Web APIs are a huge opportunity to access and integrate data from any sources with your graph. Most of them provide the data as JSON.
With apoc.load.json you can retrieve data from URLs and turn it into map value(s) for Cypher to consume.
Cypher is pretty good at deconstructing nested documents with dot syntax, slices, UNWIND etc. so it is easy to turn nested data into graphs.
Sources with multiple JSON objects (JSONL,JSON Lines) in a stream are also supported, like the streaming Twitter format or the Yelp Kaggle dataset.
Most of the apoc.load.json and apoc.convert.*Json procedures and functions now accept a json-path as last argument.
The json-path uses the Java implementation by Jayway of Stefan Gössners JSON-Path
Here is some syntax, there are more examples at the links above.
$.store.book[0].title
| Operator | Description |
|---|---|
|
|
The root element to query. This starts all path expressions. |
|
|
The current node being processed by a filter predicate. |
|
|
Wildcard. Available anywhere a name or numeric are required. |
|
|
Deep scan. Available anywhere a name is required. |
|
|
Dot-notated child |
|
|
Bracket-notated child or children |
|
|
Array index or indexes |
|
|
Array slice operator |
|
|
Filter expression. Expression must evaluate to a boolean value. |
If used, this path is applied to the json and can be used to extract sub-documents and -values before handing the result to Cypher, resulting in shorter statements with complex nested JSON.
There is also a direct apoc.json.path(json,path) function.
To simplify the JSON URL syntax, you can configure aliases in conf/neo4j.conf:
apoc.json.myJson.url=https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_UxlfCALL apoc.load.json('https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf')
becomes
CALL apoc.load.json('myJson')The 3rd value in the apoc.json.<alias>.url= effectively defines an alias to be used in apoc.load.json('<alias>',….
There have been articles before about loading JSON from Web-APIs like StackOverflow.
With apoc.load.json it’s now very easy to load JSON data from any file or URL.
If the result is a JSON object is returned as a singular map. Otherwise if it was an array is turned into a stream of maps.
The URL for retrieving the last questions and answers of the neo4j tag is this:
Now it can be used from within Cypher directly, let’s first introspect the data that is returned.
JSON data from StackOverflow.
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.items AS item
RETURN item.title, item.owner, item.creation_date, keys(item)
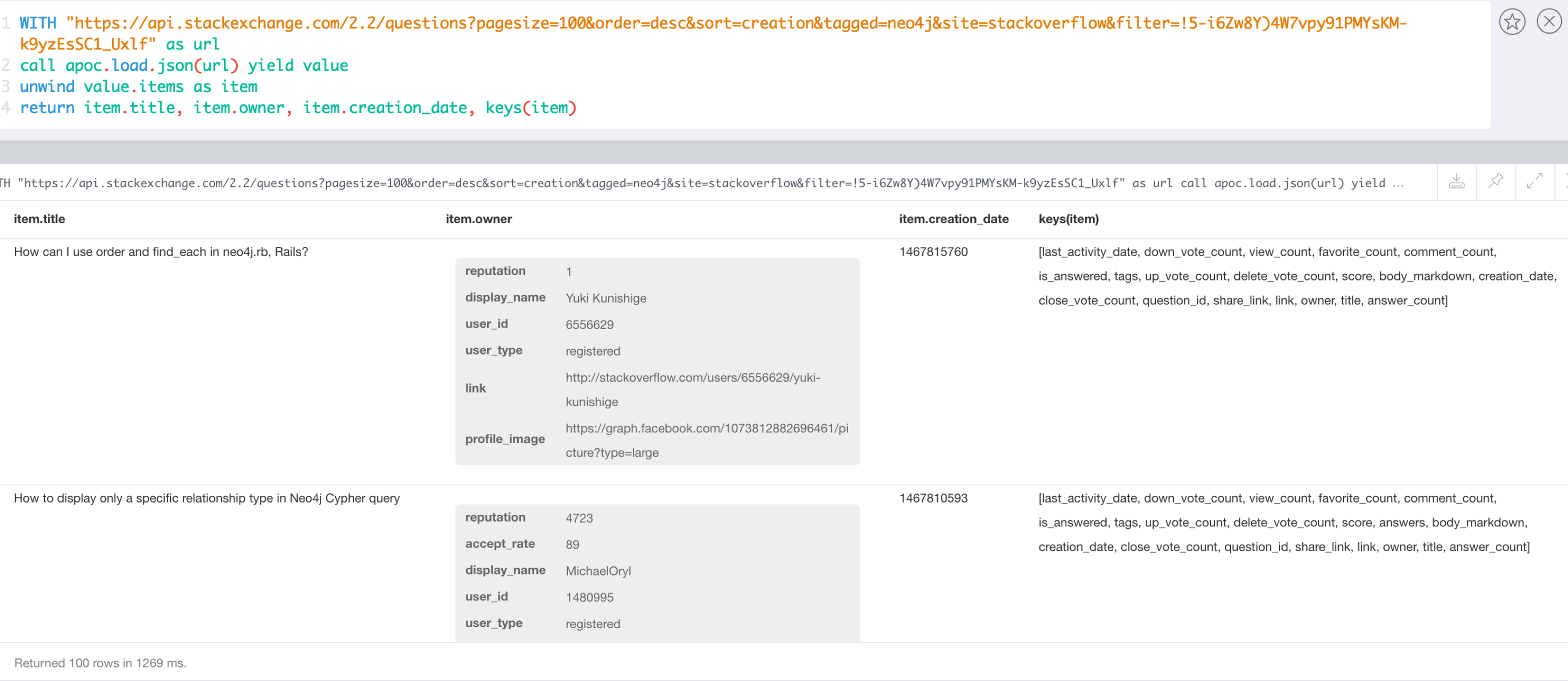
Question authors from StackOverflow using json-path.
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url,'$.items.owner.name') YIELD value
RETURN name, count(*);
Combined with the cypher query from the original blog post it’s easy to create the full Neo4j graph of those entities.
We filter the original poster last, b/c deleted users have no user_id anymore.
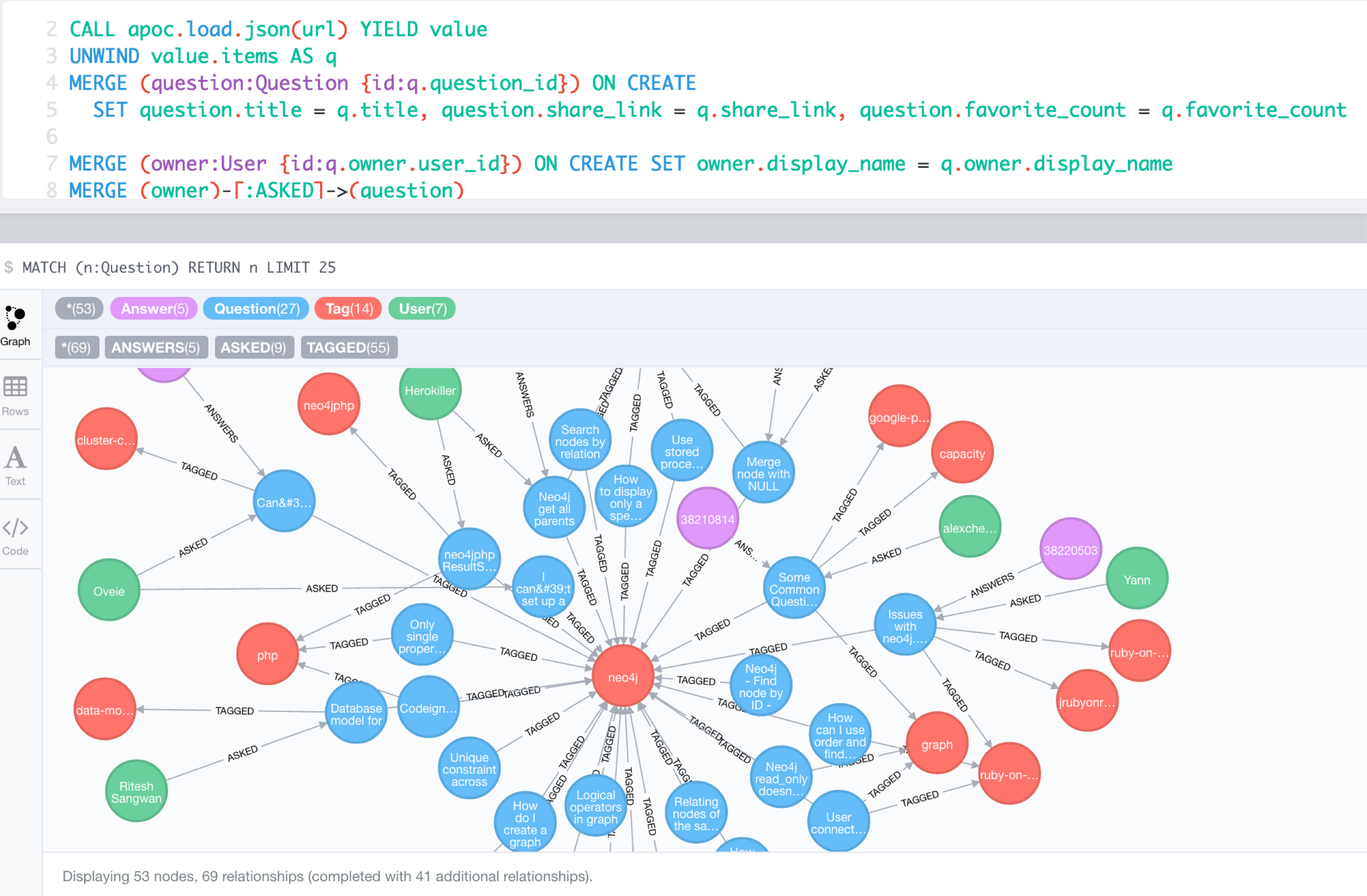
Graph data created via loading JSON from StackOverflow.
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.items AS q
MERGE (question:Question {id:q.question_id}) ON CREATE
SET question.title = q.title, question.share_link = q.share_link, question.favorite_count = q.favorite_count
FOREACH (tagName IN q.tags | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag))
FOREACH (a IN q.answers |
MERGE (question)<-[:ANSWERS]-(answer:Answer {id:a.answer_id})
MERGE (answerer:User {id:a.owner.user_id}) ON CREATE SET answerer.display_name = a.owner.display_name
MERGE (answer)<-[:PROVIDED]-(answerer)
)
WITH * WHERE NOT q.owner.user_id IS NULL
MERGE (owner:User {id:q.owner.user_id}) ON CREATE SET owner.display_name = q.owner.display_name
MERGE (owner)-[:ASKED]->(question)
With apoc.load.jsonParams you can send additional headers or payload with your JSON GET request, e.g. for the Twitter API:
Configure Bearer and Twitter Search Url token in neo4j.conf
apoc.static.twitter.bearer=XXXX
apoc.static.twitter.url=https://api.twitter.com/1.1/search/tweets.json?count=100&result_type=recent&lang=en&q=Twitter Search via Cypher.
CALL apoc.static.getAll("twitter") yield value AS twitter
CALL apoc.load.jsonParams(twitter.url + "oscon+OR+neo4j+OR+%23oscon+OR+%40neo4j",{Authorization:"Bearer "+twitter.bearer},null) yield value
UNWIND value.statuses as status
WITH status, status.user as u, status.entities as e
RETURN status.id, status.text, u.screen_name, [t IN e.hashtags | t.text] as tags, e.symbols, [m IN e.user_mentions | m.screen_name] as mentions, [u IN e.urls | u.expanded_url] as urls
Example for reverse geocoding and determining the route from one to another location.
WITH
"21 rue Paul Bellamy 44000 NANTES FRANCE" AS fromAddr,
"125 rue du docteur guichard 49000 ANGERS FRANCE" AS toAddr
call apoc.load.json("http://www.yournavigation.org/transport.php?url=http://nominatim.openstreetmap.org/search&format=json&q=" + replace(fromAddr, ' ', '%20')) YIELD value AS from
WITH from, toAddr LIMIT 1
call apoc.load.json("http://www.yournavigation.org/transport.php?url=http://nominatim.openstreetmap.org/search&format=json&q=" + replace(toAddr, ' ', '%20')) YIELD value AS to
CALL apoc.load.json("https://router.project-osrm.org/viaroute?instructions=true&alt=true&z=17&loc=" + from.lat + "," + from.lon + "&loc=" + to.lat + "," + to.lon ) YIELD value AS doc
UNWIND doc.route_instructions as instruction
RETURN instruction