%20en%20Torfsstraat%2046,%202018%20Antwerpen&destination=Rubensstraat%2010,%202300%20Turnhout&sensor=false&mode=bicycling&alternatives=false&key=AIzaSyAPPIXGudOyHD_KAa2f_1l_QVNbsd_pMQs" AS url
CALL apoc.load.xmlSimple(url) YIELD value
RETURN value._route._leg._distance._value, keys(value), keys(value._route), keys(value._route._leg), keys(value._route._leg._distance._value)
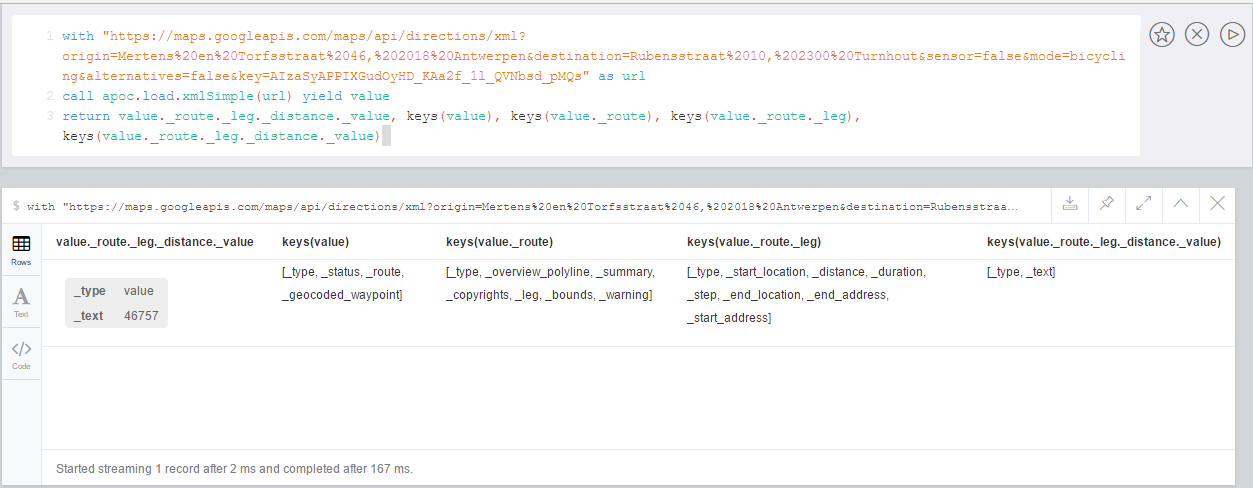
Example 2.
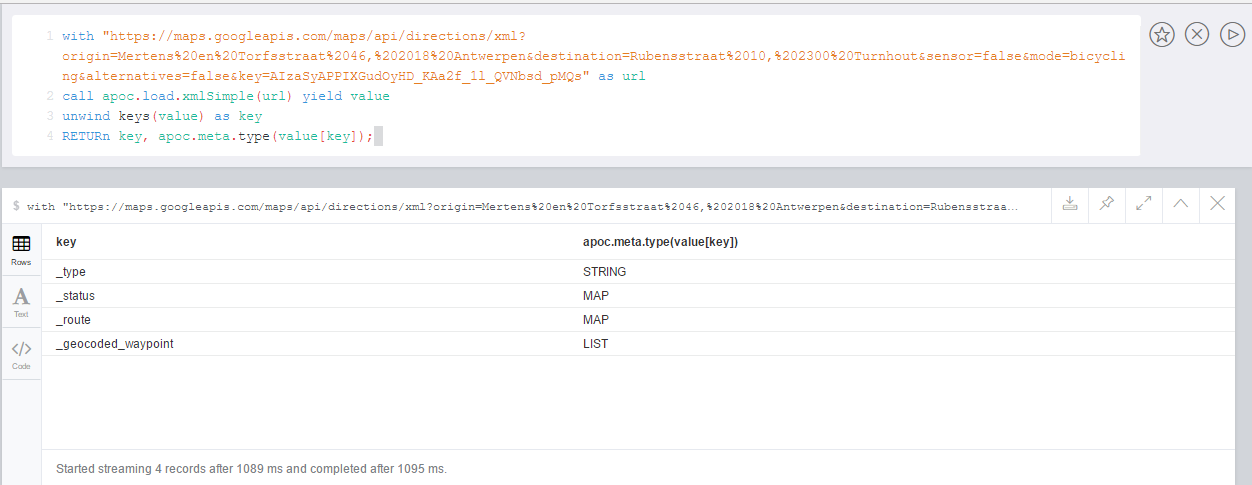
WITH "https://maps.googleapis.com/maps/api/directions/xml?origin=Mertens%20en%20Torfsstraat%2046,%202018%20Antwerpen&destination=Rubensstraat%2010,%202300%20Turnhout&sensor=false&mode=bicycling&alternatives=false&key=AIzaSyAPPIXGudOyHD_KAa2f_1l_QVNbsd_pMQs" AS url
CALL apoc.load.xmlSimple(url) YIELD value
UNWIND keys(value) AS key
RETURN key, apoc.meta.type(value[key]);
You can provide a map of HTTP headers to the config property.
WITH { `X-API-KEY`: 'abc123' } as headers,
WITH "https://myapi.com/api/v1/" AS url
CALL apoc.load.xml(url, '', { headers: headers }) YIELD value
UNWIND keys(value) AS key
RETURN key, apoc.meta.type(value[key]);It’s possible to define a xPath (optional) to selecting nodes from the XML document.
From the Microsoft’s book.xml file we can get only the books that have as genre Computer
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml", '/catalog/book[genre=\"Computer\"]') yield value as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['title','price'] | attr._text] as pairs
RETURN id, pairs[0] as title, pairs[1] as price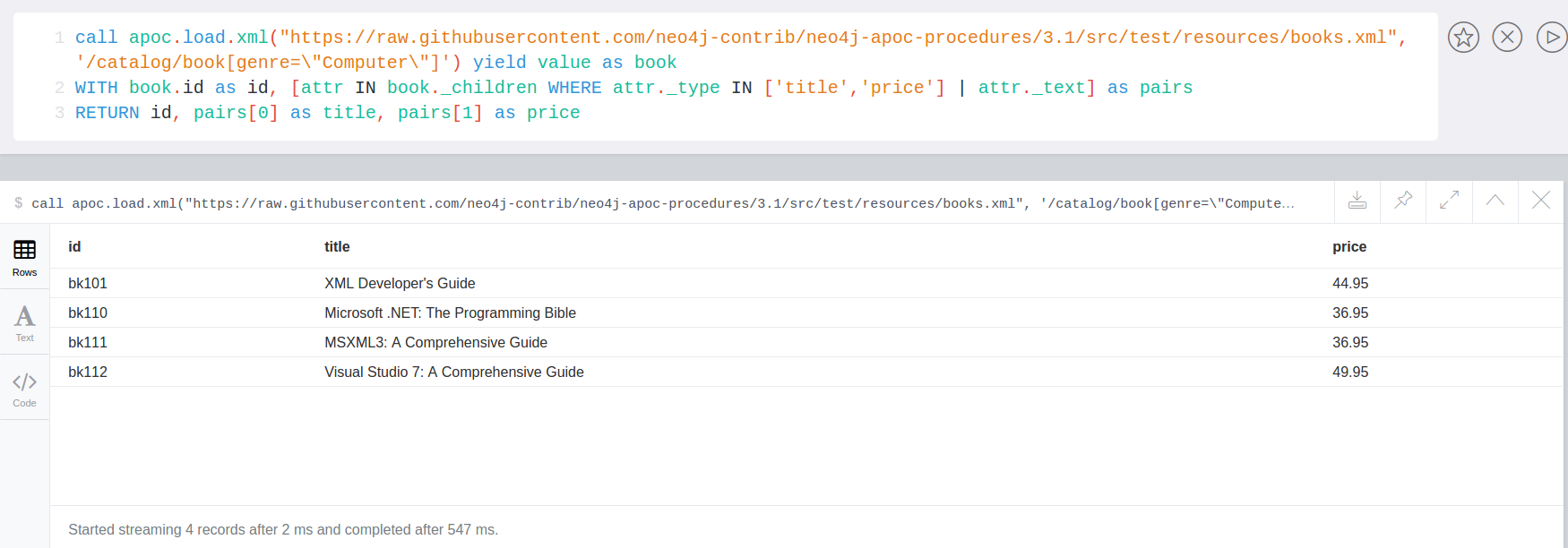
In this case we return only id, title and prize but we can return any other elements
We can also return just a single specific element.
For example the author of the book with id = bg102
call apoc.load.xml('https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml', '/catalog/book[@id="bk102"]/author') yield value as result
WITH result._text as author
RETURN author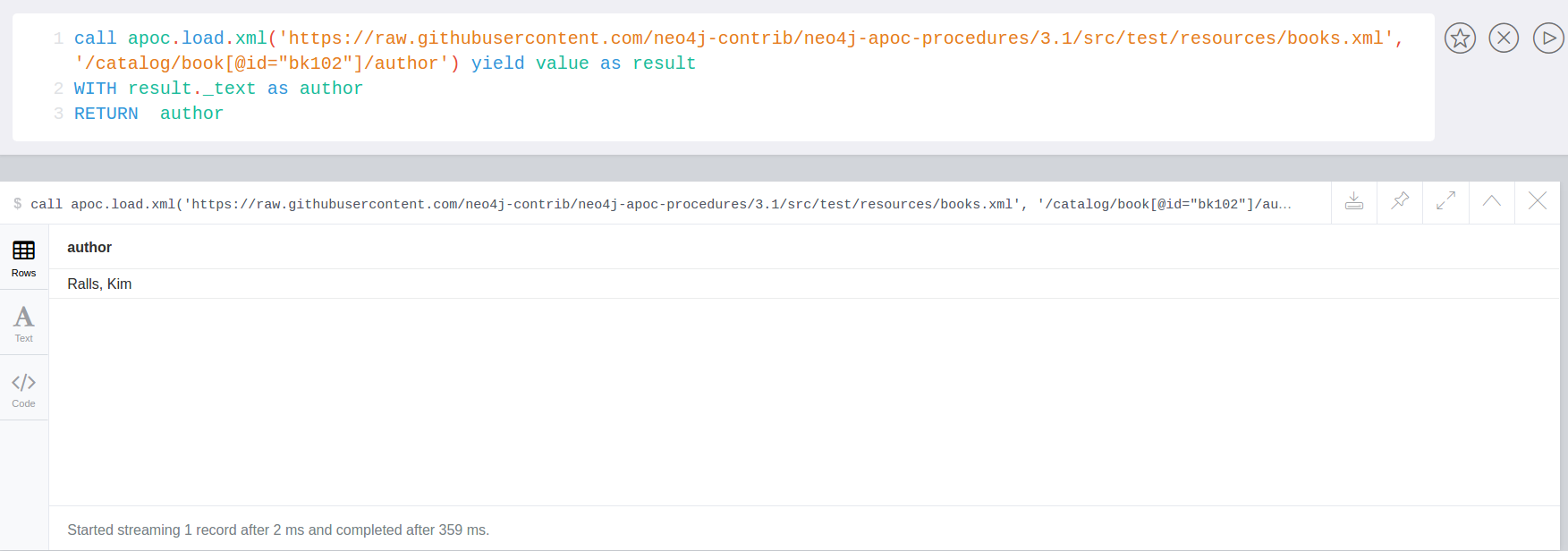
Let’s just load it and see what it looks like.
It’s returned as value map with nested _type and _children fields, per group of elements.
Attributes are turned into map-entries.
And each element into their own little map with _type, attributes and _children if applicable.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml"){_type: catalog, _children: [
{_type: book, id: bk101, _children: [
{_type: author, _text: Gambardella, Matthew},
{_type: title, _text: XML Developer's Guide},
{_type: genre, _text: Computer},
{_type: price, _text: 44.95},
{_type: publish_date, _text: 2000-10-01},
{_type: description, _text: An in-depth look at creating applications ....You can access attributes per element directly.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml") yield value as catalog
UNWIND catalog._children as book
RETURN book.id╒═══════╕
│book.id│
╞═══════╡
│bk101 │
├───────┤
│bk102 │You have to filter over the sub-elements in the _childrens array in this case.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml") yield value as catalog
UNWIND catalog._children as book
RETURN book.id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs╒═══════╤════════════════════════════════════════════════════════════════════════╕
│book.id│pairs │
╞═══════╪════════════════════════════════════════════════════════════════════════╡
│bk101 │[[author, Gambardella, Matthew], [title, XML Developer's Guide]] │
├───────┼────────────────────────────────────────────────────────────────────────┤
│bk102 │[[author, Ralls, Kim], [title, Midnight Rain]] │This is not too nice, we could also just have returned the values and then grabbed them out of the list, but that relies on element-order.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | attr._text] as pairs
RETURN id, pairs[0] as author, pairs[1] as title╒═════╤════════════════════╤══════════════════════════════╕
│id │author │title │
╞═════╪════════════════════╪══════════════════════════════╡
│bk101│Gambardella, Matthew│XML Developer's Guide │
├─────┼────────────────────┼──────────────────────────────┤
│bk102│Ralls, Kim │Midnight Rain │So better is to turn them into a map with apoc.map.fromPairs
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs
CALL apoc.map.fromPairs(pairs) yield value
RETURN id, value╒═════╤════════════════════════════════════════════════════════════════════╕
│id │value │
╞═════╪════════════════════════════════════════════════════════════════════╡
│bk101│{author: Gambardella, Matthew, title: XML Developer's Guide} │
├─────┼────────────────────────────────────────────────────────────────────┤
│bk102│{author: Ralls, Kim, title: Midnight Rain} │
├─────┼────────────────────────────────────────────────────────────────────┤
│bk103│{author: Corets, Eva, title: Maeve Ascendant} │And now we can cleanly access the attributes from the map.
call apoc.load.xml("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml") yield value as catalog
UNWIND catalog._children as book
WITH book.id as id, [attr IN book._children WHERE attr._type IN ['author','title'] | [attr._type, attr._text]] as pairs
CALL apoc.map.fromPairs(pairs) yield value
RETURN id, value.author, value.title╒═════╤════════════════════╤══════════════════════════════╕
│id │value.author │value.title │
╞═════╪════════════════════╪══════════════════════════════╡
│bk101│Gambardella, Matthew│XML Developer's Guide │
├─────┼────────────────────┼──────────────────────────────┤
│bk102│Ralls, Kim │Midnight Rain │
├─────┼────────────────────┼──────────────────────────────┤
│bk103│Corets, Eva │Maeve Ascendant │In case you don’t want to transform your xml (like you do with apoc.load.xml/apoc.load.xmlSimple before you create nodes and relationships and you want to have a 1:1 mapping of xml into the graph you can use apoc.xml.import.
CALL apoc.xml.import(<url>, <config-map>?) YIELD nodeThe procedure will return a node representing the xml document containing nodes/rels underneath mapping to the xml structure. The following mapping rules are applied:
| xml | label | properties |
|---|---|---|
|
document |
XmlDocument |
_xmlVersion, _xmlEncoding |
|
processing instruction |
XmlProcessingInstruction |
_piData, _piTarget |
|
Element/Tag |
XmlTag |
_name |
|
Attribute |
n/a |
property in the XmlTag node |
|
Text |
XmlWord |
for each word a separate node is created |
The nodes for the xml document are connected:
| relationship type | description |
|---|---|
|
:IS_CHILD_OF |
pointing to a nested xml element |
|
:FIRST_CHILD_OF |
pointing to the first child |
|
:NEXT_SIBLING |
pointing to the next xml element on the same nesting level |
|
:NEXT |
produces a linear chain through the full document |
|
:NEXT_WORD |
only produced if config map has |
The following options are available for the config map:
| config option | default value | description |
|---|---|---|
|
connectCharacters |
false |
if |
|
filterLeadingWhitespace |
false |
if |
|
delimiter |
|
if given, split text elements with the delimiter into separate nodes |
|
label |
XmlCharacter |
label to use for text element representation |
|
relType |
|
relationship type to be used for connecting the text elements into one linked list |
|
charactersForTag |
{} |
map of tagname → string. For the given tag names an additional text element is added containing the value as |
call
apoc.xml.import("https://raw.githubusercontent.com/neo4j-contrib/neo4j-apoc-procedures/3.4/src/test/resources/xml/books.xml",{createNextWordRelationships:
true})
yield node
return node;
call apoc.xml.import('https://seafile.rlp.net/f/6282a26504cc4f079ab9/?dl=1', {connectCharacters: true, charactersForTag:{lb:' '}, filterLeadingWhitespace: true}) yield node
return node;Config param is optional, the default value is an empty map.
|
|
Default: UTF-8 |
|
|
Default: "", it is use to resolve relative paths |
For these example we use the wikipedia home page "https://en.wikipedia.org/"
CALL apoc.load.html("https://en.wikipedia.org/",{metadata:"meta", h2:"h2"})You will get this result:

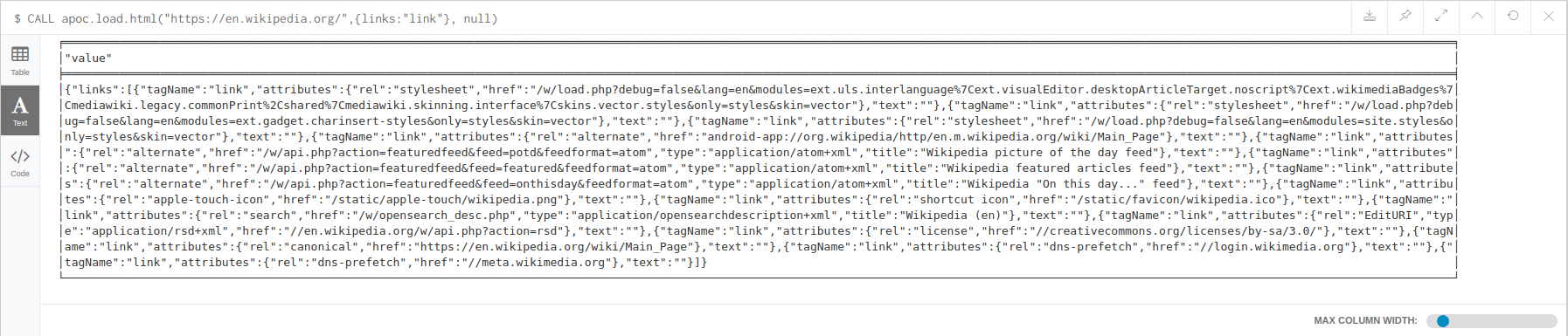
CALL apoc.load.html("https://en.wikipedia.org/",{links:"link"})You will get this result:
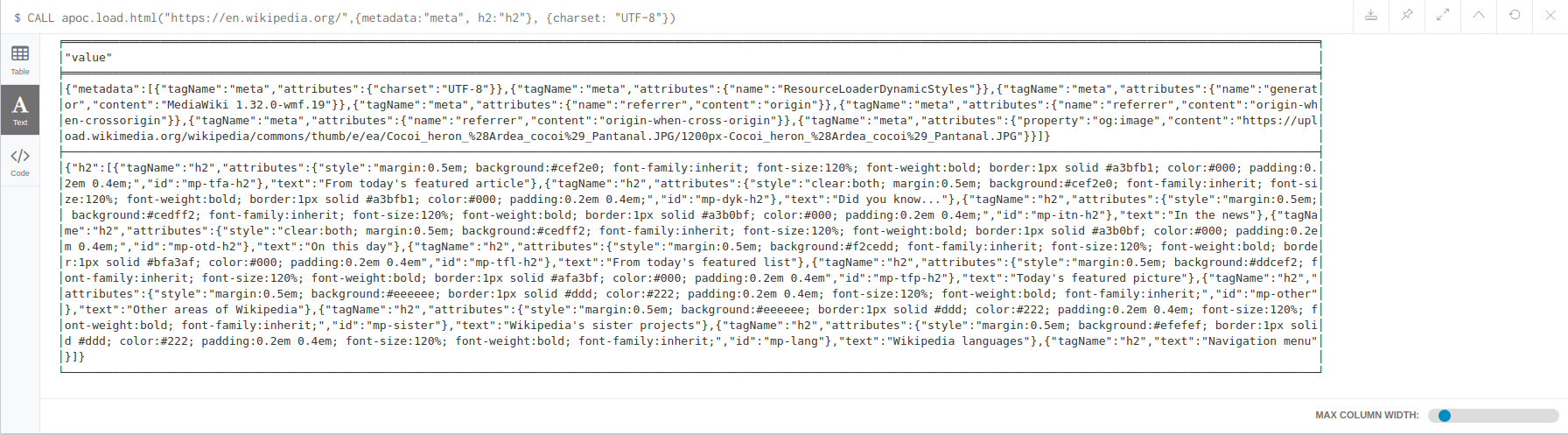
CALL apoc.load.html("https://en.wikipedia.org/",{metadata:"meta", h2:"h2"}, {charset: "UTF-8})You will get this result:
You can export your graph as an unweighted network.
match path = (:Person)-[:ACTED_IN]->(:Movie)
WITH path LIMIT 1000
with collect(path) as paths
call apoc.gephi.add(null,'workspace0', paths) yield nodes, relationships, time
return nodes, relationships, timeYou can export your graph as a weighted network, by specifying the property of a relationship, that holds the weight value.
match path = (:Person)-[r:ACTED_IN]->(:Movie) where exists r.weightproperty
WITH path LIMIT 1000
with collect(path) as paths
call apoc.gephi.add(null,'workspace0', paths, 'weightproperty') yield nodes, relationships, time
return nodes, relationships, timeYou can also export with your graph other properties of your nodes and/or relationship by adding an optional array with the
property names you want to export.
Example for exporting birthYear and role property.
match path = (:Person)-[r:ACTED_IN]->(:Movie) where exists r.weightproperty
WITH path LIMIT 1000
with collect(path) as paths
call apoc.gephi.add(null,'workspace0', paths, 'weightproperty',['birthYear', 'role']) yield nodes, relationships, time
return nodes, relationships, timeWe send all nodes and relationships of the passed in data convert into individual Gephi-Streaming JSON fragements, separated
by \r\n.
{"an":{"123":{"TYPE":"Person:Actor","label":"Tom Hanks", x:333,y:222,r:0.1,g:0.3,b:0.5}}}\r\n
{"an":{"345":{"TYPE":"Movie","label":"Forrest Gump", x:234,y:122,r:0.2,g:0.2,b:0.7}}}\r\n
{"ae":{"3344":{"TYPE":"ACTED_IN","label":"Tom Hanks",source:"123",target:"345","directed":true,"weight":1.0,r:0.1,g:0.3,b:0.5}}}Gephi doesn’t render the graph data unless you also provide x,y coordinates in the payload, so we just send random ones within a 1000x1000 grid.
We also generate colors per label combination and relationship-type, both of which are also transferred as TYPE property.
You can have your weight property stored as a number (integer,float) or a string. If the weight property is invalid or null, it will use the default 1.0 value.
For load file from compressed file the url right syntax is:
apoc.load.csv("pathToFile!csv/fileName.csv")apoc.load.json("https://github.com/neo4j-contrib/neo4j-apoc-procedures/tree/3.4/src/test/resources/testload.tgz?raw=true!person.json");You have to put the ! character before the filename.
For using S3 protocol you have to copy these jars into the plugins directory:
- aws-java-sdk-core-1.11.250.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-core/1.11.250)
- aws-java-sdk-s3-1.11.250.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3/1.11.250)
- httpclient-4.4.8.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient/4.5.4)
- httpcore-4.5.4.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore/4.4.8)
- joda-time-2.9.9.jar (https://mvnrepository.com/artifact/joda-time/joda-time/2.9.9)
S3 Url must be:
- s3://accessKey:secretKey@endpoint:port/bucket/key or
- s3://endpoint:port/bucket/key?accessKey=accessKey&secretKey=secretKey
Adding on config the parameter failOnError:false (by default true), in case of error the procedure don’t fail but just return zero rows.